我们正在尝试实现一种编程语言,也就是说尝试编写一个 求值器 (一种将程序“简化为值”的东西)。为了更好地处理计算机的复杂性,我们可以先在纸上理解求值的工作原理。
在深入细节之前,有必要先了解一下,求值器大致分为两种(以及它们的许多组合)。它们遵循非常不同的策略:
- 解释器:接收一个程序并 模拟其执行 。也就是说,解释器执行我们期望“运行程序”时所做的事情
- 编译器:接收一个程序并 生成另一个程序 。生成的程序必须进一步被求值
也就是说,解释器将某种语言 \(L\) 的程序映射到值:
\[\texttt{interpreter} :: \texttt{Program}_{L} \rightarrow \texttt{Value}\]
我们暂时不具体定义什么是 值 ,可以非正式地理解为用户希望看到的答案 —— 换句话说,就是一种无法或无需进一步求值的东西。与此相对的是,
\[\texttt{compiler} :: \texttt{Program}_{L} \rightarrow \texttt{Program}_{T}\]
也就是说,一个从 \(L\) 到 \(T\) 的编译器(我们使用 \(T\) 表示“目标”)接收 \(L\) 中的程序并生成 \(T\) 中的程序。我们并没有说明 \(T\) 程序必须如何求值。它可能被直接解释,或者被进一步编译。例如,可以将一个 Scheme 程序编译为 C 程序。C 程序可以直接被解释,但也很可能被编译为汇编代码。然而,我们不能无限制地继续编译:在最底层必须有某种解释器(例如,计算机的硬件)来提供答案。
需要注意的是,解释器和编译器本身是用某种语言编写的程序,它们本身也必须运行。这自然会引出一些有趣的想法和问题。
在我们的学习中,我们将主要关注解释器,但也会了解一种非常轻量级的编译器形式。解释器有以下优点:
- 简单的解释器通常比编译器更容易编写
- 调试解释器有时比调试编译器容易得多
因此,解释器提供了一种有用的“基准”实现技术,人人都能用上。编译器通常需要一整门课程来学习。
在网络上,人们常常谈论“解释型语言”和“编译型语言”。这些术语是 无意义 的。这不仅仅是一个判断,而是字面上的陈述:它们没有意义。解释和编译是用来求值程序的技术。一种 语言 (几乎)从不指定它应该如何求值。因此,每个实现者可以自由选择他们想要的策略。
举个例子,C 通常被认为是典型的“编译型语言”,而 Scheme 通常被认为是“解释型语言”。然而,C 也有(少量的)解释器;实际上,我第一次学习 C 时就用过其中一个。同样地,Scheme 有许多编译器;我第一次学习 Scheme 时也用过其中一个。Python 有多个解释器和编译器。
此外,这种看似明确的区分在实践中经常被打破。许多语言现在都有“JIT”,也就是 即时编译 (just-in-time compilation)。这意味着求值器一开始作为解释器运行。如果它发现自己一遍又一遍地解释相同的代码,它就会编译它并使用编译后的代码。何时以及如何进行这项操作是一个复杂而有趣的话题,但它清楚地表明了这种区分并不是泾渭分明的。
有些人被实现所呈现的 界面 所迷惑。许多语言提供一个读取-求值-打印循环(REPL),即一个交互式界面。解释器通常更容易实现这一点。然而,许多具有这种界面的系统在提示符处接受代码,编译它,运行它,并将结果呈现给用户;它们掩盖了所有这些步骤。因此,界面并不能表明你看到的是哪种实现类型。也许将一个 实现 称为“交互式”或“非交互式”比较有意义,但这并不能反映底层语言的特性。
简而言之,请记住:
- (大多数)语言并不规定实现方式。不同的平台和其他考虑因素决定了使用哪种实现
- 实现通常使用两种主要策略之一 —— 解释和编译 —— 但许多实现也是它们的混合体
- 一个特定的实现可能提供交互式或非交互式界面。然而,这并不能自动揭示底层的实现策略
- 因此,“解释型语言”和“编译型语言”这两个术语是无意义的
既然我们决定编写一个解释器,那么在开始研究如何实现它之前,让我们先了解我们希望它做 什么 。
让我们考虑以下程序:
(define (f x) (+ x 1))
(f 2)
它会产生什么?我们都可以猜到它会产生 3 。现在假设有人问我们, 为什么 它会产生 3 ?你会怎么回答?
很有可能你会说,因为在函数 f 的主体中, x 被替换成了 2 ,然后我们计算主体,得到的结果就是答案:
(f 2)
→ (+ x 1) where x is replaced by 2
→ (+ 2 1)
→ 3这些程序是用 Racket 编写的。你可以将这些程序放入 DrRacket 中,在初级学生语言级别(如 Beginning Student)下运行,并使用菜单栏中的 Step 按钮一步一步地观察它们的运行过程:

现在让我们看看程序的扩展版本:
;; f is the same as before
(define (g z)
(f (+ z 4)))
(g 5)我们可以使用相同的过程:
(g 5)
→ (f (+ z 4)) where z is replaced by 5
→ (f (+ 5 4))
→ (f 9)
→ (+ x 1) where x is replaced by 9
→ (+ 9 1)
→ 10术语 :我们称函数头中的变量为形式参数( formal parameters ),而函数调用中的表达式为实际参数( actual parameters )。因此,在函数
f中,x是形式参数,而9是实际参数。有些人也用 argument 代替 parameter ,但这些术语之间并没有真正的区别。
请注意,我们有一个选择:我们可以
→ (f (+ 5 4))
→ (f 9)或者
→ (f (+ 5 4))
→ (+ x 1) where x is replaced by (+ 5 4)目前,这两种方法都会产生相同的 答案 ,但这实际上是一个非常重要的决定!这实际上是编程语言设计中最深远的选择之一。
术语 :前一种选择被称为及时求值( eager evaluation):可以理解为在开始函数调用前“急切地”将实际参数简化为一个值。后一种选择称为惰性求值( lazy evaluation):可以理解为不急于进行求值。
SMoL 是及时求值的。对此有充分的理由,我们将在稍后探讨[👉](译注:原书的 Laziness 一章)。
好的,回到求值上。让我们再做一步:
;; f is the same as before
;; g is the same as before
(define (h z w)
(+ (g z) (g w)))
(h 6 7)我们再来看看这些步骤:
(h 6 7)
→ (+ (g z) (g w)) where z is replaced by 6 and w is replaced by 7
→ (+ (g 6) (g 7))
→ (+ (f (+ y 4)) (g 7)) where y is replaced by 6
→ (+ (f (+ 6 4)) (g 7))
→ (+ (f 10) (g 7))
→ (+ (+ x 1) (g 7)) where x is replaced by 10
→ (+ (+ 10 1) (g 7))
→ (+ 11 (g 7))
→ (+ 11 (f (+ y 4))) where y is replaced by 7
→ (+ 11 (f (+ 7 4)))
→ (+ 11 (f 11))
→ (+ 11 (+ x 1)) where x is replaced by 11
→ (+ 11 (+ 11 1))
→ (+ 11 12)
→ 23请注意,我们再次有一些选择:
- 我们是同时替换两个调用,还是一次替换一个?
- 如果是后者,我们是先替换左边的还是右边的?
语言也必须对这些问题做出决定!在上面的例子中,我们使用了 SMoL 的做法:先完成一个调用,然后再开始另一个调用,这使得 SMoL 是 顺序 执行的。如果我们同时替换两个调用,我们将探索一种 并行 语言。传统上,大多数语言选择从左到右的顺序,因此这也是我们在 SMoL 中选择的方式。
顺便说一下,你不需要任何计算机编程知识就能回答这些问题。你在中学和高中的代数课上做过类似的事情。你可能学过“替换”这个词。这就是我们在这里遵循的过程。实际上,我们可以认为编程是代数的自然延伸,只不过使用了更多有趣的数据类型:不仅有数字,还有字符串、图像、列表、表格、向量字段、视频等等。
好的,这为我们提供了一种实现求值器的方法:
- 找到一种表示程序源代码的方法(例如,一个字符串或一棵树)
- 寻找下一个需要求值的表达式
- 执行(文本)替换以获得一个新程序
- 继续求值,直到只剩下一个值
然而,正如你可能猜到的那样,大多数编程语言 实际上 并不是这样工作的:通常这样做会非常慢。所以我们必须找到更好的方法!
让我们开始考虑实际编写一个求值器。我们将从一个简单的算术语言开始,然后在此基础上逐步扩展。因此,我们的语言将包含:
- 数字
- 一些算术运算:实际上只有加法
暂时不包含其他内容,这样我们可以专注于基础知识。随着时间的推移,我们将逐步扩展这个语言。
然而,在考虑求值器的主体之前,我们需要确定它的类型:特别是,它将接收什么作为输入?
求值器接收什么作为输入呢?它接收 程序 。因此,我们需要确定如何 表示程序 。
当然,计算机一直在表示程序。当我们编写代码时,我们的文本编辑器保存了程序源代码。磁盘和内存中的每个可执行文件都是程序的表示。当我们访问一个网页时,它会发送一个 JavaScript 程序。这些都是计算机中表示的程序。但这些对于我们的需求来说都有些不方便,我们很快会想出一个更好的表示方法。
在考虑表示方法之前,让我们先思考一下我们要表示的内容。以下是一些示例(算术)程序:
1
0
-1
2.3
1 + 2
3 + 4
我们已经有一个问题了。我们应该 如何 编写我们的程序?你可以看到问题的方向:我们应该将 1 和 2 的和写作
1 + 2还是
(+ 1 2)
+ 1 2
1 2 +等等。(就此而言,我们甚至可以问应该使用什么数字系统来表示基本数字:例如,我们应该写成 3 还是 III?如果你真的愿意,也可以用后者进行编程。)
这些问题涉及使用什么 表面语法 。这些问题非常重要!而且有趣!而且确实重要!人们往往对某些表面语法非常依恋(你可能已经对 Racket 的括号语法有些感觉……我肯定是有的)。你甚至可以在

Scratch 和 Snap! 中编写那个表达式,这种语法对于让小孩子学习编程而无需面对文本语法的种种变化是非常宝贵的。
因此,这些是很好的关于人类因素的考虑。但在理解语言底层 模型 方面,这些东西只会带来干扰。因此,我们需要一种方式来表示所有这些不同的程序,而忽略这些表面上的区别。
这引出了 SImPl (标准实现计划)的第一部分:创建所谓的 抽象语法 。在抽象语法中,我们表示输入的本质,忽略表面上的语法细节。因此,在抽象语法中,所有上述程序将具有完全相同的表示。
抽象语法是程序在计算机中的一种表示。有很多种数据可以用来表示程序,所以让我们思考一下我们可能想要表示的程序类型。简单起见,我们假设我们的语言只有数字和加法运算;一旦我们能处理这些,处理其他操作就会变得容易。以下是一些示例(表面语法)程序:
1
2.3
1 + 2
1 + 2 + 3
1 + 2 + 3 + 4在传统的算术符号中,我们当然需要考虑运算顺序以及哪些运算优先于其他运算。在抽象语法中,这是我们想要忽略的另一个细节;我们假设我们内部处理的是等同于全括号表达式的形式,其中所有这些问题都已解决。因此,上面的最后两个表达式可以写成如下形式:
(1 + 2) + 3 or 1 + (2 + 3)
1 + ((2 + 3) + 4)请注意,加法运算的每一侧都可以是一个完整的表达式。这为我们内部使用哪种表示方式提供了强有力的提示: 一棵树 。事实上,使用 抽象语法树 (AST)是如此普遍,以至于这个缩写经常在没有解释的情况下被使用;你可以在和这个主题有关的书籍、论文、博客文章等中看到它。
你很可能以前见过这个概念:它叫做句子图解( sentence diagramming ,可在维基百科进一步阅读)。例如,下面是句子“He studies linguistics at the university”的图解:
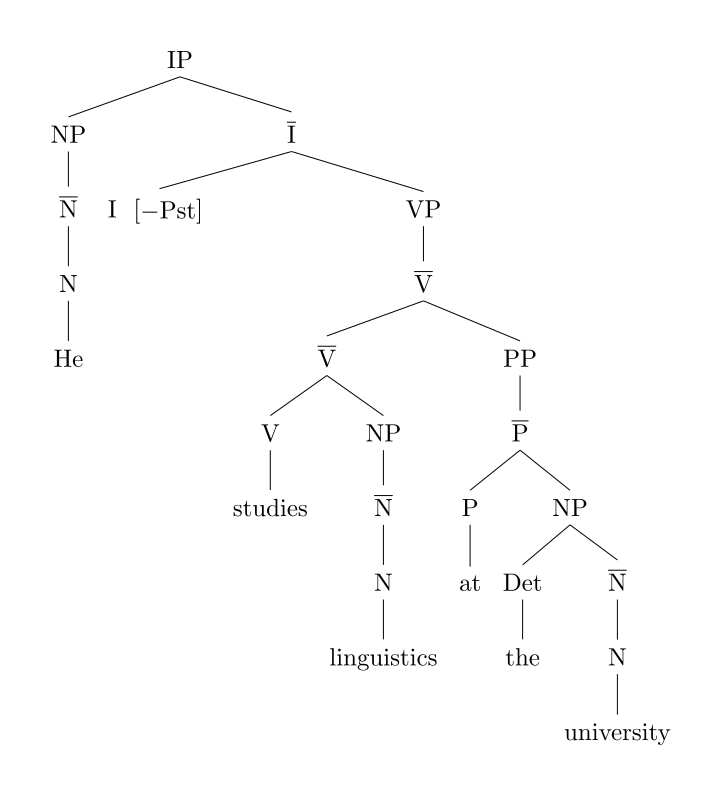
NP 是一个名词短语(Noun Phrase),V 是一个动词,等等。请注意,句子图解是如何将一个 线性 的句子转换成表示语法结构的 树形 表示的。我们也想对程序做同样的事情。
在本书的余下部分,除非另有说明,我们将使用 Racket 的 plait 语言来实现内容。请确保你已经安装了 plait 以便跟随学习。
我们将在 plait 中创建一个新的树数据类型来表示 AST。在上面的句子图解中,树的叶子是单词,节点是语法术语。在我们的 AST 中,叶子将是数字,而节点将是表示每个子表达式的树上的操作。目前,我们只有一个操作:加法。以下是在 plait 语法中表示这一点的方法:
(define-type Exp
[num (n : Number)]
[plus (left : Exp) (right : Exp)])这表示:
- 我们正在定义一个新类型,
Exp - 有两种方式创建一个
Exp - 一种方式是通过构造函数
num:num需要一个参数- 该参数必须是一个实际的数字
- 另一种方式是通过构造函数
plus:plus需要两个参数- 两个参数都必须是
Exp
如果使用 OOP 语言的解释对你有所帮助,那么这非常类似于以下的 Java 伪代码框架(或 Python 数据类的类似实现):
abstract class Exp {}
class num extends Exp {
num(Number n) { ... }
}
class plus extends Exp {
plus(Exp left, Exp right) { ... }
}让我们看看之前的一些例子是如何表示的:
| Surface Syntax | AST |
|---|---|
1 |
(num 1) |
2.3 |
(num 2.3) |
1 + 2 |
(plus (num 1) (num 2)) |
(1 + 2) + 3 |
(plus (plus (num 1) (num 2)) (num 3)) |
1 + (2 + 3) |
(plus (num 1) (plus (num 2) (num 3))) |
1 + ((2 + 3) + 4) |
(plus (num 1) (plus (plus (num 2) (num 3)) (num 4))) |
观察这些例子时请注意以下几点:
- 数据类型定义并不允许我们直接表示表面语法项,例如
1 + 2 + 3 + 4;任何歧义都必须在构建对应的 AST 项时被处理 - 数字表示看起来可能有点奇怪:我们有一个
num构造函数,其唯一作用是“包装”一个数字。我们这样做是为了表示的一致性。当我们开始编写程序来处理这些数据时,这样做的原因会变得清晰 - 请注意,表达式的每个重要部分都进入了其 AST 表示中,尽管并不总是以相同的方式。特别是,加法的
+由构造函数表示;它不是参数的一部分 AST 并不关心使用了什么表面语法。表中的最后一项可以写成:
(+ 1 (+ (+ 2 3) 4))甚至是

并且它们应该会生成相同的 AST。
简而言之,抽象语法树(AST)是在 程序中表示程序 的树状数据结构。这是一个深刻的理念!事实上,这是 20 世纪的伟大思想之一,建立在哥德尔(编码)、图灵(通用机器)、冯·诺依曼(存储程序计算机)和麦卡锡(元循环解释器)的卓越工作之上。
了解了如何表示算术程序后,我们开始编写一个将它们转换为答案的求值器程序。
这个求值器的类型是什么?显然,它接收程序,这些程序在这里由 Exp 表示。那么它产生什么呢?在这个例子中,所有这些表达式都会产生数字。因此,我们暂时将其称为计算器,简称为 calc 。因此,我们可以给 calc 定义如下类型:
(calc : (Exp -> Number))现在让我们尝试定义它的主体。显然,我们必须有:
(define (calc e)
...)
在主体中,给定一个 Exp ,我们将使用 type-case 将其分解,这告诉我们有两种选择,每种选择都有一些附加数据(这相当于我们在 Java 中使用的方法分派):
(type-case Exp e
[(num n) ...]
[(plus l r) ...])如果整个表达式已经是一个数字,会发生什么呢?既然我们已经有了答案,那就只需返回它。否则,我们必须将两边相加:
(type-case Exp e
[(num n) n]
[(plus l r) (+ l r)])这给出了完整的主体:
(define (calc e)
(type-case Exp e
[(num n) n]
[(plus l r) (+ l r)]))
让我们运行它…哎呀!我们遇到了一个类型错误!它告诉我们加法期望的是一个数字,但 l 不是一个数字:它是一个 Exp 。啊,这是因为 l 和 r 仍然表示表达式,而不是表达式求值的 结果 。为了解决这个问题,我们需要一个可以将表达式转换为数字的东西…这正是我们正在定义的!因此,我们改写为:
(define (calc e)
(type-case Exp e
[(num n) n]
[(plus l r) (+ (calc l) (calc r))]))现在类型检查器很满意了。当然,我们可以确认我们的例子产生了我们期望的结果。例如:
(calc (num 1))
产生 1 ,
(calc (plus (num 1) (num 2)))
产生 3 ,
(calc (plus (num 1)
(plus (num 2) (num 3))))
产生 6 。
上面的例子很好,但我们应该以 测试 的语法来编写这些例子,这样计算机就可以自动为我们检查它们:
(test (calc (num 1)) 1)
(test (calc (num 2.3)) 2.3)
(test (calc (plus (num 1) (num 2))) 3)
(test (calc (plus (plus (num 1) (num 2))
(num 3)))
6)
(test (calc (plus (num 1)
(plus (num 2) (num 3))))
6)
(test (calc (plus (num 1)
(plus (plus (num 2)
(num 3))
(num 4))))
10)确实,当我们运行这些测试时,Racket 确认所有这些测试都通过了。
专家提示 :浏览所有这些测试输出以查看是否有任何测试失败可能会变得烦人。只需在测试之前添加:
(print-only-errors #true)这样 Racket 就会省略测试通过的报告,你可以专注于那些失败的测试。换句话说,没有消息就是好消息。
一般来说,要尽早、频繁且全面地进行测试。编程语言的求值器将我们的思想转换为计算机的动作。因此,准确地进行测试至关重要。这也是为什么编程语言的实现是你能想象到的最被广泛测试的软件之一(你上次被语言实现中的错误阻止是什么时候?)。人们对其他软件中的错误或许能容忍,对语言实现中的错误则要严苛得多。
尝试以下测试:
(test (calc (plus (num 0.1) (num 0.2))) 0.3)它成功了!我们满意吗?假设我们改写为:
(test (calc (plus (num 0.1) (num 0.2))) 1/3)
如预期的那样,它失败了:但错误消息显示左侧的计算结果是 0.30000000000000004。这提示我们实际上得到了浮点数加法。这是因为 plait 将带小数点的数字(如 0.1 )视为浮点数位串( floating point bitstrings )。然而,浮点数位串不能精确表示数字 0.3 。实际上,plait 的 test 允许一定的数值误差,因此上述通过的测试是有效的。(这是因为在 plait 中, 0.3 确实精确表示数字 0.3 ,因为它是字面写出来的而不是浮点运算的结果。)
这强化了我们上面顺便提到的一点,因此很容易被忽视:通过采用 plait 的原语,我们也继承了它的语义。这可能是我们想要的,也可能不是!因此,在使用宿主语言编写求值器时,我们必须确保它的语义是我们所期望的,否则可能会遇到不愉快的惊喜。如果我们想要不同的行为,就必须明确地实现它。
这就结束了我们对 SImPl 的首次探索:我们在一个程序中 表示 了另一个程序,并在程序中 处理 了这个表示的程序。我们刚刚编写了第一个处理程序的程序 —— 现在我们要大展拳脚了!
之前我们已经介绍了 SImPl 的基本步骤,但我们留下了一个重要问题:如何将程序转换为 AST 表示?当然,最简单的方法就是我们已经做过的:直接编写 AST 构造函数,例如:
(num 1)
(plus (num 1) (num 2))
(plus (num 1)
(plus (num 2) (num 3)))正如我们指出的,这种方法的优点在于忽略了程序源代码的具体书写方式。
然而,这可能会变得非常繁琐。例如,我们不希望每次想写一个数字时都必须写 (num ...) !特别是,越是繁琐,我们就越不可能编写大量或复杂的测试,这将尤其不幸。因此,我们希望有一种更方便的表面语法,以及一个将其转换为 AST 的程序。
正如我们已经看到的,有很多种表面语法可以使用,我们甚至不局限于文本语法:它可以是图形的;口头的;手势的(想象你在虚拟现实环境中);等等。正如我们所指出的,这种广泛的模式是重要的 —— 尤其是在程序员有身体限制的情况下 —— 但这超出了我们当前研究的范围。即使是文本语法,我们也必须处理诸如歧义(例如,算术运算的顺序)之类的问题。
一般来说,将输入语法转换为 AST 的过程称为解析( parsing )。我们可以写一本关于解析的完整手册…但我们不会这样做。相反,我们将选择一种在便利和简单上达到合理平衡的语法,也就是 Racket 的括号语法,并在 plait 中得到特别支持。也就是说,我们将上面的例子写成:
1
(+ 1 2)
(+ 1 (+ 2 3))
并看看 Racket 如何帮助我们使这些工作变得方便。事实上,在本书中,我们将遵循一个惯例(Racket 不在乎,因为它将 () 、 [] 和 {} 视为可以互换):我们将编写使用 {} 表示的程序来代替 () 。因此,上述三个程序变成:
1
{+ 1 2}
{+ 1 {+ 2 3}}
这种语法有一个名字:它们被叫做 s-表达式( s- 是由于历史原因)。在 plait 中,我们将这些表达式前加上一个反引号( ` )。反引号后跟一个 Racket 表达式项( `exp )的类型是 S-Exp 。以下是一些 s-表达式例子:
`1
`2.3
`-40这些是数值 s-表达式,我们也可以这样写
`{+ 1 2}
`{+ 1 {+ 2 3}}这可能并不明显,但这些实际上是列表 s-表达式。我们可以通过以下方式判断:
> (s-exp-list? `1) ; Boolean
#f
> (s-exp-list? `{+ 1 2}) ; Boolean
#t
> (s-exp-list? `{+ 1 {+ 2 3}}) ; Boolean
#t所以,第一个不是列表,但后两个是;类似地
> (s-exp-number? `1) ; Boolean
#t
> (s-exp-number? `{+ 1 {+ 2 3}}) ; Boolean
#f
S-Exp 类型是实际数字或列表的容器,我们可以提取它们:
> (s-exp->number `1)
- Number
1
> (s-exp->list `{+ 1 2})
- (Listof S-Exp)
(list `+ `1 `2)
试一试 :如果你将 s-exp->number 应用于一个列表 s-表达式,或者将 s-exp->list 应用于一个数字 s-表达式,会发生什么?或者将它们应用于根本不是 s-表达式的东西?现在试试看,找出答案!你得到的结果是否有所不同?
让我们更仔细地看一下上面的最后一个输出。结果列表中有三个元素,其中两个是数字,但第三个是其他东西:
`+这是一个 符号 s-表达式。符号类似于字符串,但在操作和性能上有所不同。虽然有很多字符串操作(例如子字符串),符号被视为原子的;除了可以转换为字符串,它们唯一支持的操作是相等性检查。而作为回报,符号可以在 常数 时间内检查相等性。
符号的语法与 Racket 变量相同,因此非常适合表示类似变量的东西。因此:
> (s-exp-symbol? `+) ; Boolean
#t
> (s-exp->symbol `+) ; Symbol
'+
这个输出显示了符号在 Racket 中的写法:使用单引号( ' )。
还有其他类型的 s-表达式,但这些对现在来说已经足够了!有了这些,我们就可以编写我们的第一个解析器了!
试一试 :思考我们的 parser 需要什么样的类型
我们的解析器需要生成什么?解析器需要生成计算器消耗的东西,即 Expr 。我们的解析器需要消耗什么?它接收用“方便”语法编写的程序源表达式,即 S-Exp 。因此,解析器的类型必须是:
(parse : (S-Exp -> Exp))也就是说,它将对人类友好的语法转换为计算机的内部表示。
编写这个函数需要一定程度的严谨性。首先,我们需要一个条件语句来检查给定的 s-exp 类型:
(define (parse s)
(cond
[(s-exp-number? s) ...]
[(s-exp-list? s) ...]))
如果它是一个数字 s-exp,那么我们需要提取数字并将其传递给 num 构造函数:
(num (s-exp->number s))如果不是,我们需要提取列表并检查列表中的第一个元素是否是加法符号。如果不是,我们发出一个错误信号:
(let ([l (s-exp->list s)])
(if (symbol=? '+
(s-exp->symbol (first l)))
...
(error 'parse "list not an addition")))如果列表正确,我们通过递归处理两个子部分来创建一个加法术语:
(plus (parse (second l))
(parse (third l)))将所有部分结合起来:
(define (parse s)
(cond
[(s-exp-number? s)
(num (s-exp->number s))]
[(s-exp-list? s)
(let ([l (s-exp->list s)])
(if (symbol=? '+
(s-exp->symbol (first l)))
(plus (parse (second l))
(parse (third l)))
(error 'parse "list not an addition")))]))虽然有点复杂,但幸运的是,这已经是本书中解析过程的最复杂部分了!从现在开始,你看到的一切基本上都会遵循同样的模式,你可以随意复制。
当然,我们应该确保对解析器进行充分的测试。例如:
(test (parse `1) (num 1))
(test (parse `2.3) (num 2.3))
(test (parse `{+ 1 2}) (plus (num 1) (num 2)))
(test (parse `{+ 1
{+ {+ 2 3}
4}})
(plus (num 1)
(plus (plus (num 2)
(num 3))
(num 4))))试一试 :是否还有其他类型的测试我们应该编写?
我们只编写了 正向测试 。我们还可以编写 反向测试 ,针对我们期望出错的情况:
(test/exn (parse `{1 + 2}) "")
test/exn 需要一个字符串作为错误消息的子字符串。你可能会对上面的测试使用空字符串而不是例如“addition”感到惊讶。试试这个例子来研究原因。你能如何改进解析器以解决这个问题?
我们还应该检查其他情况,包括子部分太少或太多。例如,加法被定义为恰好接受两个子表达式。如果源程序包含零个、一个、三个、四个、…会怎样?这就是解析所需的细致性。
一旦我们考虑了这些情况,我们就可以放心了,因为 parse 生成的输出可以被 calc 处理。因此,我们可以将这两个函数组合起来!更好的是,我们可以编写一个辅助函数来为我们完成这个工作:
(: run (S-Exp -> Number))
(define (run s)
(calc (parse s)))这样,我们就可以用更方便的方式重写我们的旧求值器测试:
(test (run `1) 1)
(test (run `2.3) 2.3)
(test (run `{+ 1 2}) 3)
(test (run `{+ {+ 1 2} 3})
6)
(test (run `{+ 1 {+ 2 3}})
6)
(test (run `{+ 1 {+ {+ 2 3} 4}})
10)将这与我们之前的计算器测试进行比较!
到目前为止,我们的语言只包含算术运算。借鉴神秘语言:条件语句,我们现在将研究如何扩展我们的语言以支持条件语句。真实的编程语言中可能会有相当复杂的条件表达式,但对于我们的目的来说,一个包含三个部分的 if 语句就足够了:条件、then 分支和 else 分支。稍后,在我们学习如何扩展语言时,可以看到如何在此基础上构建更复杂的条件表达式。
在 SImPl 中,我们至少需要做两件事:
- 扩展表示表达式的数据类型以包含条件语句
- 扩展求值器以处理(表示)这些新表达式
如果我们有解析器,还可以选择:
- 扩展解析器以生成这些新表示
因为我们的条件语句固定为三个部分,我们只需要在 AST 中表示这一点。这很简单:
(define-type Exp
[num (n : Number)]
[plus (left : Exp) (right : Exp)]
[cnd (test : Exp) (then : Exp) (else : Exp)])真正的工作将发生在求值器中。
显然,添加条件语句并不会改变我们计算器之前的功能,我们可以保持原样,只需专注于处理 if 语句:
(define (calc e)
(type-case Exp e
[(num n) n]
[(plus l r) (+ (calc l) (calc r))]
[(cnd c t e) ...]))确实,我们可以递归地求值每个部分,如果它有用的话:
(define (calc e)
(type-case Exp e
[(num n) n]
[(plus l r) (+ (calc l) (calc r))]
[(cnd c t e) ... (calc c) ... (calc t) ... (calc e) ...]))让我们逐一处理这些部分。
但现在我们遇到了一个问题。调用 (calc c) 的结果是什么?我们期望它是某种布尔值。但在我们的语言中 没有 布尔值!
不仅如此。上面,我们同时写了 (calc t) 和 (calc e) 。然而,条件语句的重点是我们 不想 同时求值这两个,只需要求值其中一个。因此,我们必须根据某个标准来选择求值哪一个。
即使是最简单的条件语句也让我们面临许多语言设计的变体。其意图是首先求值测试表达式;如果结果是真值,则(仅)求值 then 表达式,否则(仅)求值 else 表达式。(我们通常将这两个部分称为 分支 ,因为程序的控制必须选择其中之一。)然而,即使是这个简单的结构也导致至少三种不同、基本独立的设计决策:
测试表达式可以是什么类型的值?在某些语言中,它们必须是布尔值(两个值,一个表示真,一个表示假)。在其他语言中,这个表达式可以求值为几乎任何值,其中一些值 —— 通常称为真值( truthy ) —— 表示真(即,它们导致 then 表达式的执行),而其余的值表示假( falsy ),意味着它们导致 else 表达式的运行。
最初,设计一种包含多个真值和假值的语言可能显得很有吸引力:毕竟,这似乎为程序员提供了更多的便利,允许在条件语句中使用非布尔值的函数和表达式。然而,这可能导致语言之间令人困惑的不一致性:
Value JavaScript Perl PHP Python Ruby -1 truthy truthy truthy truthy truthy 0 falsy falsy falsy falsy truthy "" falsy falsy falsy falsy truthy "0" truthy falsy falsy truthy truthy NaN falsy truthy truthy truthy truthy nil, null, None, undefined falsy falsy falsy falsy falsy [] truthy truthy falsy falsy truthy empty map or object truthy falsy falsy falsy truthy 当然,这并不需要如此复杂。例如,Scheme 语言只有一个假值:false 本身(写作
#false)。 每个 其他值都是真值。对于那些重视在条件语句中允许非布尔值的人来说,这代表了一种优雅的权衡:这意味着函数不必担心计算结果中的类型一致值可能导致条件语句反转。(例如,如果一个函数返回字符串,它不需要担心空字符串会与其他字符串被区别对待。)注意,部分受 Scheme 启发的 Ruby 采用了这种简单的模型。另一种受 Scheme 启发的语言 Lua,在其假值处理上也同样简洁。- 分支是什么类型的项?一些语言区分 语句 和 表达式 ;在这种语言中,设计者需要决定允许哪一种。在某些语言中,甚至有两种语法形式的条件语句来反映这两种选择:例如,在 C 语言中,
if使用语句(并且不返回任何值),而“三元运算符”((...? ... : ...))允许表达式并返回一个值。 如果分支是表达式,因此允许求值为值,这些值如何关联?许多(但不是全部)具有静态类型系统的语言期望两个分支具有相同的类型[👉](译注:原文 Growing Types: Division, Conditionals 一章的 Typing Conditional 小节)。没有静态类型系统的语言通常没有限制。
有些语言使用 truthy-falsy 值来处理部分函数。它们不会发出错误信号,而是在无法处理参数时返回一个 falsy 值。例如,在 Racket 中返回 #false 或在 Python 中返回 None 作为错误代码,并在正常执行时返回一个正确的值。考虑这个 Racket 示例:
(define (g s)
(+ 1 (or (string->number s) 0)))
这个函数接受一个可能表示数字的字符串。如果是数字,它返回比该数字大一的数;否则返回 1 :
(test (g "5") 6)
(test (g "hello") 1)
这之所以有效,是因为 string->number 返回一个数字,或者如果字符串不合法,则返回 #false 。在 Racket 中,除了 #false 之外的所有值都是 truthy 的。因此,合法字符串会短路 or 的求值,而非数字字符串会导致返回 0 。这些值在没有(或以前没有)合适的数据类型构造函数的语言中充当了简易的选项类型。
我们将在本书后面进一步讨论这个问题[👉](译注:Union Types and Retrofitted Types 一章)。
好的,我们有很多决策要做!为了首先获得一个能工作的求值器,而不需要超出数字的范围,我们可以使用一个稍微不同的条件构造:一种检查求值是否为特殊数值(比如 0 )的条件构造。也就是说,与其使用一个标准的 if ,我们实际上可以使用一个仅适用于数字的 if0 。
我们如何做出这个选择?幸运的是,我们在 plait 中编写解释器,而 plait 当然已经有了条件语句。因此,我们可以直接重用它:
(define (calc e)
(type-case Exp e
[(num n) n]
[(plus l r) (+ (calc l) (calc r))]
[(cnd c t e) (if (zero? (calc c))
(calc t)
(calc e))]))
请注意,条件语句的语义 —— 0 是真,其他所有值为假 —— 现在已经在 calc 的主体中得到了体现。如果我们想要不同的语义,那就是我们需要集中修改的程序部分。
这个解决方案,实际上到目前为止我们的整个求值器,可能让人感到有点…失望?我们确实了有数字和条件语句,但我们所做的(大部分)只是将处理这些的任务交给了 plait。以下是一些思考:
- 这是事实!
- 这并不完全正确。我们确实做出了一些有意识的决定,比如条件语句的处理
- 实际上,我们做出的决定比这还多,无论我们是否意识到这些决定,比如数字的处理。我们只是碰巧将这些交给了 plait,但如果我们愿意,我们可以做出其他决定
- 这种重用实际上是解释器的一个优势:它让你利用已经构建的特性,而不是从头开始重新实现所有这些特性
- 通过重用宿主语言(在这里是 plait),我们可以集中精力在那些不同之处(如条件语句的处理),如果我们不得不实现所有内容,这些差异可能会被忽略。稍后我们将看到与 plait 语义的更强烈的区别
好的,那么如果我们想要真正的布尔值呢?
同样,为了使用 SImPl,我们需要修改 AST、求值器和解析器。
我们可以像处理数字一样添加布尔值:使用一个构造函数来包装 plait 表示的布尔值。
(define-type Exp
[num (n : Number)]
[bool (b : Boolean)]
[plus (left : Exp) (right : Exp)]
[cnd (test : Exp) (then : Exp) (else : Exp)])
重要的是要记住 num 和 bool 构造函数代表的是什么。请回忆一下,这是 抽象语法 :我们只是(抽象地)表示 用户编写的程序 ,而不是其求值结果。因此,这些构造函数捕捉的是源程序中的语法 常量 :前者是像 3.14 和 -1 这样的值,后者是像 #true 和 #false 这样的值。它们 不 表示将 求值 为数字或布尔值的复合表达式。一个表达式将求值为何物,目前只能通过运行它来确定。稍后[👉](译注:原书 Types 部分),我们将看到还有其他方法可以做到这一点!
简单易行!这自然地暗示了我们应该在求值器中做什么:
(define (calc e)
(type-case Exp e
[(num n) n]
[(bool b) b]
[(plus l r) (+ (calc l) (calc r))]
[(cnd c t e) (if (zero? (calc c))
(calc t)
(calc e))]))哦…糟糕。这个版本的 calc 没有通过类型检查,因为我们的计算器应该只返回数字,而不是布尔值!
事实上,我们必须知道这种情况不会持续。我们不仅仅对计算器感兴趣;我们想要构建完整的编程语言。它们有各种各样的值,或者说答案:数字、布尔值、字符串、图像、函数等等。
因此,我们首先需要定义一个数据类型,反映求值器可以生成的不同类型的值。我们将遵循一个约定,将返回类型构造函数命令为为 ...V 以区别于输入。相应地,我们将输入命名为 ...E (代表表达式)以区别于输出。
首先我们重命名我们的表达式:
(define-type Exp
[numE (n : Number)]
[boolE (b : Boolean)]
[plusE (left : Exp) (right : Exp)]
[cndE (test : Exp) (then : Exp) (else : Exp)])(除了构造函数的名称外,没有任何变化。)
现在我们引入一个 Value 数据类型来表示我们的求值器可以生成的答案类型:
(define-type Value
[numV (the-number : Number)]
[boolV (the-boolean : Boolean)])我们更新求值器的类型:
(calc : (Exp -> Value))开始部分很简单:
(define (calc e)
(type-case Exp e
[(numE n) (numV n)]
[(boolE b) (boolV b)]
...))假设我们尝试使用现有代码:
[(plusE l r) (+ (calc l) (calc r))]
这有两个问题。首先,我们不能返回一个数字;我们必须返回一个 numV :
[(plusE l r) (numV (+ (calc l) (calc r)))]但现在我们遇到了一个更微妙的问题。类型检查器对这个程序不满意。为什么?
因为 calc 的结果是 Value 类型,而 + 只接受 Number 类型。实际上,类型检查器迫使我们在这里 做出决定 :如果 + 的一侧不求值为数字,会发生什么?
首先,让我们构建一个抽象来处理这个问题,以便保持解释器的核心相对干净:
[(plusE l r) (add (calc l) (calc r))]
现在我们可以将 + 的求值逻辑推迟到 add 函数中。 现在我们必须做出一个语义上的决定 。是否应该允许“加”两个布尔值?是否允许将一个数字加到布尔值或反过来呢?尽管这里没有完全标准的决定 —— 有些语言非常严格,而有些语言非常宽松 —— 最不违反常规的策略是要求两个分支都求值为数字,我们可以这样表达:
(define (add v1 v2)
(type-case Value v1
[(numV n1)
(type-case Value v2
[(numV n2) (numV (+ n1 n2))]
[else (error '+ "expects RHS to be a number")])]
[else (error '+ "expects LHS to be a number")]))
注意,这些 else 子句可以轻松地表示其他决策。我们可以在不同的选择中嵌入一整个神秘语言的家族!
练习 :为什么我们在 add 中编写了 numV 构造函数,而不是在 calc 中?
专家提示 :你刚刚添加了一段复杂的代码。现在是测试求值器的好时机。这里有两个要考虑的方面:
- 目前条件语句的代码 也 没有通过类型检查。你可能会发现用一些语义上不正确但类型正确的东西(如
(numV 0))替换整个 RHS 很方便,这样你可以恢复工作中的求值器 不要忘记测试错误情况!你可以使用
test/exn进行测试。例如:(test/exn (calc (plusE (numE 4) (boolE #false))) "RHS")
现在让我们将注意力转向条件语句(使用更新的构造函数名称):
[(cndE c t e) ...]核心逻辑显然是相似的:检查条件,并根据它只求值另外两个子句中的一个。我们再次需要做出有关如何处理条件语句的决定:我们应该严格要求布尔值,还是做出真值/假值决策?我们可以再次将其推迟到一个辅助函数:
[(cndE c t e) (if (boolean-decision (calc c))
(calc t)
(calc e))]))同样,最不违反常规的策略,同时也是为后续内容做准备的策略,是严格要求布尔值:
(define (boolean-decision v)
(type-case Value v
[(boolV b) b]
[else (error 'if "expects conditional to evaluate to a boolean")]))
但同样地,从严格解释开始,我们可以看到我们可以在哪些方面妥协以设计更宽松的语言:通过替换 else 子句。
顺便说一下,我们在处理条件语句时与处理加法时做法不同。对于 add ,我们求值了两个分支并给出它们相应的值。对条件语句这样做是个糟糕的主意,因为条件语句的核心在于不对其中一个分支求值!我们可以将分支的 AST 发送到一个辅助函数,但我们上面做的也很好:它将语义变化局限于辅助函数中,而将不应改变的内容(即条件语法导致条件求值的事实)保留在求值器的核心中。
大多数编程语言都有某种 局部绑定 的概念。这里有两个词,我们将其拆开解释:
- 绑定( Binding )是指将名称与值关联起来。例如,当我们调用一个函数时,调用的行为将形式参数与实际值关联(“绑定”)起来
- 局部( Local )意味着它们仅限于程序的某个区域,在该区域之外不可用
例如,在许多语言中我们可以写类似这样的代码:
fun f(x):
y = 2
x + y这似乎很清楚。但这是一个更微妙的程序:
fun f(x):
for (y from 0 to 10):
print(x + y)
y
这是合法的吗?这取决于 y 是否仍然“活着”或“活跃”或“可见”,或其他任何你喜欢的说法;正式地,我们会说这取决于 y 是否在 作用域 内。具体来说,我们会问最后的 y 是否是 for 循环中 绑定 的实例。
这很复杂!许多语言做了相当奇怪、复杂且确实不直观的事情,你会在神秘语言中看到这些。这些奇怪的事情实际上并不是 SMoL 的一部分;如果有的话,它们是对 SMoL 的一种违反。
问题的一部分实际上是语法的。当我们编写类似上面的程序时, y 的作用域(即 y 被绑定的区域)的开始或结束并不明确。这是括号语法的一个巨大优点:它 暗示 了一个明确的区域(括号之间)。当然,我们有责任确保变量 确实 在这个区域内绑定(尽管我们稍后会发现,这并不是那么简单)。
按照 Racket 的语法,我们将在我们的语言中添加一个新的构造。这时,跟踪完整语法变得有点棘手,所以我们将使用一种叫做 BNF(巴科斯-瑙尔范式)的记号。让我们从算术语言开始:
<expr> ::= <num>
| {+ <expr> <expr>}
它的意思是“定义( ::= ) expr 可以是一个数字,也可以是( | )包含一个左大括号( { )、一个加号( + )、一个 expr 、另一个 expr 和一个右大括号( } )组成的表面语法”。通过它的具体语法,BNF 为我们提供了一种方便的表示语言语法的记号,我们的抽象语法通常会以一种非常自然的方式直接对应 BNF。(然而请注意,在 BNF 中,我们只是简单地说每个子表达式是一个 expr ,因为这就是我们需要知道以正确形成程序的所有东西。然而,在 AST 中,我们给各部分不同的名字以区分它们。)
说明 :BNF 分为 终结符 和 非终结符 。非终结符是占位符,比如上面的 expr 和 num :它们代表更多的可能性(上面的 expr 可以替换为两种可能性中的一种(目前只有这两种),而 num 有很多可能的写法)。它们被称为非终结符,因为语法在这里不会“终结”:名称是一个占位符,可以(并且必须)进一步展开。
习惯上,将非终结符写在 <尖括号> 内。相反,终结符是具体语法,比如上面的 { , } 和 + 。之所以这样称呼它们,是因为它们代表它们自己,不能进一步展开。它们有时也被称为 字面量 ,因为它们必须像显示的那样字面书写。因此,它们不被任何装饰符号包围。除非是非终结符,否则一切都是字面书写的;如果是非终结符,则根据其定义替换为其他内容。
现在我们可以定义一个扩展语言:
<expr> ::= <num>
| {+ <expr> <expr>}
| {let1 {<var> <expr>} <expr>}
也就是说,我们添加了一个新的语言构造 let1 ,它有三部分:一个变量( var )和两个表达式(两个 expr )。
做一做 :下面是一些使用这个新构造的例子;你期望每个例子产生什么结果?
{let1 {x 1}
{+ x x}}
{let1 {x 1}
{let1 {y 2}
{+ x y}}}
{let1 {x 1}
{let1 {y 2}
{let1 {x 3}
{+ x y}}}}
{let1 {x 1}
{+ x
{let1 {x 2} x}}}
{let1 {x 1}
{+ {let1 {x 2} x}
x}}
x做一做 :哦,你注意到什么了吗?上面的所有程序在语法上都是不合法的!为什么?
这是因为还没有变量的语法。我们的语法允许我们 绑定 变量但不能使用它们。所以我们需要修正它:
<expr> ::= <num>
| {+ <expr> <expr>}
| {let1 {<var> <expr>} <expr>}
| <var>现在,上面的项在语法上都是有效的,因此我们可以回到它们应该求值为什么的问题上来。
前两个程序非常明显:
{let1 {x 1}
{+ x x}}应该求值为 2,和
{let1 {x 1}
{let1 {y 2}
{+ x y}}}应该求值为 3。
那么这个程序呢?
{let1 {x 1}
{let1 {y 2}
{let1 {x 3}
{+ x y}}}}在这里我们看到了括号符号的优势。在更常规的语法中,这可能对应于:
x = 1
y = 2
x = 3
x + y
在这种情况下,可能会发生很多事情:我们可能有两个不同的 x ;我们可能有一个 x 被绑定然后被修改;在某些语言中,引入 x 可能被“提升”,因此不再清楚哪个 x 是最新的。然而,使用括号语法时,我们很清楚我们想要什么作用域。为了确定值,我们可以依赖我们的老朋友 —— 替换。然而,当我们替换外部的 x 时,我们期望它在内部 x 开始的地方停止:也就是说,内部的 x 遮蔽 了外部的 x 。因此,结果应该是 5 。
做一做 :上面的例子不有趣,因为外部的 x 从未被使用。我们可以编写什么样的程序,使其包含两个 x 的 let 绑定,从而让我们清楚地看到有两个 x 呢?
这是这个程序展示的内容:
{let1 {x 1}
{+ x
{let1 {x 2} x}}}
很明显,加法中左边的 x 应该是 1 ,而右边表达式中的 x 应该被遮蔽,因此应该求值为 2 。因此,总和应该是 3 。顺便说一句,DrRacket 在这种情况下很有用,因为我们可以在 #lang racket 中编写等效表达式 ——
(let ([x 1])
(+ x
(let ([x 2])
x)))
—— 并悬停鼠标在最后的 x 上,DrRacket(对于 Racket,代表了相当理想的 SMoL 形式)会自动画出一条蓝色箭头,显示变量在哪里被绑定:

现在来看一个更复杂的例子:
{let1 {x 1}
{+ {let1 {x 2} x}
x}}
在这里,使用替换来确定答案特别有用。同样,很明显左边表达式中的 x 被遮蔽,因此应该是 2 。当然,最大的问题是加法右边的 x (即最后一行)应该是什么?
在这里,传统的文本语法充满了歧义:
x = 2
左边的 x 是新 x 的 绑定 还是对外部 x 的 修改 ?这两者是完全不同的事情!但使用我们的语法,很明显 应该 是前者,而不是后者。因此,通过替换,外部的 x 被替换为 1 ,结果是:
{+ {let1 {x 2} x}
1}在这里我们再进行一次替换,得到:
{+ 2
1}因此,结果是 3。这次,DrRacket 尤其有用,可以进行确认:

这只剩下一个程序:
x
由于 x 没有在任何地方绑定,这只是一个语法错误。
程序
{let1 {x 1}
{+ {let1 {x 2} x}
x}}
引入了一个非常重要的概念:实际上,这是 SMoL 背后的核心思想之一。这个概念是变量的绑定由 它在源程序中的位置 决定,而 不是 由 程序的执行顺序 决定。也就是说,无论在它求值之前发生了什么,最后一行的 x 都由同一个地方绑定 —— 因此获得相同的值。为了更好地理解这一点,让我们观察一系列的程序:
{let1 {x 1}
{+ {let1 {x 2} x}
x}}
你可能认为它产生 3 或 4 都可以。那么这个呢?
{let1 {x 1}
{+ {if true
{let1 {x 2} x}
4}
x}}你应该期望结果相同:条件语句总是为真,所以显然我们总是会求值内部的绑定,因此它的答案应该与前一个程序相同。但这个呢?
code
{let1 {x 1}
{+ {if true
4
{let1 {x 2} x}}
x}}
现在你可能不那么确定了。由于条件语句永远不会执行,你可能不希望内部的绑定产生影响。也就是说,你愿意 让程序的控制流影响绑定 。表面上看这似乎是合理的,但现在看看这个程序:
code
{let1 {x 1}
{+ {if {random}
4
{let1 {x 2} x}}
x}}
或
code
{let1 {x 1}
{+ {if {moon-is-currently-full}
4
{let1 {x 2} x}}
x}}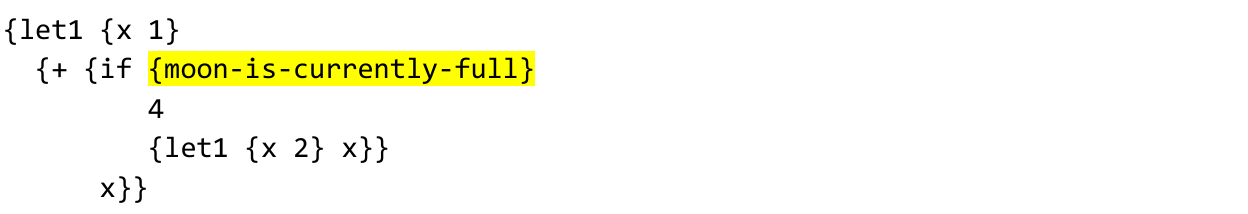
你愿意让绑定结构每两周改变一次吗?这个版本呢:
code
{let1 {x 1}
{+ {if {moon-is-currently-full}
4
{let1 {y 2} x}}
y}}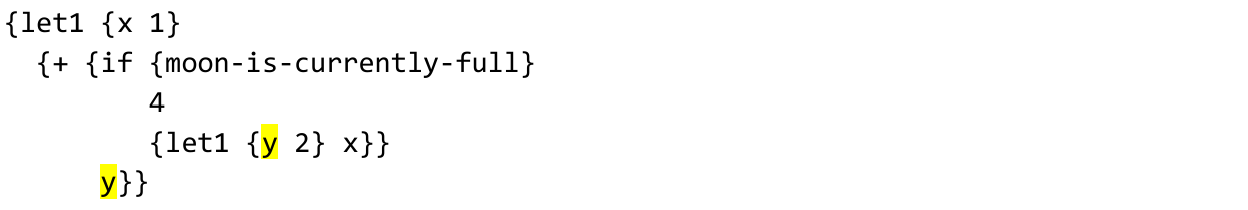
然后,根据月相,程序要么产生一个答案,要么导致未绑定变量错误。
让控制流决定绑定的决策称为动态作用域(dynamic scope)。这是编程语言设计中 毫无疑问的错误决策 。它有着漫长而不光彩的历史:最初的 Lisp 采用了它,直到十多年后 Scheme 才修正了这一点。不幸的是,不了解历史的人注定会重蹈覆辙:Python 和 JavaScript 的早期版本也采用了动态作用域。将其移除是一项艰巨的任务。动态作用域意味着:
- 我们无法确定程序的绑定结构
- 求值器也不能确定
- 编程工具也不能确定
例如,程序重构工具需要知道绑定结构:即使是简单的“变量重命名”工具也需要知道哪些变量要重命名。在 DrRacket 中,没有歧义,因此变量重命名可以正确工作。这在其他语言中并不适用:例如,参见这篇关于 Python 语义的论文附录 2。
动态作用域的对立面 —— 我们可以通过遵循 AST 的结构来确定绑定 —— 称为静态作用域(static scope)。静态作用域是 SMoL 的一个定义特征。
早期实现中出现动态作用域是因为它易于实现:这是默认行为。我们必须稍微努力一些才能获得静态作用域,正如我们将看到的那样。
既然我们已经看到了我们想要的行为,那么我们应该实现它。也就是说,我们将扩展我们的计算器以处理局部绑定(你可能一直希望你的计算器具备这个功能)。为了反映我们的计算器正在成长,从现在开始我们将称之为解释器,在代码中缩写为 interp 。
让我们从新的 AST 开始。为了简化,我们将忽略条件语句,因为它们与处理局部绑定的目标是正交的。回忆一下我们在 BNF 中添加了两个新分支,因此我们也需要在 AST 中添加两个相应的新分支:
(define-type Exp
[numE (n : Number)]
[plusE (left : Exp) (right : Exp)]
[varE (name : Symbol)]
[let1E (var : Symbol) (value : Exp) (body : Exp)])我们也可以复制之前的计算器,但我们很快会遇到麻烦:
(define (interp e env)
(type-case Exp e
[(numE n) n]
[(varE s) ...]
[(plusE l r) (+ (interp l env) (interp r env))]
[(let1E var val body) ...]))
当我们遇到 let1E 时该怎么办?更重要的是,当我们遇到一个变量时该怎么办?实际上,这两者应该紧密相关:前者引入的变量绑定应该替换后者中的变量使用。
我们反复且正确地回顾替换法来理解程序应如何工作,实际上我们以后也会这样做。但是,替换作为一种 求值 技术是很麻烦的。它要求我们不断重写程序文本,对于每个变量绑定,替换需要的时间与程序的大小成线性关系(而程序可能会变得相当大)。大多数实际的语言实现并不是这样工作的。
相反,我们可以考虑一种空间和时间的权衡:我们将使用一点额外的空间来节省大量时间。也就是说,我们将在一个名为 环境 的数据结构中 缓存 替换结果。环境记录名称及其对应的值:也就是说,它是键值对的集合。因此,每当我们遇到绑定时,我们记住它的值,当我们遇到变量时,我们查找它的值。
我们将使用哈希表来表示环境:
(define-type-alias Env (Hashof Symbol Value))
(define mt-env (hash empty)) ;; "empty environment"我们需要让解释器实际将环境作为一个形式参数,以代替替换。因此:
(interp : (Exp Env -> Value))
(define (interp e nv) ...)
当我们遇到一个变量时会发生什么?我们尝试在环境中查找它。这可能会成功,或者像上面最后一个例子那样失败。我们将使用 hash-ref ,它在哈希表中查找键,并返回一个类型为 Optionof 的值以应对可能的失败。我们可以将其封装在一个函数中,这个函数会反复使用:
(define (lookup (s : Symbol) (n : Env))
(type-case (Optionof Value) (hash-ref n s)
[(none) (error s "not bound")]
[(some v) v]))
如果查找成功,那么我们希望找到的值被包装在 some 中。这个函数使我们的解释器保持简洁和易读:
[(varE s) (lookup s nv)]
最后,我们准备处理 let1 。这里会发生什么?我们必须:
- 计算表达式的主体,在
- 已扩展的环境中,包含
- 新名字
- 绑定到它的值
幸运的是,这并不像听起来那么糟糕。同样,一个函数会大有帮助:
(extend : (Env Symbol Value -> Env))
(define (extend old-env new-name value)
(hash-set old-env new-name value))有了这个,我们可以清楚地看到结构:
[(let1E var val body)
(let ([new-env (extend nv
var
(interp val nv))])
(请注意,我们在 plait 中使用 let 来定义 Paret 中的 let1 。我们会看到更多这样的例子…)
总之,我们的核心解释器现在是:
(define (interp e nv)
(type-case Exp e
[(numE n) n]
[(varE s) (lookup s nv)]
[(plusE l r) (+ (interp l nv) (interp r nv))]
[(let1E var val body)
(let ([new-env (extend nv
var
(interp val nv))])
(interp body new-env))]))练习 :
- 如果我们没有调用上面的
(interp val nv)会发生什么? - 如果我们在调用
interp时使用nv而不是new-env会发生什么? - 基于我们之前的代码,解释器中是否还有其他错误?
- 我们似乎扩展了环境但从未从中删除任何内容。这可以吗?如果不可以,它会引发错误。哪个程序会演示这个错误,它实际上会这样做吗?(如果没有,为什么?)
这就结束了我们第一个有趣的“编程语言”。我们已经不得不处理一些相当微妙的作用域问题,以及如何解释它们。从这里开始,事情只会变得更加有趣!
既然我们已经有了算术和条件语句,让我们通过添加函数来创建一个完整的编程语言。
在将函数添加到语言中时,有很多种思考方式。例如,许多语言有顶级函数;例如:
fun f(x):
x + x确实,一些语言(如 C) 只有 顶级函数。然而,大多数现代语言具有在顶级之外编写函数的能力;例如:
fun f(x):
fun sq(y):
y * y
sq(x) + sq(x)甚至可以 返回 这些函数,并允许它们以 匿名 方式编写。既然几乎所有现代语言都支持它,我们就将其视为 SMoL 的一个组成部分。事实上,有了这样的设施,我们实际上不需要一个命名的函数构造本身:我们可以这样写:
fun f(x):
sq = lam(y): y * y
sq(x) + sq(x)
反过来我们也可以用名字绑定和 lam 替换 f 。
因此,让我们考虑将函数作为值求值到 SMoL 中需要做些什么。我们不需要函数本身有一个名称,因为可以通过 let1 来命名。为了简单起见,我们假设所有函数只接受一个参数;将其扩展到多个参数留作练习。
练习 :当我们将函数从只接受一个参数扩展到接受多个参数时,可能需要处理哪些问题?
首先,我们需要扩展我们的抽象语法。
做一做 :我们需要在抽象语法中添加多少个新构造?
当我们添加 let1 时,你可能记得添加一个构造是不够的;我们需要两个:一个用于变量绑定,另一个用于变量使用。在向语言中添加值时,你经常会看到这种模式。对于任何新类型的值,你可以预期会有一种或多种方式来创建它,并且有一种或多种方式来使用它。(即使是算术操作:数字常量是一种创建它们的方式,算术运算消耗它们 —— 但也创建它们。)
同样地,对于函数,我们需要一种方式来表示
lam(x): x * x用于定义新函数,以及
sq(3)来使用它们。
术语 :在更高级的文本中,你有时会看到(形式上正确但可能稍微令人困惑的)术语引入( introduction ) 和消除( elimination ) :引入带来了新的概念,消除使用了它们。因此,
lam引入了新函数,而应用消除了它们。
因此,我们在我们的 AST 中添加
[lamE (var : Symbol) (body : Exp)]
[appE (fun : Exp) (arg : Exp)]让我们假设我们已经扩展了我们的解析器,使得如下程序是合法的:
{let1 {f {lam x {+ x x}}}
{f 3}}
{let1 {x 3}
{let1 {f {lam y {+ x y}}}
{f 3}}}这些分别解析为
(let1E 'f (lamE 'x (plusE (varE 'x) (varE 'x)))
(appE (varE 'f) (numE 3)))
(let1E 'x (numE 3)
(let1E 'f (lamE 'y (plusE (varE 'x) (varE 'y)))
(appE (varE 'f) (numE 3))))
并且都应求值为 6 。
现在让我们考虑求值器,到了现在我们可以将其视为一个完整的解释器。
让我们从(几乎)最简单的新程序开始:
{lam x {+ x x}}它表示为
(lamE 'x (plusE (varE 'x) (varE 'x)))做一做 :我们希望这个程序求值为什么?从类型的角度思考!
记住, calc 产生数字。上述表达式求值为什么 数字 ?你 期望 它产生什么数字?
如果我们真的想测试我们的可信度,我们可以将其编码为一个数字,或在内存中使用一个数字。但这些都不是我们所期望的!让我们看看其他语言是怎么做的:
> (lambda (x) (+ x x))
#<procedure>
> (number? (lambda (x) (+ x x)))
#f>>> lambda x: x + x
<function <lambda> at 0x108fd16a8>
>>> isinstance(lambda x: x + x, numbers.Number)
False
Racket 和 Python 都一致认为:创建匿名函数的结果是一种函数类型的值,而不是一个数字。这意味着我们必须扩展 interp 可以产生的值的种类。
术语 : 副作用 是从函数体外部可见的系统变化。典型的副作用是对在函数外部定义的变量的修改、网络通信、文件修改等。
术语 :如果对于给定的输入,总是产生相同的输出,并且没有副作用,那么一个函数是 纯 的。实际上,计算总会有 一些 副作用,例如能量的消耗和热量的产生,但我们通常忽略这些副作用,因为它们是普遍存在的。然而,在某些情况下,它们可能很重要:例如,如果一个加密密钥可以通过测量这些副作用被盗取。
术语 :传统上,一些语言使用术语过程( procedure )和函数( function )来表示相似但不完全相同的概念。两者都是封装了一段代码并可以应用(或“调用”)的类函数(function-like)实体。过程是一个不产生值的封装;因此,它必须有副作用才能有用。相比之下,函数总是产生值(并且可能被期望没有任何副作用)。这些术语多年来已经完全混淆了,现在人们互换使用这些术语,但如果有人似乎在区分两者,他们可能指的是类似上述的内容。
求值一个函数时会发生什么?Racket 和 Python 都似乎表明我们返回一个函数。
我们可能没有关于该函数的额外信息:
(define-type Value
[numV (the-number : Number)]
[boolV (the-boolean : Boolean)]
[funV])
(这个语法表示 funV 是一个没有参数的构造函数。除了表示它是一个 funV 之外,它没有传达任何信息;因为我们不能混合类型,所以特别表示一个值不是数字或布尔值 —— 仅此而已。)但现在想想这样的程序(假设 x 已绑定):
{{if0 x
{lam x {+ x 1}}
{lam x {- x 2}}}
5}
在这两种情况下,我们都会得到一个没有额外信息的 funV 值,所以当我们尝试执行应用时,我们…做不到。
相反,很明显函数值需要告诉我们关于函数的信息。我们需要知道函数体,因为这是我们需要求值的内容;但函数体可以(并且很可能会)引用形式参数的名称,所以我们也需要它。因此,我们真正需要的是:
(define-type Value
[numV (the-number : Number)]
[boolV (the-boolean : Boolean)]
[funV (var : Symbol) (body : Exp)])此时,似乎我们做了很多无用功。我们将数值和布尔值重新包装在新的构造函数中,现在我们对函数也做同样的事情。某部莎士比亚戏剧的标题浮现在脑海中。
耐心点(Patience)。
通过我们已经有的东西,我们已经可以有一个能工作的解释器。 lam 情况显然非常简单:
[(lamE v b) (funV v b)]应用案例则稍微详细一些。我们需要:
- 求值函数的位置,找出它是什么类型的值
- 求值参数的位置,因为我们已经同意在 SMoL 中会发生的情况
- 检查函数位置是否真的求值为一个函数。如果不是,抛出错误
- 求值函数体。但因为函数体可以引用形式参数…
- …首先确保形式参数绑定到参数的实际值
分步骤实现如下:
code
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
...)]
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b) ...]
[else (error 'app "didn't get a function")]))]
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b)
(interp b ...)]
[else (error 'app "didn't get a function")]))]
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b)
(interp b (extend nv v av))]
[else (error 'app "didn't get a function")]))]
把所有内容整合起来,我们得到以下解释器:
(interp : (Exp Env -> Value))
(define (interp e nv)
(type-case Exp e
[(numE n) (numV n)]
[(varE s) (lookup s nv)]
[(plusE l r) (add (interp l nv) (interp r nv))]
[(lamE v b) (funV v b)]
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b)
(interp b (extend nv v av))]
[else (error 'app "didn't get a function")]))]
[(let1E var val body)
(let ([new-env (extend nv
var
(interp val nv))])
(interp body new-env))]))练习 :我们在上面写下了一个特定的顺序,并在代码中加以实践。但这与实际语言使用的顺序相同吗?特别是,非函数错误是在求值参数之后还是之前报告的?实验一下,找出答案!
由于我们已经采取了几个步骤才走到这一步,很容易忽略我们刚刚完成的事情。仅仅用了 20 行代码(加上一些辅助函数),我们描述了一个完整编程语言的实现。不仅如此,这是一个可以表达所有计算的语言。当图灵奖得主阿兰·凯(Alan Kay)第一次看到这个等效程序时,他说:
是的,这就是我在研究生院时的重大启示 —— 当我终于理解了《Lisp 1.5手册》第 13 页底部的那半页代码本身就是 Lisp 时。这些是“软件的麦克斯韦方程!”这就是整个编程世界,用几行代码就可以覆盖。
我意识到,任何时候我想知道自己在做什么,我都可以用半页纸写下这个核心,它不会失去任何力量。事实上,它会变得更强大,因为它比大多数其他系统更容易重新进入自身。
我们刚刚重新发现了这个同样美丽、强大的想法!如果你想看原版,这里是那本手册(作者是 McCarthy、Abrahams、Edwards、Hart、Levin)。这里是复制的内容:

好的,现在我们有了一个可以工作的完整语言的解释器。但是在确认这一点之前,我们应该尝试一些例子来确认我们对现有的结果满意。
好吧,实际上,我们不应该太过满意。考虑以下例子:
(let1E 'x (numE 1)
(let1E 'f (lamE 'y (varE 'x))
(let1E 'x (numE 2)
(appE (varE 'f) (numE 10)))))我们期望它产生什么?如果不确定,我们可以把它写成 Racket 程序:
(let ([x 1])
(let ([f (lambda (y) x)])
(let ([x 2])
(f 10))))
我们看到在 Racket 中,内部的 x 绑定不会覆盖外部的绑定,即在 f 定义时存在的那个。因此,这在 Racket 中产生 1 。
我们应该希望得到这个结果!否则,考虑这个程序:
(let1E 'f (lamE 'y (varE 'x))
(let1E 'x (numE 1)
(appE (varE 'f) (numE 10))))这相当于:
(let ([f (lambda (y) x)])
(let ([x 5])
(f 3)))
这会产生一个未绑定的标识符( x )错误。但我们的解释器会产生 1 而不是停止并抛出错误,这将我们带回到☠ 动态作用域 ☠!
练习 :在 Stacker 中运行以下程序。
那么我们如何解决这个问题呢?上面的示例实际上给了我们一些线索,但还有另一个灵感来源。你还记得我们是从替换开始的吗?我们将在 Racket 中逐步演示这些示例,以便你可以直接运行每个示例并检查它们是否产生相同的结果。再次考虑这个程序:
(let ([x 1])
(let ([f (lambda (y) x)])
(let ([x 2])
(f 10))))
将 1 替换为 x 产生:
(let ([f (lambda (y) 1)])
(let ([x 2])
(f 10)))
将 f 替换产生:
(let ([x 2])
((lambda (y) 1) 10))
最后,将 x 替换为 2 产生(注意程序中已经没有 x 了!):
((lambda (y) 1) 10)
当你这样看时,很明显后来的 x 绑定不应该有影响:这是一个不同的 x ,前面的 x 实际上已经被替换了。既然我们同意替换是我们希望程序工作的方式,那么我们的任务就是确保环境能够正确地实现这一点。
实现这一点的方法是认识到环境代表了等待发生的替换,并记住它们。也就是说,我们对函数的表示需要跟踪函数创建时的环境:
code
(define-type Value
[numV (the-number : Number)]
[boolV (the-boolean : Boolean)]
[funV (var : Symbol) (body : Exp) (nv : Env)])
这种新的、更丰富的 funV 值有一个特殊的名称:它被称为闭包( closure )。这是因为表达式“闭合”在其定义的环境中。
术语 :一个闭合项是没有未绑定变量的项。函数体可能有未绑定的变量——比如上面的
x——但闭包确保它们不是真的未绑定,因为它们可以从存储的环境中获取值。引语 :“拯救环境!今天创建一个闭包!” —— Cormac Flanagan
引语 :“Lambdas 相对默默无闻,直到 Java 通过不使用它们让它们流行起来。” —— James Iry,A Brief, Incomplete, and Mostly Wrong History of Programming Languages
这意味着,当我们创建一个闭包时,我们必须记录其创建时的环境:
code
[(lamE v b) (funV v b nv)]
最后,当我们使用一个函数(由闭包表示)时,我们必须确保使用其 存储 的环境,而不是调用函数时存在的 动态 环境:
code
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b nv)
(interp b (extend nv v av))]
[else (error 'app "didn't get a function")]))]
需要明确的是:在上面的代码中, funV 情况下的 nv 有意遮蔽了解释器顶部绑定的 nv 。因此,对 extend 的调用扩展了来自闭包的环境,而不是调用时存在的环境。
练习 :注意函数和参数表达式(分别为 f 和 a )在传递给解释器的环境中被求值,而不是在闭包环境中。这样做正确吗?还是它们应该使用闭包的环境?
你可以做两件事:从基本原理出发进行论证,或使用示例进行论证。在后者的情况下,你将修改解释器以选择另一种环境。然后,你可以使用一个样本输入,根据使用哪个环境会产生不同的答案,指出哪个是正确的(展示等效的 Racket 程序会产生什么可以是一个很好的论据),并用它来证明所选择的环境。
提示 :其中一个你需要从基本原理出发进行论证,另一个你应该能够使用程序进行论证。
在上面的示例中,我们总是在定义闭包的作用域中使用它。然而,我们的语言实际上比这更强大:我们可以 返回 一个闭包并在它被定义的作用域 之外 使用它。以下是一个示例 Racket 程序:
((let ([x 3])
(lambda (y) (+ x y)))
4)做一做 :花点时间仔细阅读它。它应该产生什么结果?
首先我们绑定 x ,然后我们求值 lambda。这会创建一个记住 x 绑定的闭包。这个闭包是这个表达式返回的值:
code
((let ([x 3])
(lambda (y) (+ x y)))
4)
这个值现在被应用到 4 。这是合法的,因为返回的值是一个函数。当我们将它应用到 4 时,它求值了 4 和 3 的和,产生 7 。确实如此,将其翻译并发送到我们的解释器会产生 7 :
(test (interp (appE (let1E 'x (numE 3)
(lamE 'y (plusE (varE 'x) (varE 'y))))
(numE '4))
mt-env)
(numV 7))练习:这是另一个可以尝试的测试,写成 Racket 程序:
((let ([y 3])
(lambda (y) (+ y 1)))
5)它在 Racket 中会产生什么结果?将它翻译并在你的解释器中试一试。
以下代码给出了实现了本章最终效果的解释器,以及一些测试代码(这些代码并不来自作者,而是 include-yy)
(需要注意,我(include-yy)并不保证代码的正确性,以及可读性)
#lang plait
(define-type Exp
[numE (n : Number)]
[boolE (b : Boolean)]
[varE (s : Symbol)]
[plusE (left : Exp) (right : Exp)]
[cndE (test : Exp) (then : Exp) (else : Exp)]
[let1E (var : Symbol) (value : Exp) (body : Exp)]
[lamE (var : Symbol) (body : Exp)]
[appE (fun : Exp) (arg : Exp)])
(define-type Value
[numV (the-number : Number)]
[boolV (the-boolean : Boolean)]
[funV (var : Symbol) (body : Exp) (nv : Env)])
(define (add v1 v2)
(type-case Value v1
[(numV n1)
(type-case Value v2
[(numV n2) (numV (+ n1 n2))]
[else (error '+ "expects RHS to be a number")])]
[else (error '+ "expects LHS to be a number")]))
(define (boolean-decision v)
(type-case Value v
[(boolV b) b]
[else (error 'if "expects conditional to evaluate to a boolean")]))
(define (interp e nv)
(type-case Exp e
[(numE n) (numV n)]
[(boolE b) (boolV b)]
[(varE s) (lookup s nv)]
[(plusE l r) (add (interp l nv) (interp r nv))]
[(lamE v b) (funV v b nv)]
[(cndE c t e) (if (boolean-decision (interp c nv))
(interp t nv)
(interp e nv))]
[(appE f a) (let ([fv (interp f nv)]
[av (interp a nv)])
(type-case Value fv
[(funV v b nv)
(interp b (extend nv v av))]
[else (error 'app "didn't get a function")]))]
[(let1E var val body)
(let ([new-env (extend nv
var
(interp val nv))])
(interp body new-env))]))
(define-type-alias Env (Hashof Symbol Value))
(define mt-env (hash empty))
(define (lookup (s : Symbol) (n : Env))
(type-case (Optionof Value) (hash-ref n s)
[(none) (error s "not bound")]
[(some v) v]))
(define (extend old-env new-name value)
(hash-set old-env new-name value))
(define (parse s)
(cond
[(s-exp-number? s)
(numE (s-exp->number s))]
[(s-exp-boolean? s)
(boolE (s-exp->boolean s))]
[(s-exp-symbol? s)
(varE (s-exp->symbol s))]
[(s-exp-list? s)
(let* ([l (s-exp->list s)]
[fst (first l)])
(if (s-exp-symbol? (first l))
(cond
[(symbol=? '+ (s-exp->symbol fst))
(plusE (parse (second l)) (parse (third l)))]
[(symbol=? 'lam (s-exp->symbol fst))
(lamE (s-exp->symbol (second l)) (parse (third l)))]
[(symbol=? 'let1 (s-exp->symbol fst))
(let1E (s-exp->symbol (first (s-exp->list (second l))))
(parse (second (s-exp->list (second l))))
(parse (third l)))]
[(symbol=? 'if (s-exp->symbol fst))
(cndE (parse (second l))
(parse (third l))
(parse (fourth l)))]
[(= (length l) 2)
(appE (parse (first l))
(parse (second l)))]
[else (error 'parse "list not a valid expression")])
(if (= (length l) 2)
(appE (parse (first l))
(parse (second l)))
(error 'parse "application expression not correct"))))]))
(define (my-eval exp)
(interp (parse exp) mt-env))
(print-only-errors #true)
(test (parse `{lam x {+ x x}})
(lamE 'x (plusE (varE 'x) (varE 'x))))
(test (interp (let1E 'x (numE 1)
(let1E 'f (lamE 'y (varE 'x))
(let1E 'x (numE 2)
(appE (varE 'f) (numE 10)))))
mt-env)
(numV 1))
(test (interp (appE (let1E 'x (numE 3)
(lamE 'y (plusE (varE 'x) (varE 'y))))
(numE '4))
mt-env)
(numV 7))
(test (my-eval `(let1 (x 1)
(let1 (f (lam y x))
(let1 (x 2)
(f 10)))))
(numV 1))
(test (my-eval `{let1 {x 1} {+ x x}}) (numV 2))
(test (my-eval `{let1 {x 1}
{let1 {y 2}
{+ x y}}})
(numV 3))
(test (my-eval `{let1 {x 1}
{let1 {y 2}
{let1 {x 3}
{+ x y}}}})
(numV 5))
(test (my-eval `{let1 {x 1}
{+ x
{let1 {x 2} x}}})
(numV 3))
(test (my-eval `{let1 {x 1}
{+ {let1 {x 2} x}
x}})
(numV 3))
(test (my-eval `{let1 {f {lam x {+ x x}}}
{f 3}})
(numV 6))
(test (my-eval `{let1 {x 3}
{let1 {f {lam y {+ x y}}}
{f 3}}})
(numV 6))