(我原先打算实现一个 MoonBit Parser,但是 MonnBit 的语法还不怎么稳定,而且没有现成的 Parser 可以参考,遂放弃。之前整理的资料直接丢了有点可惜,不如稍加整理放在这里打个小广告。原草稿写于 。)
本节对由 ReScript 作者开发的新语言 – MoonBit 进行了一点简单的资料搜集,主要目的是熟悉这门语言以方便尝试使用 tree-sitter 学习实现一个简单的 Parser。本文主要参考的是官方文档以及一些周边资料,比如一些官方博客和公众号文章。目前 MoonBit 还没有发布正式版,不过它提供了一个网页版可以测试代码是否可用。
MoonBit 的官网同时提供了中文版文档和英文版文档,不过中文文档内容上落后了,而且有些地方有错字。
在它们的官网上现存三篇博客,后两篇有一些代码示例:
- MoonBit: 面向 WebAssembly 的快速、简洁、用户友好的语言
- The Genesis Code of Life: 如何用Moonbit开发生命游戏?
- 如何用MoonBit绘制Mandelbrot Set?
官网上还有个俄罗斯方块 demo,我打到了 level 6:
官网上同时存在中文和英文论坛,似乎没什么人的样子:
在官方的 github 仓库中提供了这些东西:
- 计算斐波那契数列的 benchmark
- 一些代码示例,也即 https://try.moonbitlang.com/ 中给出的代码示例
- README.md 和 moon_build_system_tutorial.md,官方文档的源文档
- parser.mly,OCaml Menhir parser generator 使用的 parser specifications 文件,可用作编写 parser 的参考
目前可以找到 moonbit 的 VSCode 插件,目前未开源:
我们可以在 ~/.vscode/extensions/moonbit.moonbit-lang-0.1.207/lib 找到插件中的 LSP Server。
下面是一些公众号 Moonbit(gh_23f160fe1986) 上的文章,更新频率是每周一次,展示语言的新进展:
- Moonbit平台最新动态速递 Vol.01
- Moonbit平台最新动态速递 Vol.02
- Moonbit平台最新动态速递 Vol.03
- Moonbit平台最新动态速递 Vol.04
- Moonbit平台最新动态速递 Vol.05
- Moonbit平台最新动态速递 Vol.06
- Moonbit平台最新动态速递 Vol.07
- Moonbit平台最新动态速递 Vol.08
- MoonBit平台最新动态速递 Vol.09
现在()MoonBit 周报已经更新到了 22,离我上一次仔细看周报已经过去了三个月,语言也似乎有了比较大的变化,比如顶层函数的声明关键字由 func 改为了和内层函数一样的 fn (13);支持 Wasm GC(12);提供 Windows 平台支持(14);提供包管理工具和平台(mooncakes.io),等等。
也许我可以考虑在 MoonBit 正式推出后试试写个 tree-sitter Parser,现在的频繁变动阶段还是算了(现在官方已经提供了 tree-sitter parser,看来没必要了)。
正如我们说话并不需要完全清晰的语言学知识一样,写一个 parser 并不需要完整的编译器前端知识,理论上我们能够根据其他 tree-sitter parser 凑齐自己 parser 所需的所有用法(所谓的中文房间),但这是一个相当操蛋的过程(至少我的体验如此),因此我们也需要一些正向的学习过程。我认为读完《编译原理》的前两章(到中文版的第 67 页)后我们就有了用 tree-sitter 写 parser 的理论基础。感兴趣的话也可以看看后面的内容,我只是简单翻完了前四章而已。
这里只是一些简单的资料总结和链接罗列,因为我没有写编译原理教程的能力。如果读者对随后的内容感到困惑或难以理解,可以阅读《编译原理》原书或网络上的一些其他资料。由于知识的诅咒,我已经不知道哪些知识才是重点了,我不清楚我的浆糊脑子里面的哪一部分对于写 parser 是真正有用的,读者也可以告诉我难以理解的部分以方便我改进这篇文章。
- 《编译原理》第二版的前四章。读者没有必要完整的读完整个部分,挑自己喜欢的部分仔细看看就行,感兴趣的话还可以做做习题。我建议重点看第二章
- Wikipedia 上的一些条目,以下可能比较有用:
- Chomsky hierarchy,所谓的乔姆斯基文法,绝大多数编程语言都使用上下文无关文法
- Terminal and nonterminal symbols,介绍了终结符号和非终结符号
- Bottom-up parsing,自底向上 parsing 简介
- LR parser,一种自底向上 parsing 算法
- GLR parser,tree-sitter 使用的 parser 算法
- 自己动手写编译器 – 第 09 章 上下文无关语法及分析,偶然发现的资料,可以看看
- Flex(scanner)/Bison(parser)词法语法分析工作原理
- Lex与YACC详解
- Which Parsing Approach? 介绍了常见 parsing 方法,我简单翻译了一下
如果我是个编译原理教授的话也许我能给出更好的学习路径而不是随手甩一堆链接,但很可惜我不是。基于这个原因,下文中我对 tree-sitter 的介绍肯定是不完全的,读者如果在使用过程中遇到了无法通过本文解决的问题应该是很正常的。目前网上关于 tree-sitter 的文章不多,还不错的文章我只看到了这些:
- AST 获取与分析:Clang And Tree-sitter
- tree-sitter 语法参考
- 玩玩 tree-sitter,用 tree-sitter 写一个代码高亮
- Guide to your first Tree-sitter grammar
- How to write a tree-sitter grammar in an afternoon
- A Comprehensive Introduction to Tree-sitter
当然这只是所有文章的一小部分。
Tree-sitter is a parser generator tool and an incremental parsing library. It can build a concrete syntax tree for a source file and efficiently update the syntax tree as the source file is edited. Tree-sitter aims to be:
- General enough to parse any programming language
- Fast enough to parse on every keystroke in a text editor
- Robust enough to provide useful results even in the presence of syntax errors
- Dependency-free so that the runtime library (which is written in pure C) can be embedded in any application
tree-sitter 是一个 parser generator 工具,同时也是一个增量 parser 库,它能用于构建具体语法树(CST),并在源代码被编辑时快速更新语法树。在文档页面中你可以看到 Language Bindings 列表和 Parsers 列表,前者是各语言中的 tree-sitter 库绑定,后者是各种不同语言的 parser 实现。
在 tree-sitter 中,作为 parser generator 的部分叫做 tree-sitter-cli,我们可以通过 tree-sitter generate 从 grammar.js 生成 parser 的 C 源文件,它可被编译为可用的 parser 动态链接库;作为 parser 库的部分是 libtree-sitter.so 或 libtree-sitter.dll,这个库提供了利用得到的 parser 动态库进行增量解析的能力。
在这一节中,我会向读者介绍 tree-sitter parser 生成工具的基本用法,在之后的文章中我会介绍如何利用 libtree-sitter 提供的 API 操控解析得到的 CST。读者可以通过文档中给出的视频来简单了解 tree-sitter,如果对 tree-sitter 的原理感兴趣也可以去读一读文档中列出的论文,我就算了。
When initially parsing a file, tree-sitter-rust takes around twice as long as Rustc's hand-coded parser.
But if you edit the file after parsing it, this parser can generally update the previous existing syntax tree to reflect your edit in less than a millisecond, thanks to Tree-sitter's incremental parsing system.
当前(2024-02-03),tree-sitter 在 github 上已有 14.9k 个 star,1.2k 个 fork,4661 个 commit 和接近 1k 的 pr。目前 tree-sitter 的最新版本是 0.20.9,似乎离 1.0 还有些距离。
我并没有深入参与到 tree-sitter 开发的经历,这里只能通过观察 issue 简单了解一下它的发展状态。当前被置顶的两个 issue 分别是 Tree-sitter 1.0 Checklist 和 Tree-Sitter Roadmap,前者于 2021 年的 2 月 21 日 Open,后者就在昨天(2024-02-02)。在 1.0 Checklist 中,没有被打勾的目标似乎不是那么紧要的任务,比如支持 ES modules、从仓库中分离源代码与生成产物、改进文档等等;在 Tree-Sitter Roadmap 这个 issue 中,发起者 amaanq 给出了一些要在 0.20.10 和 0.21.0 达到的目标。也许我们已经可以认为 tree-sitter 在核心功能上已经成熟了,但谁知道呢。
(,现在 Tree-Sitter Roadmap 这个 issue 已被关闭,可以参考 milestones 了解 tree-sitter 进展)
至于 tree-sitter 的应用,根据文档的说法,tree-sitter-highlight 被 github 用于一些语言的高亮。在 neovim 中直接集成了对 tree-sitter 的支持,你可以在 nvim 源代码中找到 tree-sitter 的 binding。nvim 默认支持 bash, c, lua 等语言,用户可以使用 nvim-treesitter 插件方便地引入其他语言的 tree-sitter 支持,读者可以在该 repo 的 README 页面或 queries 目录中找到它当前支持的 parser 列表。我没有使用过 nvim 及其 tree-sitter 支持,这里有篇不错的文章可以看看。
就像本文开头提到的那样,emacs 于 29.1 引入了 tree-sitter 支持,当前 emacs 中已经有了一些支持 tree-sitter 的 major-mode。从我对 nvim 的粗浅了解来看它直接利用了 highlights.scm 来进行高亮,而 emacs 的 treesit 并未提供这样的支持(当然有其他的包,比如 treesit-langs。tree-sitter 也有 Discussions 在讨论相关的问题)。读者可以通过阅读 elisp manual 的 Parsing Program Source 一章了解如何在 emacs 中使用 tree-sitter,我会在之后的文章中进行介绍。在是否使用 hightlights.scm 作为各编辑器的公用标准这一讨论中,我比较认同下面的观点:
Highlighting query files are not a very large amount of work to make and might take a day or two at most for a very complicated grammar. If new clients want to reuse existing work they can choose to support the same capture names and predicates as for example neovim.
既然 vim(neovim)和 emacs 都提到了,那就顺带提一提 vscode 吧。通过搜索 vscode + tree-sitter ,你能找到一个叫做 vscode-tree-sitter 的插件,只不过在 README 的第一行就有这样的陈述: With the improving support for custom syntax coloring through language server, this extension is no longer needed ,参考这个讨论,类似的插件还有 syntax-highlighter 和 vscode-parse-tree。在 vscode 的 repo 中也有 issue 讨论了 tree-sitter 集成的问题,但到了今天也没有什么进展。vscode 本身提供了很多机制实现高亮等功能,读者可以阅读「你不知道的 VSCode 代码高亮原理」来简单了解。
为什么我们会突然想写个 tree-sitter parser?可能是突然想练练手学习一下编译原理,可能是闲得无聊打法一下时间,或者是为编辑器添加更准确的语法高亮和缩进。我不太可能知道读者们的动机和想法,只能提供一种编写 parser 的流程,希望能够有所帮助。
要编写一门语言的 parser,首先需要知道的是语言的书面语法,或者说语言标准。毕竟我们不是语言的设计者,仅凭编程经验来手搓容易漏掉一些犄角旮旯的细节,更何况编写的可能是从来没用过语言的 parser。举例来说的话,JavaScript(或者说 ECMAScript)的语言标准可以在 ECMA-262 标准中找到,C++ 则可以参考 EBNF Syntax: C++,Rust 可以参考 wg-grammar,zig 可以参考 zig-spec,等等。多数的语言标准应该会提供类似 BNF 形状的语言标准,读者可以简单了解一下什么是 BNF:Backus-Naur form。
在熟悉语言标准后,读者就可以开始 parser 的编写过程了。tree-sitter 将 creating parser 这一过程描述为 Developing Tree-sitter grammars can have a difficult learning curve, but once you get the hang of it, it can be fun and even zen-like. 是不是禅意的我不好说,只能说是唯手熟尔,多写一点就有经验了。一般编译型语言的编程流程是编写 -> 编译 -> 测试 -> 崩溃 -> 编写的一个循环,tree-sitter 也差不多是编写 -> 生成 -> 测试 -> 报错 -> 编写的过程。
tree-sitter 为我们提供了专门的测试子命令,我们可以在编写新规则时编写它的测试样例,然后在生成后直接测试,这也是文档推荐的做法: For each rule that you add to the grammar, you should first create a test that describes how the syntax trees should look when parsing that rule.
当编写的 parser 完全覆盖了目标语言的语法,且编写的测试全部通过时,我们可以认为我们完成了 parser 的开发工作。接下来我们可以将生成的 C 代码编译得到可用的动态库,然后通过 libtree-sitter 在自己的程序中加载并使用这个 parser。在使用过程中我们可能会碰到 parser 的 bug,从而导致不得不修改 parser 源代码来修复错误,我就碰到过 parser 瞬间吃满内存的 bug,但到现在我也不知道具体是什么原因(笑)。
需要说明的是,当前网上关于 tree-sitter 的资料少的可怜,如果读者在编写 parser 过程中遇到了问题且无法通过搜索引擎解决,那最好的方法可能是寻找其他语言中的类似结构,并参考其现成 tree-sitter parser 的实现。tree-sitter 官网列出了一堆已有的 parser 实现,其中的官方实现很有参考价值。
在 tree-sitter 文档的 Creating Parsers 一章中提到的依赖项是 node.js 和 C/C++ 编译器。在 Windows 上我们可以前往 node 官网下载 node.js,并通过安装 Visual Studio 顺带安装 MSVC 编译器(当然也可以仅安装生成工具)。随后,我们可以通过 npm 或 cargo 安装 tree-sitter-cli,这个工具的主要功能是根据 grammar.js 生成可被编译为动态链接库的 C 代码:
# rust cargo
cargo install tree-sitter-cli
# node npm
npm install tree-sitter-cli
# or get from prebuild binary
https://github.com/tree-sitter/tree-sitter/releases/tag/v0.20.9以上安装方法来自 tree-sitter-cli 的 README 页面,如果我们想要在 node 中使用 parser 的话最好参考官网中文档的做法(当然本文不会涉及到 parser 的使用):
# This will prompt you for input
npm init
# This installs a small module that lets your parser be used from Node
npm install --save nan
# This installs the Tree-sitter CLI itself
npm install --save-dev tree-sitter-cli
# 为啥使用 --save-dev 可参考
# https://stackoverflow.com/questions/22891211/what-is-the-difference-between-save-and-save-dev
在完成以上步骤后,我们就完成了 tree-sitter 开发环境的配置。官方文档推荐我们将项目的 node_modules/.bin 目录添加到当前环境变量 PATH 中来使用 tree-sitter-cli,不过我建议直接使用 npx 命令激活环境。接着我们在项目根目录添加一个 grammar.js 文件即可进行编译了:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => 'include-yy',
},
});
当你添加以上文件到项目根目录后,调用 tree-sitter generate 会在 src 目录下生成可编译的 C 文件,其中的 tree_sitter 目录包含源代码所需的头文件:
接着,我们可以使用 tree-sitter parse 命令测试某个文件是否满足 parser 规则。举例来说,如果 1.txt 中只包含 include-yy ,那么 tree-sitter parse 1.txt 会得到以下结果:

根据文档的说法,执行 tree-sitter parse 和 tree-sitter test 都需要 C/C++ 编译器的支持,因为需要编译 parser 得到可用的动态库。我倒是有些好奇如果没有安装编译器这些命令会有什么结果。
You might notice that the first time you run
tree-sitter testafter regenerating your parser, it takes some extra time. This is because Tree-sitter automatically compiles your C code into a dynamically-loadable library. It recompiles your parser as-needed whenever you update it by re-running tree-sitter generate.
generate, test 和 parse 是 tree-sitter 最核心的三个子命令,除此之外还有 query, tags, highlight, build-wasm, playground 和 dump-languages ,不过似乎和 parser 的编写过程关系不大,读者可以阅读 Syntax Highlighting 和 Code Navigation Systems 等章节来深入了解,这里我就不介绍了。
在我们执行 tree-sitter generate 时,除了会在 src 目录下生成 parser.c 外,还有 tree_sitter/parser.h ,这个头文件会提供一些在 parser.c 中使用的基础定义。除了这些可被编译的产物外, generate 指令还会在 bindings 目录下生成 node 和 Rust 的 binding(当然还有项目根目录下的 binding.gyp),它们具体包括这些内容:
通过使用 tree-sitter test 命令,我们可以使用位于 test/corpus 或 corpus 目录下的文件进行测试。根据文档的说法,每一条语法规则对应于一个测试文件,每个测试文件中可以有多个测试用例。在测试文件中,测试用例名使用 == 分隔,输入的源代码位于名字的后面,随后将源代码与预期语法树输出使用 --- 分隔,其中语法树输出使用 S 表达式的格式,且只应包含有名字的节点。对于上一节的示例 parser 我们可以写出这样的测试文件:
===========================
Me
===========================
include-yy
---
(source_file)
接着使用 tree-sitter test 命令会看到如下结果(第二次调用时我将输入代码改为了 include-yyy ,从而导致测试错误):
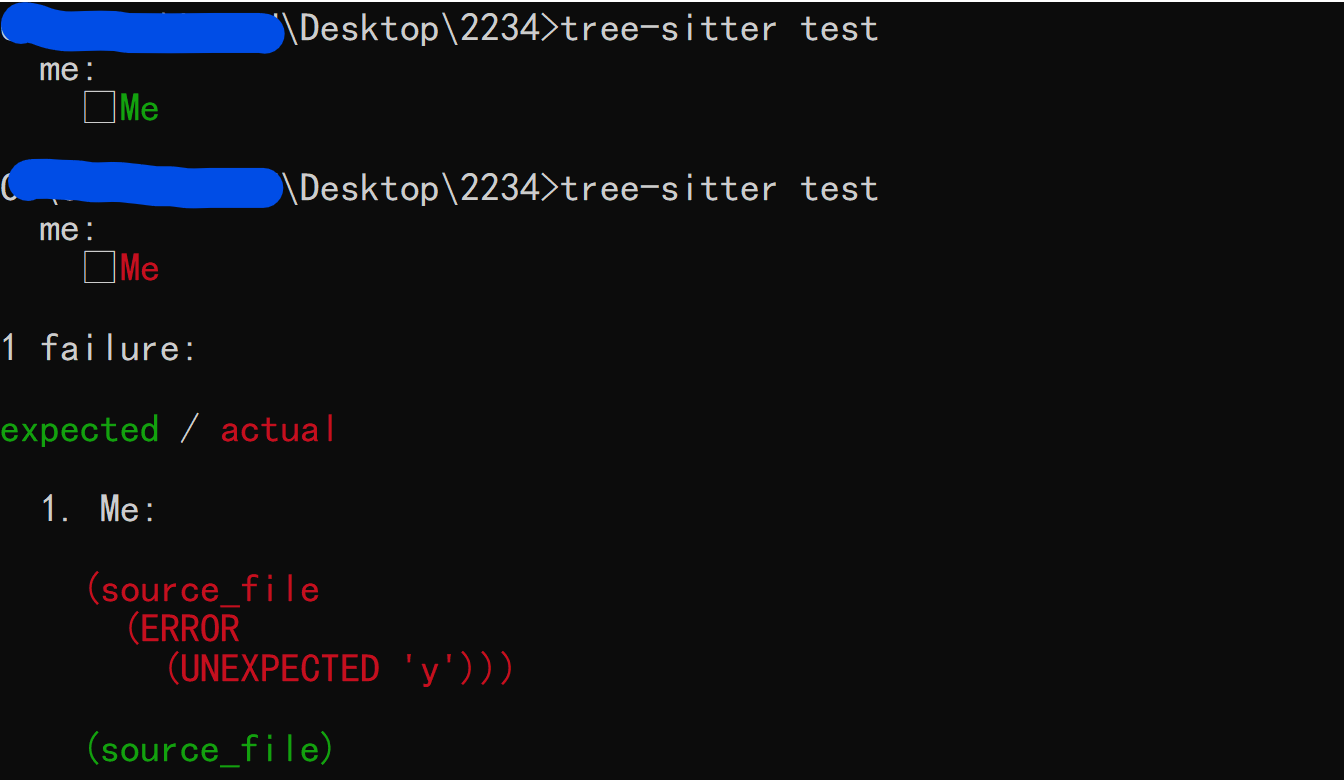
如果语言中的语法与测试文件冲突了,我们可以在 == 和 --- 的后面加上任意的由相同字符组成的后缀(文档中使用的是 | ),就像这样:
===========================||||
Me
===========================||||
include-yy
---||||
(source_file)
如果我们想要指定某个测试而不是一下子执行所有测试,可以使用 -f 参数: tree-sitter test -f "Me" 。如果我们想要在单个文件中创建多个测试用例,只需重复上面测试单元的结构即可,这个可以参考 tree-sitter-c 的一些测试文件。
除了使用 test 命令对位于特定位置的文件进行测试外,我们也可以使用 parse 命令来解析任意的指定文件。在上一节中我们指定单个文件 1.txt 进行解析,实际上 tree-sitter parse 命令支持任意数量的输入文件,它会对所有给定的文件进行解析,并输出解析结果。如果解析过程出现错误 tree-sitter 会返回一个非零状态码。我们可以指定 --quiet 标志让 tree-sitter 不输出解析结果,指定 --stat 让它输出解析成功和失败信息。文档将 parse 命令称为第二种测试手段:我们可以通过以下命令检测大量的文件:
tree-sitter parse 'examples/**/*.go' --quiet --stat
在这一小节中我对 using-parsers 给出的部分 C API 做了个总结,原先在写这篇文章时我打算将 tree-sitter parser 的编写和使用放在一篇文章中,现在看来内容有些过多了,这也就导致这一节和本文关系不是很大,读者可以选择跳过。当然提前了解一下 libtree-sitter 的用法也不是什么坏事就是了。
根据文档的说法,tree-sitter 提供了四种对象,分别是 TSLanguage, TSParser, TSTree 和 TSNode :
TSLanguage是一个不透明的对象,定义了如何解析特定的编程语言,它的代码来自使用 tree-sitter-cli 编写并生成的 parserTSParser是一个有状态的对象,可以通过TSLanguage指定要解析的语言,可由它根据源代码生成TSTree对象TSTree表示由源文档得到的整个语法树,它包含表示源代码结构的TSNode对象,当源代码发生变化时它也可以被用来生成新的TSTree对象TSNode表示语法树中的单个节点。它追踪源代码中它所在的起始和结束位置,以及它与其他节点(父兄子)的关系
根据文档中给出的 JSON 解析程序来看,首先我们需要创建 TSParser 指针类型的变量,随后将特定语言的 TSLanguage 对象绑定到 parser 上才能开始解析源代码:
// Declare the `tree_sitter_json` function, which is
// implemented by the `tree-sitter-json` library.
TSLanguage *tree_sitter_json();
int main() {
// Create a parser.
TSParser *parser = ts_parser_new();
// Set the parser's language (JSON in this case).
ts_parser_set_language(parser, tree_sitter_json());
// Build a syntax tree based on source code stored in a string.
const char *source_code = "[1, null]";
TSTree *tree = ts_parser_parse_string(
parser,
NULL,
source_code,
strlen(source_code)
);
// Get the root node of the syntax tree.
TSNode root_node = ts_tree_root_node(tree);
}下面是一些 API 的介绍:
ts_parser_parse_string,使用 parser 解析 buffer 中的源代码TSTree *ts_parser_parse_string( TSParser *self, const TSTree *old_tree, const char *string, uint32_t length );ts_parser_parse,使用TSInput结构而不是字符串 buffer 作为输入,它是更加灵活的 parse 函数TSTree *ts_parser_parse( TSParser *self, const TSTree *old_tree, TSInput input ); typedef struct { void *payload; const char *(*read)( void *payload, uint32_t byte_offset, TSPoint position, uint32_t *bytes_read ); TSInputEncoding encoding; } TSInput;可见
TSInput结构中要有存放文本的 payload,读取文本的raed函数和文本的编码。ts_node_type,获取节点的类型const char *ts_node_type(TSNode);ts_node_start_*和ts_node_end_*,获取节点在源代码中的位置范围tree sitter 分别提供了返回行列坐标和 byte offset 的函数,Emacs 的 treesit 应该使用的是 offset:
uint32_t ts_node_start_byte(TSNode); uint32_t ts_node_end_byte(TSNode); typedef struct { uint32_t row; uint32_t column; } TSPoint; TSPoint ts_node_start_point(TSNode); TSPoint ts_node_end_point(TSNode);节点获取与访问
我们可以使用
ts_tree_root_node从 TSTree 获取 root 节点TSNode ts_tree_root_node(const TSTree *);tree sitter 还提供了许多节点访问函数,可以获取当前节点的兄弟节点,父节点和子节点:
// Get the node's number of children. uint32_t ts_node_child_count(TSNode); // Get the node's child at the given index, where zero represents the first child. TSNode ts_node_child(TSNode, uint32_t); // Get the node's next / previous sibling. TSNode ts_node_next_sibling(TSNode); TSNode ts_node_prev_sibling(TSNode); // Get the node's immediate parent. TSNode ts_node_parent(TSNode);通过
ts_node_is_null我们可以判断某个节点是否是空节点,也即判断它是否存在:// Check if the node is null. Functions like [`ts_node_child`] and // [`ts_node_next_sibling`] will return a null node to indicate that no such node // was found. bool ts_node_is_null(TSNode);匿名节点与有名节点
在以下语法规则中,
if,(和)是匿名节点,而$._expression和$._statement是有名节点:if_statement: ($) => seq("if", "(", $._expression, ")", $._statement);通过使用匿名节点相关的 api 我们可以避免处理匿名节点。
/** * Check if the node is *named*. Named nodes correspond to named rules in the * grammar, whereas *anonymous* nodes correspond to string literals in the * grammar. */ bool ts_node_is_named(TSNode); // Get the node's *named* child at the given index. TSNode ts_node_named_child(TSNode, uint32_t); // Get the node's number of *named* children. uint32_t ts_node_named_child_count(TSNode); // Get the node's next / previous *named* sibling. TSNode ts_node_next_named_sibling(TSNode); TSNode ts_node_prev_named_sibling(TSNode);节点字段名
在编写 tree sitter parser 时,我们可以给节点赋予字段名字,并通过以下函数进行访问:
TSNode ts_node_child_by_field_name( TSNode self, const char *field_name, uint32_t field_name_length );有字段的节点拥有自己的 id,我们也可以通过名字获取 id 或通过 id 获取名字,并通过 id 访问节点的子节点:
// Get the number of distinct field names in the language. uint32_t ts_language_field_count(const TSLanguage *); // Get the field name string for the given numerical id. const char *ts_language_field_name_for_id(const TSLanguage *, TSFieldId); // Get the numerical id for the given field name string. TSFieldId ts_language_field_id_for_name(const TSLanguage *, const char *, uint32_t); // Get the node's child with the given field name. TSNode ts_node_child_by_field_id(TSNode, TSFieldId);
以上就是 tree sitter 的基本 api,如果之后的文章有用到 tree sitter 的高级特性我也会介绍的。
扯了这么多背景资料和工具用法,我们总算是来到了本文的核心部分:如何使用 tree-sitter 编写一个可用的 parser。这一节主要是对文档中 The Grammar DSL 及其后续内容的介绍,如果 tree-sitter 的文档写的足够详细本文可能就没有这一部分了,但是…… 在这一节中我会对文档中解释不够清楚的部分补充一些说明,比如实际的代码例子。
所有的 parser 代码都有类似的结构,大概如下所示:
// copied from tree-sitter-c
module.exports = grammar({
name: 'your-parser-name',
// optional public fields
extras: $ => [$.comment],
conflicts: $ => [
[$._type_specifier, $._declarator],
],
// rules start here
rules: {
translation_unit: $ => repeat($._top_level_item),
_top_level_item: $ => choice(
$.function_definition,
$.declaration,
//...
),
//...
},
})
在 rules 中,规则都是 rules 对象中的成员,它们的名字是产生式左边的非终结符号,值是以 $ 作为唯一参数的函数,函数内部使用 tree-sitter 的内置函数来描述产生式规则的右边,比如上面出现的 repeat 和 choice 。
你可能会注意到上面的 _top_level_item 等规则是以 _ 开头的。这表示这条规则会在语法树中被隐藏,合理利用下划线可以减少不必要的嵌套关系。
Starting a rule’s name with an underscore causes the rule to be hidden in the syntax tree. This is useful for rules like
_expressionin the grammars above, which always just wrap a single child node. If these nodes were not hidden, they would add substantial depth and noise to the syntax tree without making it any easier to understand.
下面我们首先介绍能与 BNF 规则简单对应的函数,以及一些额外的函数。
在文档的 The Grammar DSL 一节给出了所有可用的内置函数,这里我直接给出函数与 EBNF 规则的对照表,就不使用过多文字解释了:
| function | fun <-> EBNF |
|---|---|
| seq | paren_exp: $ => seq("(", $.exp, ")") <-> paren_exp = '(', exp, ')'; |
| choice | literal: $ => choice($.int, $.bool) <-> literal = int / bool; |
| repeat | attrs: $ => repeat($.attr) <-> attrs = {attr}; |
| repeat1 | arg_ls: $ => repeat1($.arg) <-> arg_ls = arg, {arg}; |
| optional | opt_type: $ => optional($.type) <-> opt_type = [type]; |
除了上面这些能够对应于 BNF 或 EBNF 的函数,tree-sitter 也提供了以下这些:
token(rule),将给定的规则标记为单个 tokentoken.immediate(rule),与token类似,但是仅在 token 前面没有空白字符时匹配alias(rule, name),让规则rule以名字name出现在语法树中,如果name是字符串字面量那么规则将会以匿名节点出现field(name, rule),为规则中匹配的子节点提供一个名字,方便访问
在表格中的函数很容易弄懂,但是列表中的那四个可就不是了。老实说,不管你是去看文档还是看我这里的解释你都可能不太懂它们到底是干什么的,仅仅是 grammar.js 中的代码可能并不能很好地体现出它们的具体作用,所以这里需要补充一些例子及其 C 语言对应产物。
token 表示我们将 rule 看作一个单独的词法单元,即 不关心这个元素的结构 。这一效果对应到生成的 parser.c 中就是 消除了不必要的匿名节点名字 。文档是这样描述 token 作用的:
Tree-sitter’s default is to treat each String or RegExp literal in the grammar as a separate token. Each token is matched separately by the lexer and returned as its own leaf node in the tree. The token function allows you to express a complex rule using the functions described above (rather than as a single regular expression) but still have Tree-sitter treat it as a single token.
文档中说到 tree-sitter 会将各 字符串 或 正则 视为不同的 token,这也就意味着 lexer 会将各字面量规则视为 不同 的节点,而 token 能让 lexer 将 rule 整体作为一个节点。(虽然有点牵强)上面的文档 暗含 了 token 不接受参数中存在非终结符号的意思,以下代码会报错:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => token($.abc),
abc: $ => 'abc',
},
});
//Error processing rule source_file_token1
//Caused by:
// Grammar error: Unexpected rule Symbol(Symbol { kind: NonTerminal, index: 1 })
在以下代码中,从生成产物 parser.c 可见 token 的使用与否会对生成的 ts_symbol_names 的大小和 ts_lex 中的状态数产生影响:
module.exports = grammar({
name: 'yy',
rules: {
// try to delete token and see what happened in parser.c after generating
source_file: $ => token(choice('ab', 'cd')),
},
});
以下代码是使用 token 和不使用 token 分别得到的 ts_symbol_names 代码:
// use token
static const char * const ts_symbol_names[] = {
[ts_builtin_sym_end] = "end",
[aux_sym_source_file_token1] = "source_file_token1",
[sym_source_file] = "source_file",
};
// not use token
static const char * const ts_symbol_names[] = {
[ts_builtin_sym_end] = "end",
[anon_sym_ab] = "ab",
[anon_sym_cd] = "cd",
[sym_source_file] = "source_file",
};
以下是使用 token 得到的 ts_lex :
static bool ts_lex(TSLexer *lexer, TSStateId state) {
START_LEXER();
eof = lexer->eof(lexer);
switch (state) {
case 0:
if (eof) ADVANCE(3);
if (lookahead == 'a') ADVANCE(1);
if (lookahead == 'c') ADVANCE(2);
if (lookahead == '\t' ||
lookahead == '\n' ||
lookahead == '\r' ||
lookahead == ' ') SKIP(0)
END_STATE();
case 1:
if (lookahead == 'b') ADVANCE(4);
END_STATE();
case 2:
if (lookahead == 'd') ADVANCE(4);
END_STATE();
case 3:
ACCEPT_TOKEN(ts_builtin_sym_end);
END_STATE();
case 4:
ACCEPT_TOKEN(aux_sym_source_file_token1);
END_STATE();
default:
return false;
}
}
以下是不使用 token 得到的 ts_lex :
static bool ts_lex(TSLexer *lexer, TSStateId state) {
START_LEXER();
eof = lexer->eof(lexer);
switch (state) {
case 0:
if (eof) ADVANCE(3);
if (lookahead == 'a') ADVANCE(1);
if (lookahead == 'c') ADVANCE(2);
if (lookahead == '\t' ||
lookahead == '\n' ||
lookahead == '\r' ||
lookahead == ' ') SKIP(0)
END_STATE();
case 1:
if (lookahead == 'b') ADVANCE(4);
END_STATE();
case 2:
if (lookahead == 'd') ADVANCE(5);
END_STATE();
case 3:
ACCEPT_TOKEN(ts_builtin_sym_end);
END_STATE();
case 4:
ACCEPT_TOKEN(anon_sym_ab);
END_STATE();
case 5:
ACCEPT_TOKEN(anon_sym_cd);
END_STATE();
default:
return false;
}
}
可见使用 token 减少了 ts_lex 中的状态数, ab 和 cd 经过 lexer 的词法分析过程都会得到 aux_sym_source_file_token1 类型的节点,而不是不同的 anon_sym_ab 和 anon_sym_cd ,这应该是有利于提高分析速度的。读者可以参考一些官方 tree-sitter parser 实现学习 token 的用法。
从功能上来说它 token.immediate 基本与 token 一致,但是它会保证它与前一 token 之间无空白字符时才会匹配。读者可以比较一下以下代码生成的 ts_lex 函数的不同之处:
module.exports = grammar({
name: 'yy',
rules: {
// try generate with token instead of token.immediate
source_file: $ => seq('1', token.immediate(choice('u', 'i'))),
},
});
有 token.immediate :
static bool ts_lex(TSLexer *lexer, TSStateId state) {
START_LEXER();
eof = lexer->eof(lexer);
switch (state) {
case 0:
if (eof) ADVANCE(2);
if (lookahead == '1') ADVANCE(3);
if (lookahead == 'i' ||
lookahead == 'u') ADVANCE(4);
if (lookahead == '\t' ||
lookahead == '\n' ||
lookahead == '\r' ||
lookahead == ' ') SKIP(1)
END_STATE();
case 1:
if (eof) ADVANCE(2);
if (lookahead == '1') ADVANCE(3);
if (lookahead == '\t' ||
lookahead == '\n' ||
lookahead == '\r' ||
lookahead == ' ') SKIP(1)
END_STATE();
case 2:
ACCEPT_TOKEN(ts_builtin_sym_end);
END_STATE();
case 3:
ACCEPT_TOKEN(anon_sym_1);
END_STATE();
case 4:
ACCEPT_TOKEN(aux_sym_source_file_token1);
END_STATE();
default:
return false;
}
}
仅有 token :
static bool ts_lex(TSLexer *lexer, TSStateId state) {
START_LEXER();
eof = lexer->eof(lexer);
switch (state) {
case 0:
if (eof) ADVANCE(1);
if (lookahead == '1') ADVANCE(2);
if (lookahead == 'i' ||
lookahead == 'u') ADVANCE(3);
if (lookahead == '\t' ||
lookahead == '\n' ||
lookahead == '\r' ||
lookahead == ' ') SKIP(0)
END_STATE();
case 1:
ACCEPT_TOKEN(ts_builtin_sym_end);
END_STATE();
case 2:
ACCEPT_TOKEN(anon_sym_1);
END_STATE();
case 3:
ACCEPT_TOKEN(aux_sym_source_file_token1);
END_STATE();
default:
return false;
}
}
此时仅从代码不太容易看出 token 与 token.immediate 的区别来,不过明显可以看出后者的 lex 函数比前者多出一个状态。而且为 token.immediate 时,以下测试会在 tree-sitter parse 中报错,但为 token 时能正常解析:
1 u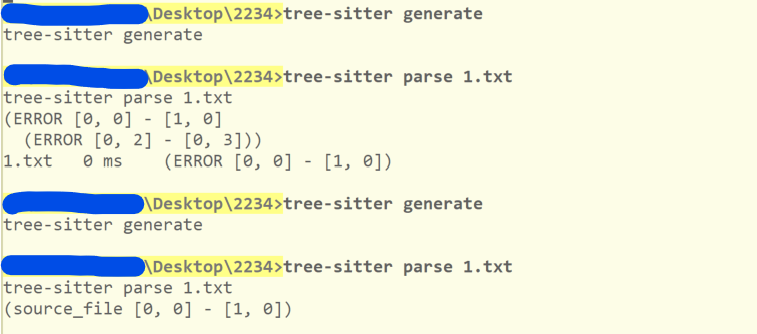
tree-sitter-c 中的宏定义可能能比较好地说明 token.immediate 的用法:
preproc_def: $ => seq(
preprocessor('define'),
field('name', $.identifier),
field('value', optional($.preproc_arg)),
token.immediate(/\r?\n/),
)
如你所见,文档对它的描述是让规则 rule 以 name 出现在语法树中。我们自然能想到它的一个用法就是为节点赋予名字,就像这样(当然这段代码有点小问题, + 和 * 没有优先级的区分):
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => $._exp,
_exp: $ => choice(
$.number,
seq($._exp, $.op, $.number),
),
// try remove `alias` and generate
op: $ => choice(
alias('+', $.add),
alias('*', $.mul),
),
number: $ => /[0-9]+/,
},
});
对于表达式 1 + 2 * 3 ,使用 alias 和不使用 alias 的结果分别如下:
tree-sitter parse 1.txt
(source_file [0, 0] - [1, 0]
(number [0, 0] - [0, 1])
(op [0, 2] - [0, 3]
(add [0, 2] - [0, 3]))
(number [0, 4] - [0, 5])
(op [0, 6] - [0, 7]
(mul [0, 6] - [0, 7]))
(number [0, 8] - [0, 9]))
tree-sitter parse 1.txt
(source_file [0, 0] - [1, 0]
(number [0, 0] - [0, 1])
(op [0, 2] - [0, 3])
(number [0, 4] - [0, 5])
(op [0, 6] - [0, 7])
(number [0, 8] - [0, 9]))
从给节点赋予名字这个功能来看, alias 可看作一种对规则的简写,我们可以使用如下代码实现和 alias 一样的效果:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => $._exp,
_exp: $ => choice(
$.number,
seq($._exp, $.op, $.number),
),
op: $ => choice(
$.add,
$.mul,
),
add: $ => '+',
mul: $ => '*',
number: $ => /[0-9]+/,
},
});那么如果规则本来就有名字会怎么样呢?以下代码可作为一种参考:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => $._exp,
_exp: $ => choice(
$.number,
seq($._exp, alias($.op, $.po), $.number),
),
op: $ => choice(
alias($.add, $.sub),
alias($.mul, $.div),
),
add: $ => '+',
mul: $ => '*',
number: $ => /[0-9]+/,
},
});
还是解析上面的 1 + 2 * 3 表达式,我们会得到如下结果:
tree-sitter parse 1.txt
(source_file [0, 0] - [1, 0]
(number [0, 0] - [0, 1])
(po [0, 2] - [0, 3]
(sub [0, 2] - [0, 3]))
(number [0, 4] - [0, 5])
(po [0, 6] - [0, 7]
(div [0, 6] - [0, 7]))
(number [0, 8] - [0, 9]))
可见对于有名字的规则, alias 起到的就是“改名”的效果,不过它也只是修改了名字,并没有改变原规则的结构。最后一种情况是对有名节点赋予字符串名字,也就是让它成为匿名节点:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => $._exp,
_exp: $ => choice(
$.number,
seq($._exp, alias($.op, 'op'), $.number),
),
op: $ => choice(
alias($.add, $.sub),
alias($.mul, $.div),
),
add: $ => '+',
mul: $ => '*',
number: $ => /[0-9]+/,
},
});
再次解析 1 + 2 * 3 ,我们会得到以下结果,可见 $.op 节点不见了:
tree-sitter parse 1.txt
(source_file [0, 0] - [1, 0]
(number [0, 0] - [0, 1])
(sub [0, 2] - [0, 3])
(number [0, 4] - [0, 5])
(div [0, 6] - [0, 7])
(number [0, 8] - [0, 9]))
如你所见, alias 在不同情况下可以起到 起名 , 改名 , 消名 的作用。读者可以随便找一个 tree-sitter parser 然后全文搜索 alias 来学习它的具体用法,我推荐 tree-sitter-c。
相比前三个函数 field 要好理解的多,就是给某规则的某个子节点赋一个字段名来方便访问,不过由于本文不涉及 parser 使用,可能不能很好地体现方便访问这一作用。让我们解析一个长度为 3 的元组,并给每个字段分别赋予 one, two 和 three 的名字:
module.exports = grammar({
name: 'yy',
rules: {
source_file: $ => seq('(',
field('one', $.number), ',',
field('two', $.number), ',',
field('three', $.number), optional(','),
')',
),
number: $ => /[0-9]+/,
},
});
对字符串 (1, 2, 3) ,它给出的解析结果如下:
tree-sitter parse 1.txt
(source_file [0, 0] - [1, 0]
one: (number [0, 1] - [0, 2])
two: (number [0, 4] - [0, 5])
three: (number [0, 7] - [0, 8]))不管你学的是什么编程语言,一般入门教程的前几章都会提到并介绍表达式运算符的优先级和结合性这个知识点。C 语言中各算符的优先级可以参考 cppreference.com,JavaScript 可以参考 MDN。
通俗地说,优先级就是算符与算子的结合紧密程度,结合性描述了表达式中连续出现多个相同优先级操作符时的操作执行顺序。在一个包含多个操作符和操作数的表达式中,优先级高的操作符会更先与相邻的操作数结合,左结合操作符会将左边的操作数当作一个整体,右结合则将右侧操作数当作整体。但是更严谨地说,优先级和结合性的概念作用于产生式规则而不是操作符,优先级和结合性通过产生式的规则来体现,下面的代码及其解析结果可以说明这一点:
module.exports = grammar({
name: 'yy',
rules: {
src: $ => $.add_exp,
add_exp: $ => choice(
$.mul_exp,
seq($.add_exp, token(choice('+', '-')), $.mul_exp),
),
mul_exp: $ => choice(
$.number,
seq($.mul_exp, token(choice('*', '/')), $.number),
),
number: $ => /[0-9]+/,
},
})
还是解析 1 + 2 * 3 ,我们可以得到以下结果:
tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(add_exp [0, 0] - [0, 9]
(add_exp [0, 0] - [0, 1]
(mul_exp [0, 0] - [0, 1]
(number [0, 0] - [0, 1])))
(mul_exp [0, 4] - [0, 9]
(mul_exp [0, 4] - [0, 5]
(number [0, 4] - [0, 5]))
(number [0, 8] - [0, 9]))))
上面的规则表示 mul_exp 具有比 add_exp 更高的优先级,这是因为它的嵌套“更深”,需要首先被解析。上面的规则也表示了结合性:不管是加减法还是乘除法都具有左结合性,这可以通过解析 1 + 2 + 3 + 4 的结果来体现(注意树的生长方式):
tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(add_exp [0, 0] - [0, 13]
(add_exp [0, 0] - [0, 9]
(add_exp [0, 0] - [0, 5]
(add_exp [0, 0] - [0, 1]
(mul_exp [0, 0] - [0, 1]
(number [0, 0] - [0, 1])))
(mul_exp [0, 4] - [0, 5]
(number [0, 4] - [0, 5])))
(mul_exp [0, 8] - [0, 9]
(number [0, 8] - [0, 9])))
(mul_exp [0, 12] - [0, 13]
(number [0, 12] - [0, 13]))))
如果加减乘除具有右结合性,那么同样是 1 + 2 + 3 + 4 我们会得到以下结果:
module.exports = grammar({
name: 'yy',
rules: {
src: $ => $.add_exp,
add_exp: $ => choice(
$.mul_exp,
seq($.mul_exp, token(choice('+', '-')), $.add_exp),
),
mul_exp: $ => choice(
$.number,
seq($.number, token(choice('*', '/')), $.mul_exp),
),
number: $ => /[0-9]+/,
},
})tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(add_exp [0, 0] - [0, 13]
(mul_exp [0, 0] - [0, 1]
(number [0, 0] - [0, 1]))
(add_exp [0, 4] - [0, 13]
(mul_exp [0, 4] - [0, 5]
(number [0, 4] - [0, 5]))
(add_exp [0, 8] - [0, 13]
(mul_exp [0, 8] - [0, 9]
(number [0, 8] - [0, 9]))
(add_exp [0, 12] - [0, 13]
(mul_exp [0, 12] - [0, 13]
(number [0, 12] - [0, 13])))))))
语言标准中为了表示优先级和结合性会广泛使用上面这种结构,tree-sitter 文档中给出了根据 ES 标准解析 return x + y; 所带来的产生式嵌套:
ReturnStatement -> 'return' Expression
Expression -> AssignmentExpression
AssignmentExpression -> ConditionalExpression
ConditionalExpression -> LogicalORExpression
LogicalORExpression -> LogicalANDExpression
LogicalANDExpression -> BitwiseORExpression
BitwiseORExpression -> BitwiseXORExpression
BitwiseXORExpression -> BitwiseANDExpression
BitwiseANDExpression -> EqualityExpression
EqualityExpression -> RelationalExpression
RelationalExpression -> ShiftExpression
ShiftExpression -> AdditiveExpression
AdditiveExpression -> MultiplicativeExpression
MultiplicativeExpression -> ExponentiationExpression
ExponentiationExpression -> UnaryExpression
UnaryExpression -> UpdateExpression
UpdateExpression -> LeftHandSideExpression
LeftHandSideExpression -> NewExpression
NewExpression -> MemberExpression
MemberExpression -> PrimaryExpression
PrimaryExpression -> IdentifierReference
现在我们可以回收一下文章开头提到的 tree-sitter-wgsl 官方实现了,我之所以说它基本上是没用的实现,就是因为它并没有使用 tree-sitter 提供的优先级和结合性内置函数来消除这些繁琐的嵌套,举例来说,表达式 1 + 2 + 3 + 4 在 tree-sitter-wgsl 中的解析结果是这样的:
var bar = 1 + 2 + 3 + 4;
------------------------
tree-sitter parse 1.txt
(translation_unit [0, 0] - [1, 0]
(global_variable_decl [0, 0] - [0, 23]
(variable_decl [0, 0] - [0, 7]
(var [0, 0] - [0, 3])
(ident [0, 4] - [0, 7]))
(equal [0, 8] - [0, 9])
(expression [0, 10] - [0, 23]
(relational_expression [0, 10] - [0, 23]
(shift_expression [0, 10] - [0, 23]
(additive_expression [0, 10] - [0, 23]
(additive_expression [0, 10] - [0, 19]
(additive_expression [0, 10] - [0, 15]
(additive_expression [0, 10] - [0, 11]
(multiplicative_expression [0, 10] - [0, 11]
(unary_expression [0, 10] - [0, 11]
(singular_expression [0, 10] - [0, 11]
(primary_expression [0, 10] - [0, 11]
(const_literal [0, 10] - [0, 11]
(int_literal [0, 10] - [0, 11])))))))
(plus [0, 12] - [0, 13])
(multiplicative_expression [0, 14] - [0, 15]
(unary_expression [0, 14] - [0, 15]
(singular_expression [0, 14] - [0, 15]
(primary_expression [0, 14] - [0, 15]
(const_literal [0, 14] - [0, 15]
(int_literal [0, 14] - [0, 15])))))))
(plus [0, 16] - [0, 17])
(multiplicative_expression [0, 18] - [0, 19]
(unary_expression [0, 18] - [0, 19]
(singular_expression [0, 18] - [0, 19]
(primary_expression [0, 18] - [0, 19]
(const_literal [0, 18] - [0, 19]
(int_literal [0, 18] - [0, 19])))))))
(plus [0, 20] - [0, 21])
(multiplicative_expression [0, 22] - [0, 23]
(unary_expression [0, 22] - [0, 23]
(singular_expression [0, 22] - [0, 23]
(primary_expression [0, 22] - [0, 23]
(const_literal [0, 22] - [0, 23]
(int_literal [0, 22] - [0, 23])))))))))))
(semicolon [0, 23] - [0, 24]))什么狗屎😅。
tree-sitter 为我们提供了这些内置函数来 显式 指定产生式规则的优先级和结合性:
prec(number, rule),它为规则提供一个数字指定的优先级来解决 parser 生成时的 LR(1) 冲突。当两条规则可能产生歧义时 tree-sitter 会选择优先级更高的那个。默认情况下所有规则的优先级都是 0prec.left([number], rule),它将规则标记为 左结合 (可选提供一个优先级数字),当在所有规则都具有相同优先级数值的情况下出现 LR(1) 冲突时,tree-sitter 会根据优先级规则消除冲突prec.right([number], rule),它将规则标记为 右结合 (同样可选提供优先级)
还是上面的加减乘除表达式解析,现在让我们加上指数运算来展示右结合。根据 Python 的操作符优先级,指数 ** 高于乘法高于加法,我们可以如此实现:
module.exports = grammar({
name: 'yy',
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.number,
$.paren_exp,
$.binary_exp,
),
paren_exp: $ => seq('(', $._exp, ')'),
binary_exp: $ => choice(
prec.right(3, seq(
field('l', $._exp),
field('op', '**'),
field('r', $._exp))),
prec.left(2, seq(
field('l', $._exp),
field('op', token(choice('*', '/'))),
field('r', $._exp))),
prec.left(1, seq(
field('l', $._exp),
field('op', token(choice('+', '-'))),
field('r', $._exp))),
),
number: $ => /[0-9]+/,
},
})
以下是解析 1 + 2 * 3 ** (1 + 2) 的结果:
tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(binary_exp [0, 0] - [0, 20]
l: (number [0, 0] - [0, 1])
r: (binary_exp [0, 4] - [0, 20]
l: (number [0, 4] - [0, 5])
r: (binary_exp [0, 8] - [0, 20]
l: (number [0, 8] - [0, 9])
r: (paren_exp [0, 13] - [0, 20]
(binary_exp [0, 14] - [0, 19]
l: (number [0, 14] - [0, 15])
r: (number [0, 18] - [0, 19])))))))
在指定优先级这件事上,除了全序(total order)外,我们还可以使用偏序(partial order),不过这在文档中并没有得到说明。简单来理解就是偏序允许我们定义不同组别的优先级关系,组别内能够进行比较,但是组别间不能进行比较。通过使用与 rules 同级的 precedences 我们可以定义偏序优先级,它是一个包含字符串数组的数组,字符串数组的优先级单调递减。我们可以这样实现上面的优先级:
module.exports = grammar({
name: 'yy',
precedences: $ => [
['expt', 'mul', 'add'],
],
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.number,
$.paren_exp,
$.binary_exp,
),
paren_exp: $ => seq('(', $._exp, ')'),
binary_exp: $ => choice(
prec.right('expt', seq(
field('l', $._exp),
field('op', '**'),
field('r', $._exp))),
prec.left('mul', seq(
field('l', $._exp),
field('op', token(choice('*', '/'))),
field('r', $._exp))),
prec.left('add', seq(
field('l', $._exp),
field('op', token(choice('+', '-'))),
field('r', $._exp))),
),
number: $ => /[0-9]+/,
},
})
precedences 的使用方式可以参考 tree-sitter-javascript,里面还有一些更加神奇的用法。
在上一节中我展示了如何通过 prec 解决优先级的问题,但并未展示使用 tree-sitter generate 试图生成带有冲突的 grammar.js 的结果,对于以下语法我们会得到如下输出:
module.exports = grammar({
name: 'yy',
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.number,
$.binary_exp,
),
binary_exp: $ => seq($._exp, choice('*', '/'), $._exp),
number: $ => /[0-9]+/,
},
})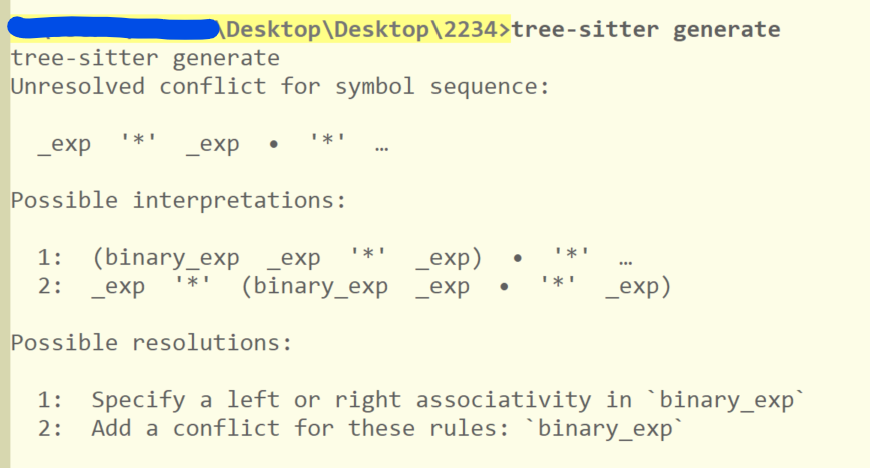
可见 tree-sitter 能够识别出语法中的冲突,并给出合适的建议,这些建议对于编写一个可用的 parser 非常有用。如果我们按照上面的第一条方法进行修复,那就是通过 prec 等函数指定结合性的方法。当然它也指出了另一种方法:通过 conflicts 指定现有的冲突:
module.exports = grammar({
name: 'yy',
conflicts: $ => [
[$.binary_exp],
],
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.number,
$.binary_exp,
),
binary_exp: $ => seq($._exp, choice('*', '/'), $._exp),
number: $ => /[0-9]+/,
},
})
// parse 1 * 2 * 3
// tree-sitter parse 1.txt
// (src [0, 0] - [1, 0]
// (binary_exp [0, 0] - [0, 9]
// (binary_exp [0, 0] - [0, 5]
// (number [0, 0] - [0, 1])
// (number [0, 4] - [0, 5]))
// (number [0, 8] - [0, 9])))
可见在加上 conflicts 后结合性冲突被消除了,而且还是我们所期望的 左结合 。如果你有意注意上面截图中的 Possible interpretations 中规则的顺序,你会发现左结合在右结合之前。如果我们想要让右结合的的优先级高于左结合,我们可以使用 pred.dynamic : binary_exp: $ => pred.dynamic(1, pred.right(...)) 。但是这个用法并不能显著体现出动态优先级的作用,毕竟我完全可以直接使用 pred.right 。文档是这样描述 pred.dynamic 和 conflicts 的:
prec.dynamic(number, rule),该函数与prec类似,但优先级应用于 运行时 而不是 parser 生成时。这只在使用conflicts处理冲突以及存在真正歧义(genuine ambiguity)时才需要: 多个规则 正确匹配给定的代码片段。在这种情况下,tree-sitter 比较与每个规则关联的总动态优先级,并选择具有最高优先级的那个conflicts一个由规则名称数组组成的数组。每个内部数组代表一组在语法中存在的 LR(1) 冲突的规则。当这些冲突在运行时发生时,tree-sitter 将使用 GLR 算法来探索所有可能的解释。如果多个解析最终成功,tree-sitter 将选择对应规则具有最高动态优先级的子树
我没有认真学过 parser 知识,这里只能给出我对这类所谓运行时冲突的粗浅认识:即在 tree-sitter 中无法使用 prec 和 prec.left 或 prec.right 消除的冲突,换言之就是语言中固有的 LR(1) 冲突。要解决这类冲突,tree-sitter 给出的方法是 GLR,但我也没有从理论上尝试理解过它,这里就打住了。下面我会给出一些使用 conflicts 解决冲突的例子,方便读者理解和使用。
在 C++ 中一个显而易见的例子就是嵌套的模板和比较操作符以及位移操作符之间的冲突。(更加详细的描述可以参考 C++ Template Ambiguity 和 Right angle bracket),在 C++ Primer 5th 中是这样描述的:

在 C++ 语法的 EBNF 描述中,你可以发现(善用 Ctrl+F) template_argument_list (模板列表)中的 template_argument 可为 assignment_expression 表达式。而如果你顺着 assignment_expression 往上找的话,你能够找到以下链条:
template_argument_list = template_argument | template_argument_list ',' template_argument
template_argument = assignment_expression | type_id | id_expression
assignment_expression -> conditional_expression -> logical_or_expression ->
logical_and_expression -> inclusive_or_expression -> exclusive_or_expression ->
and_expression -> equality_expression -> rational_expression(<, >, <=, >=) ->
shift_expression(<<, >>) -> additive_expression(+, -) ->
multiplicative_expression(*, /, %) -> pm_expression -> cast_expression ->
unary_expression -> postfix_expression -> primary_expression -> id_expression ->
unqualified_id -> template_id
template_id = template_name '<' [template_argument_list] '>'哈哈,绕了一圈又绕回来了,而且实际还不止这一条路径。那么这样的圈圈有什么问题呢,我们现在写个简化的 tree-sitter 语法看看:
module.exports = grammar({
name: 'yy',
conflicts: $ => [
//[$._exp, $.template_id],
//[$._exp, $.template_argument_list],
],
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.binary_exp,
$.id,
$.number,
$.template_id,
),
id: $ => token(/([_\p{XID_Start}][\p{XID_Continue}]+)|([\p{XID_Start}])/uy),
number: $ => /[0-9]+/,
template_id: $ => seq($.id, $.template_argument_list),
template_argument_list: $ => seq(
'<',
commaSep(choice(
$._exp,
$.template_id,
)),
'>'),
binary_exp: $ => choice(
prec.right(1, seq($._exp, alias('<', $.lt), $._exp)),
prec.right(1, seq($._exp, alias('>', $.gt), $._exp)),
prec.right(2, seq($._exp, alias('<<', $.shl), $._exp)),
prec.right(2, seq($._exp, alias('>>', $.shr), $._exp)),
prec.right(3, seq($._exp, alias('+', $.add), $._exp)),
prec.right(3, seq($._exp, alias('-', $.sub), $._exp)),
prec.right(4, seq($._exp, alias('*', $.mul), $._exp)),
prec.right(4, seq($._exp, alias('/', $.div), $._exp)),
),
},
})
function commaSep(rule) {
return optional(commaSep1(rule));
}
function commaSep1(rule) {
return seq(rule, repeat(seq(',', rule)));
}
对以上语法使用 tree-sitter generate 命令,我们可以得到如下结果:

在上面的输出中,只有最后一条是靠谱的(我实在想不到如何给 _exp 添加结合性或者是优先级)。现在让我们加上 conflicts:$ => [[$._exp, $.template_id],], 试试:

现在 tree-sitter 提示我们仍然存在冲突,我们继续加上 [$._exp, $.template_argument_list] ,然后就可以正常生成了,但是在解析类似 vec<vec<2>> 的字符串时会得到错误的结果:
tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(binary_exp [0, 0] - [0, 11]
(id [0, 0] - [0, 3])
(lt [0, 3] - [0, 4])
(binary_exp [0, 4] - [0, 11]
(id [0, 4] - [0, 7])
(lt [0, 7] - [0, 8])
(binary_exp [0, 8] - [0, 11]
(number [0, 8] - [0, 9])
(shr [0, 9] - [0, 11])
(id [0, 11] - [0, 11])))))
1.txt 0 ms (MISSING id [0, 11] - [0, 11])
可见此时我们的 parser 还是不能正常处理模板与 > 和 >> 的区别。我们需要赋予位于 template_argument_list 中的元素以不同的优先级:
template_argument_list: $ => seq(
'<',
commaSep(choice(
prec.dynamic(1, $._exp),
prec.dynamic(2, $.template_id),
)),
'>')但是光是这样做似乎还是不够,我参考了 tree-sitter-cpp 的相同部分实现,发现它对模板的结尾符号赋予了一个非常奇怪的优先级:
template_argument_list: $ => seq(
'<',
commaSep(choice(
prec.dynamic(3, $.type_descriptor),
prec.dynamic(2, alias($.type_parameter_pack_expansion, $.parameter_pack_expansion)),
prec.dynamic(1, $._expression),
)),
alias(token(prec(1, '>')), '>'),
)
直到现在我也不太理解这个 token(prec(1, '>')) 到底有什么用… 不过这样做之后代码确实能够工作了(注意下面对 binary_expression 内各规则的优先级的修改):
module.exports = grammar({
name: 'yy',
conflicts: $ => [
[$._exp, $.template_id],
[$._exp, $.template_argument_list],
],
rules: {
src: $ => $._exp,
_exp: $ => choice(
$.binary_exp,
$.id,
$.number,
$.template_id,
),
id: $ => token(/([_\p{XID_Start}][\p{XID_Continue}]+)|([\p{XID_Start}])/uy),
number: $ => /[0-9]+/,
template_id: $ => seq($.id, $.template_argument_list),
template_argument_list: $ => seq(
'<',
commaSep(choice(
prec.dynamic(1, $._exp),
prec.dynamic(2, $.template_id),
)),
alias(token(prec(1, '>')), '>')),
binary_exp: $ => choice(
prec.right(2, seq($._exp, alias('<', $.lt), $._exp)),
prec.right(2, seq($._exp, alias('>', $.gt), $._exp)),
prec.right(3, seq($._exp, alias('<<', $.shl), $._exp)),
prec.right(3, seq($._exp, alias('>>', $.shr), $._exp)),
prec.right(4, seq($._exp, alias('+', $.add), $._exp)),
prec.right(4, seq($._exp, alias('-', $.sub), $._exp)),
prec.right(5, seq($._exp, alias('*', $.mul), $._exp)),
prec.right(5, seq($._exp, alias('/', $.div), $._exp)),
),
},
})
function commaSep(rule) {
return optional(commaSep1(rule));
}
function commaSep1(rule) {
return seq(rule, repeat(seq(',', rule)));
}
还是对于 vec<vec<1>> ,现在我们能得到如下正确结果:
tree-sitter parse 1.txt
(src [0, 0] - [1, 0]
(template_id [0, 0] - [0, 11]
(id [0, 0] - [0, 3])
(template_argument_list [0, 3] - [0, 11]
(template_id [0, 4] - [0, 10]
(id [0, 4] - [0, 7])
(template_argument_list [0, 7] - [0, 10]
(number [0, 8] - [0, 9]))))))
目前我对 conflicts 和 prec.dynamic 的理解是非常粗浅的,我也不知道 cpp parser 到底玩了些什么魔法。读者若遇到语言中固有 LR(1) 冲突,建议去具有相似冲突的已有 tree-sitter 实现中找找灵感。
另外需要注意的是,你可以看到我在 grammar.js 中使用了自定义的 JS 函数,目前我不知道 tree-sitter 对 JS 的支持究竟到了怎样的地步,也许只要是返回 DSL 函数表达式都行?读者可以参考各 parser 实现中出现的 JS 语言用法,尤其是 C/C++ 这对父子(从 tree-sitter parser 依赖关系的意义上来看)。
如果你看过了《编译原理》,你就会知道词法分析和语法分析是两个分开的过程。虽然我们通过 tree-sitter-cli 并不会得到单独的 lexer 或者 scanner,但正如你在上面的 C 代码中看到的,tree-sitter parser 并不是没有词法分析过程,而是我们无需自己调用 lexer 来做词法分析。在这一节中我会介绍文档中 Lexical Analysis 一节中的内容,同时尝试解答上面关于 token(prec(1, '>')) 的一些疑惑。
文档列出了 lexer 的行为规则,这里简单翻译一下:
- Context-aware Lexing tree-sitter 在解析过程中按需执行词法分析。在源文档的任何给定位置,lexer 只尝试识别在该位置有效的 token
- Lexical Precedence 当优先级函数(指
prec系列函数)在token函数内使用时,给定的显式优先级值作为指令传递给 lexer。如果在文档的给定位置有两个有效的 token 与字符匹配,tree-sitter 将选择具有更高优先级的那一个 - Match Length 如果在源文档给定位置有多个具有相同优先级的有效 token 与字符匹配,tree-sitter 将选择匹配字符序列最长的 token
- Match Specificity 如果有两个有效的 token 具有相同的优先级并且都匹配相同数量的字符,tree-sitter 将倾向于选择在语法中作为
String指定的 token,而不是作为Regexp指定的 token - Rule Order 如果上述任何标准都无法用来选择一个 token 而不选择另一个,tree-sitter 将倾向于选择在语法中更早出现的 token
(这篇文章的时间跨度实在是有点大了,我大概在一周前写完了上一小节,如果能把对在 token 内的解释放到上面 C++ 的部分应该更好一点)
如你所见,上面规则的第二条说明了在 token 函数内使用优先级函数时的行为,它修改的是 lexer 中的优先级,而不是解析过程的优先级。文档是这样描述的:
One common mistake involves not distinguishing lexical precedence from parse precedence. Parse precedence determines which rule is chosen to interpret a given sequence of tokens. Lexical precedence determines which token is chosen to interpret at a given position of text and it is a lower-level operation that is done first.
虽然我认识到了 token(prec()) 与一般 prec 的不同之处,但上一节 template_id 部分的代码还是有些难以理解,目前只能搁置在这里了。和 lexer 有关的字段有 word , extras 和 externals ,其中 externals 文档已经介绍的比较详细了(至少能知道怎么写), word 起的作用也足够明显,此处就不介绍了。
我们可以使用 extras 指定可出现在源文档任意位置的 token,默认情况下它就是空格,通过添加注释规则我们可以忽略掉文档注释,比如以下是 tree-sitter-c 的 extras 字段:
extras: $ => [
/\s|\\\r?\n/,
$.comment,
],
所谓 public field,在 tree-sitter DSL 中指的是 grammar 接受的结构中的字段,在上面我们已经见识过了 name, rules, precedences 和 extras 等字段,现在提一下剩下的两个: inline 和 supertypes 。
文档关于 inline 的描述是这样的,由于不长我就懒得翻译了:
inline - an array of rule names that should be automatically removed from the grammar by replacing all of their usages with a copy of their definition. This is useful for rules that are used in multiple places but for which you don’t want to create syntax tree nodes at runtime.
从描述上来看, inline 和内联函数很像,生成的语法树中不会存在被内联的节点。看过本文前面的读者应该还记得前面提到过匿名节点(简单字符串或正则)和隐藏节点(名字前面带 _ 的规则),这两者在语法树中是实际存在的,即使 tree-sitter 的某些 API 会忽略掉它们。位于 inline 数组中的规则会被完全展开而在解析得到的语法数中完全不存在。这里的讨论应该能够说明这一点,我就不举例说明了(本文不涉及 API 使用,举也举不出)。
最后的 supertypes 只有轻飘飘的一句话:
supertypes an array of hidden rule names which should be considered to be ‘supertypes’ in the generated node types file.
请参考引文中的链接来了解它的用法,目前我也不知道有什么用。
(原本打算带着读者们从头到尾过一遍 WGSL 标准,并详细讲讲一些要点,但想了想感觉没有必要,一来 WGSL 这门语言并不复杂,二来 WGSL 标准还在不断变化中)
目前,我已经实现了一个 WGSL parser,读者可以从 gist 获取,并按照 tree-sitter 的标准布局摆放 grammar.js 与 scanner.c,然后通过 tree-sitter generate 来生成可用的 parser。当前的实现非常粗糙,还有许多可以改进和修正的地方,等到积累了足够的测试和使用经验达到我的可用要求后我会把它放到一个正式的仓库里。
关于具体 tree-sitter parser 我可能并没有太多能教给读者的,这里只能简单讲讲我的整个编写过程。在放弃编写 moonbit parser 后我突然发现 Chrome 已经支持 WebGPU 了,于是参考入门教程写了个最基础的生命游戏。在使用 Emacs 编程过程中由于没有高亮写起来不怎么舒服,我就想着给 WGSL 写个 major-mode,然后找到了以下插件:
wgsl-ts-mode 这个插件是可用的,但是它与 tree-sitter parser 配合的似乎不怎么好,也许某些 query 没有处理好。我看了看 parser 的编写时间,离最新标准已经有差不多一年了,要不自己试试写一个吧。接着我又找到了 tree-sitter 官网列出的实现:
行吧,既然已经有过实现了,那我照着再做一个应该也不会很困难。于是我就以“官方”实现为主,另一个实现作参考开始编写我自己的 grammar.js。和文档推荐的「在编写规则同时编写并运行测试」实践不同,我一次性完成了整个 parser 的编写,随后不断调用 tree-sitter generate 来修正错误。 tree-sitter generate 首先会检查有没有 JS 语法错误,接着是 JS 运行时错误,最后才是 tree-sitter 对语法的检查。在 JS 语法检测过程中我发现我在编写规则的时候时不时会忘掉写 $ => ,而只有函数体了(笑)。修正这一部分倒是花了我不少时间。
写完整个 parser 后,我突然发现一年前的 WGSL 居然是没有 LR(1) 冲突的,现在的 WGSL 因为和上面提到的 C++ 中模板类似的原因存在 LR(1) 冲突,文档中给出了解决冲突的算法。但此时的我只是照猫画虎地抄了一遍实现,对 parsing 算法一窍不通,官方文档的寥寥数语对我的问题毫无帮助。此外,我还发现“官方”实现比 szebniok 的实现居然长了将近 1/3,仔细检查后给我整笑了,它是一点 prec 和 prec.right 都没用啊。这样生成出来的 parser 由于嵌套节点过多基本上没有实用性。
没办法,网上的资料太少加上官方文档太贫弱,我不得不从最基础的知识学起。在看过一些维基词条和博客,以及翻完《编译原理》前四章后,我对「乔姆斯基谱系」、「左递归」、「递归下降」、「产生式」、「LL」、「LR」、「上下文无关文法」、「下推自动机」等名词总算是有了一点认识,至少知道编译器还有前中后端的区分,编译器前端分语法分析和词法分析了。在了解这些知识后我对这两个 parser 实现有了新的理解,我照着语言标准,以 szebniok 实现为参考重新实现了一遍,这次的代码比最初的代码要短上 200 行,而且消除了许多不必要的规则嵌套。
改进 parser 后我又得面对 LR(1) 冲突的问题了,这时我想到了 C++ primer 上似乎有相似的例子,于是看了看 C++ 的语法,确实挺像的。我通过参考 tree-sitter-cpp 的实现解决了这个 LR(1) 冲突,总算是得到了一个基本可用的 tree-sitter-wgsl。
从最开始对编译原理到现在凭借先进工具搓了个 parser 出来,整个过程确实还是让我学到了不少(不过到现在我也没看过 LL 和 LR 的具体算法)。如果你有兴趣写个 tree-sitter parser 但又担心没有足够的知识的话,可以先尝试编写简单语言的 parser,然后在遇到较大障碍时回去学习相关知识,在现有 parser 实现如此之多的情况下我们不会缺少参考材料。
草,这篇文章写起来真是废了老劲了,从去年的 9 月份有想法以来一直断断续续写了几次,总算是在今年的 2 月份中旬完工了,中间差不多隔了 5 个月。虽然到现在我只会最简单的递归下降解析法,但这也不影响我写出个勉强能用的 parser 来,不得不感谢 parser 技术的进步。
我在寻找 tree-sitter 教程相关资料时偶然发现了一位程序员的博客,里面的杂谈还挺有意思,每年年底都有不同的感悟,但似乎在不断地低落下去(悲)。
去年新年我因为某些原因没有回去过年,今年春节的鞭炮味和腊肉味唤起了一些回忆,果然记忆是关联着身体的五感的,如果没有某些场景,对应的记忆可能就再也想不起来了。突然想起来高中结束整理杂物时把过去六七年的《读者》卖废纸了,一些稀奇古怪的夏令营和下水道文章现在看来确实乐,但那也是我的记忆的一部分。不断地忘掉过去还真是躲不掉的过程。
假如生活欺骗了你,你需要不断地殴打生活,这样你才不会被欺骗 — 续写《假如生活欺骗了你》,普希金加班发牢骚
我在写文章的时候喜欢用「我们」而不是「我」,这一方面可能是“我们”更加亲切,另一方面这文章确实也是写给未来的我的,不管是「人不能两次踏足同一条河流」还是「人不能踏足同一条河流」,一秒钟甚至一瞬间前的我应该已经不在了,但我确实继续了之前的任务,直到我把这篇文章写完。
这后记写的有点怪,不管怎么说也是新的一年了,祝各位新年快乐 :p