对于 Emacs 来说,创建子进程的基本函数只有三个,分别是 call-process, call-process-region 和 make-process 。前两个用来创建同步进程,最后一个用来创建异步进程。这一节我们主要介绍 call-process 和 call-process-region 以及它们衍生出的一些函数。
所谓同步,指的是 Emacs 会等待子进程结束,在此期间我们无法在 Emacs 中执行任何命令(除了 C-g )。相比于异步进程,我们不需要关心子进程与 Emacs 代码执行顺序关系,用起来比较容易,但是它不如异步进程灵活。同步子进程一般用来调用一些功能简单执行快速的命令行工具,比如 grep ,如果子进程执行时间过长会让 Emacs 看上去卡死了一样。
call-process 和 call-process-region 创建子进程时会将它们的 stdio 重定向到文件或者 Emacs,这也意味着我们在编写外部程序时,需要使用 stdio 即可。 call-process 主要处理输入来自文件的情况,而 call-process-region 负责输入来自 Emacs buffer 的情况,它们创建的子进程的输出可以是文件或 Emacs buffer。它们是使用 C 实现的,内部都调用了 call_process 这个函数,它位于 callproc.c 中,大约有 600 多行,非常难读。我选择直接放弃。
这是 call-process 的函数原型,它调用程序 PROGRAM 并等待它完成:
(call-process PROGRAM &optional INFILE DESTINATION DISPLAY &rest ARGS)函数的 docstring 很长,因为它要负责的功能很多。下面我结合文档和 docstring 简单介绍一下函数的功能和各参数的用法,其中的某些参数说明对其他函数也是适用的。
PROGRAM 是应用程序的名字,它可以是程序的绝对路径,也可以是相对路径。如果是相对路径的话 Emacs 会根据 exec-path 这个变量中的路径列表来查找程序的位置。如果 exec-path 中包含 nil 的话当前目录(指执行 call-process 时的 default-directory )也会放入搜索目录中,默认情况下 nil 不在 exec-path 中。我们可能最好不要使用 ./name 或 ../name 之类的相对路径来指定应用,应该直接使用应用名。
我们不用为 PROGRAM 加上 exe 后缀,Emacs 会使用 exec-suffixes 中的字符串作为 PROGRAM 的扩展名来查找可能的可执行文件名,在我的 Emacs 中它的值为 (".exe" ".com" ".bat" ".cmd" ".btm" "") 。
INFILE 参数用作程序输入的文件路径,若为 nil 则表示空设备(null device,也就是没有输入)。如果 INFILE 为相对路径,那么 Emacs 会以程序运行目录为准进行查找。
DESTINATION 指定了程序的输出文件,若为 nil 则忽略输出,为 t 则表示当前 buffer;为 buffer 或 buffer 名则指定输出到某 buffer;为 (:file FILE) 则指定输出到某文件;为 (REAL-BUFFER STDERR-FILE) 则可指定输出位置和错误输出位置。当形式为 (REAL-BUFFER STDERR-FILE) 时, REAL-BUFFER 可以是上面提到的任一情况, STDERR-FILE 可以是 nil (忽略错误输入), t (使用 REAL-BUFFER ) 和一个文件名字符串(输出到文件)。
如果我们将 DESTINATION 指定为 0 ,那么同步调用会立刻结束并返回 nil 而不等待进程结束,否则返回退出状态码或信号描述字符串。指定 DESTINATION 为 0 实际上就是异步调用,这个进程与 Emacs 是独立的,即使关闭 Emacs 进程也不会结束。
若 DISPLAY 为非空,当输出到达 buffer 时 buffer 会被重绘,否则不会。所谓重绘就是当新内容到达 buffer 时更新 buffer 的内容,也就是说该选项若为 nil ,只有在同步调用结束后 Emacs 才会在一些事件的触发下重绘 buffer。
最后的 ARGS 参数就是传递给子进程的命令行参数,每个字符串都会作为单独的命令行参数。
call-process 的返回值说明了进程终止的原因,0 表示正常结束,其他任何值都代表进程失败。如果进程以信号终止,那么 call-process 会返回描述信号的字符串。
使用下面的代码我们可以打开 Windows 记事本,在关掉之前 Emacs 是卡住的,不过我们可以通过 C-g C-g 杀掉它:
(call-process "notepad")
(比较奇怪的是,在 Windows 11 上无法通过 C-g C-g 杀掉 notepad,不过 Emacs 摆脱了阻塞状态)
使用以下命令我们可以调用 ping 命令,并且可以对比 DISPLAY 为 t 和 nil 时的不同效果:(如果你在 Windows 上设置了其他区域,可以考虑把 GBK 换成对应的编码)
(let ((coding-system-for-read 'gbk))
(switch-to-buffer (get-buffer-create "*yy*"))
(call-process "ping" nil "*yy*" t "127.0.0.1"))执行上面代码,你将看到如下过程:

如果我们将 t 改为 nil ,那么 Emacs 会卡住,并等到 ping 执行完毕才切换到 *yy* buffer,显示全部输出。这就比较清楚地说明了 DISPLAY 参数的作用。
下面我们编写一个输出文件内容到 Emacs buffer 的 Python 程序,它根据命令行参数决定读取行数:
import sys
num = int(sys.argv[1])
for i in range(0, num):
print(sys.stdin.readline(), end='')
用于读取的文件名为 1.txt,文件共十行,每行分别是 1,2,3…,直到 10。为了方便这里我把 py 和 txt 放在同一目录下,读者在执行以下代码时请在 py 或 txt 的 buffer 环境中:
(call-process "python" "1.txt" (get-buffer-create "*yy*") nil "1.py" "9")
如果正常运行,它会在 *yy* buffer 中打印 1-9 并间隔以换行。这里需要强调是 call-process 的 ARGS 需要分开,如果我们传递的是 "1.py 9" 的话,这个字符串会成为一整个命令行参数,Python 会报错超出列表引用范围。
最后需要说明的是当 DESTINATION 为 0 的情况,这个时候就等价于异步调用了, call-process 会立刻返回,读者可以给上面的 notepad 加上 DESTINATION 参数试试:
(call-process "notepad" nil 0)
关于 call-process 就说到这里了,还剩 DESTINATION 的 (:file FILE) 和 (REAL-BUFFER STDERR-FILE) 情况没有介绍,我们把它留到下一节。
大多数情况下我们是不需要用上 call-process 的全部参数的,Emacs 为我们提供了一些调用 call-process 的函数,使用起来更加方便:
process-file,会使用 file handler 对路径做一些处理process-lines,使用命令行参数调用程序并返回字符串列表process-lines-ignore-status,与process-lines类似,但在程序异常结束时不会引发错误
由于我对 file handler 不怎么熟悉,读者若有兴趣的话可以去看一看 file handler 的文档。 process-lines 这个函数在只需要向程序传递命令行参数,且需要将程序的输出按行分割时非常有用。它的原型如下:
(process-lines PROGRAM &rest ARGS)
PROGRAM 和 ARGS 参数的含义和 call-process 中的一致。对下面这个 Py 脚本调用 process-lines ,我们可以获取从 0 开始的自然数字符串:
import sys
num = int(sys.argv[1])
for i in range(0, num):
print(i)(process-lines "python" "1.py" "10")
=> ("0" "1" "2" "3" "4" "5" "6" "7" "8" "9")
call-process-region 为我们提供了更方便的进程调用方法,它允许我们将 buffer 中的内容作为子进程的输入内容。这是它的函数原型:
(call-process-region START END PROGRAM &optional DELETE BUFFER DISPLAY &rest ARGS)
START 和 END 是当前 buffer 的两个位置, call-process-region 会把位于两者之间的文本发送给子进程。 PROGRAM , DISPLAY 和 ARGS 参数的含义与 call-process 一致, BUFFER 参数就是 call-process 的 DESTINATION 。
如果 START 为 nil 就表示使用整个 buffer 内容作为子进程输入,此时 END 会被忽略;如果 START 为字符串,字符串将作为子进程的输入, END 同样会被忽略。 DELETE 参数用来决定是否删除 buffer 中从 START 到 END 部分的内容,若为 t 则删除。当我们需要使用子进程输出内容替换输入内容时这个参数很有用。
下面的调用分别演示了 START 为 nil 和字符串的情况:
import sys
s = sys.stdin.read()
print (s + '\n' + s, end='')(call-process-region nil nil "python" t t nil "1.py")
(call-process-region "Hello" nil "python" nil t nil "1.py")
前一命令会在 buffer 中插入两倍的原内容,后一条会在 buffer 中插入 "Hello\nHello"(不要在有用的 buffer 中执行这些命令)。这里需要注意的是,当 START 为字符串时, DELETE 参数不能是 t ,否则会出现错误:
Debugger entered--Lisp error: (wrong-type-argument integer-or-marker-p "Hello")
call-process-region("Hello" nil "python" t t nil "1.py")
Emacs 为我们提供了 base64 编码和解码功能( base64-encode-region 和 base64-decode-region ),我们也可以使用 Python 脚本来实现:
import base64
import sys
data = sys.stdin.read()
if len(sys.argv) == 1:
print((base64.b64encode(data.encode())).decode(), end='')
else:
print((base64.b64decode(data.encode())).decode(), end='')下面是配套的 elisp 命令,方便起见我假设命令执行的位置和 Py 文件在同一路径下:
(defun yy-b64encode-region (beg end)
(interactive (list (region-beginning)
(region-end)))
(call-process-region beg end "python" t t nil "1.py"))
(defun yy-b64decode-region (beg end)
(interactive (list (region-beginning)
(region-end)))
(call-process-region beg end "python" t t nil "1.py" "a"))
在上一节中我们没有对 DESTINATION 为 file 或 (dst err) 的情况进行介绍,这里做个补充。如果我们想将 base64 编码后的结果存入文件可以这样做:
(call-process-region "yy" nil "python" nil '(:file "1.txt") nil "1.py")
执行此命令后,你可以在当前目录下的 1.txt 文件中看到 eXk= 。我们使用下面的 Python 程序分别测试一下 (dst err) 中的 err 为 nil, t 和 file 时的情况:
import sys
sys.stdout.write('hello')
sys.stderr.write('world')(call-process-region "" nil "python" nil '(t nil) nil "1.py")
(call-process-region "" nil "python" nil '(t t) nil "1.py")
(call-process-region "" nil "python" nil '(t "1.txt") nil "1.py")
(call-process-region "" nil "python" nil '((:file "1.txt") nil) nil "1.py")在上面的代码中,第一行会在当前位置输出 "hello",第二行会在当前位置输出 "worldhello",第三行会在当前位置输出 "hello",在 1.txt 中输出 "world",第四行会在 1.txt 中输出 "hello",而 "world" 没有被输出。
通过 shell-command 我们可以在 shell 环境中执行命令,不过 Emacs 也为我们提供了其他的一些函数:
call-process-shell-command,在 shell 中执行COMMAND(call-process-shell-command COMMAND &optional INFILE BUFFER DISPLAY)
process-file-shell-command,类似call-process-shell-command,但调用process-filecall-shell-region,使用region作为 shell 命令COMMAND输入(call-shell-region START END COMMAND &optional DELETE BUFFER)
shell-command-to-string执行 shell 命令COMMAND,并返回命令的输出字符串(shell-command-to-string COMMAND)
以 shell 或 shell-command 作为前缀后缀的这些函数的执行环境是 shell,这也意味着我们可以使用 shell 的一些命令而不仅仅是应用程序,比如 dir , tree 等等:
(call-process-shell-command "dir" nil t)
(shell-command-to-string "dir")
相比于通过 ARGS 指定多个命令行参数, shell 函数只有一个参数 command ,这就意味着我们需要一次性写好整个命令,同时还要注意到 shell 的字符转义问题,Emacs 为我们提供了一些处理这个问题的函数:
shell-quote-argument,返回符合 shell 语法的参数字符串split-string-shell-command,将字符串分割为由单个参数组成的列表split-string-and-unquote,将字符串分割,可选择分隔符combine-and-quote-strings,将字符串列表组合成单个字符串
在 Windows 的 cmd 中,我们可以将 " 转义为 """ ,不过 Emacs 的转义我不太能看懂,虽说能用就是了:
(shell-quote-argument "\"123\"") => "^\"\\^\"123\\^\"^\""
(princ "^\"\\^\"123\\^\"^\"") => ^"\^"123\^"^"
;; example from elisp manual 39.2
(concat "diff -u "
(shell-quote-argument oldfile)
" "
(shell-quote-argument newfile))
简单问了下 ChatGPT,其他一些字符,比如 &, <, >, | 和 % 都需要转义,我们只需要在必要的时候调用 shell-quote-argument 就行了,不用去记这些规则。
split-string-shell-command 以空格作为分隔符将一条命令拆分成几个字符串,它只负责拆分。它会去掉单引号和双引号,但使引号范围内的内容作为一整个字符串:
(split-string-shell-command "python 1.py 1.txt") => ("python" "1.py" "1.txt")
(split-string-shell-command "\"1.txt 2.txt\"") => ("1.txt 2.txt")
(split-string-shell-command "'1.txt 2.txt'") => ("1.txt 2.txt")
split-string-and-unquote 和 combine-and-quote-string 是一对函数,满足以下关系:
(split-string-and-unquote (combine-and-quote-strings strs)) == strs
相比 split-string-shell-command , split-string-and-unquote 允许我们指定分隔符,它默认是 \s-+ 。与 split-string-shell-command 类似,它也会保证引号内容不被分开。
(split-string-and-unquote "python \"1.txt 2.txt\"") => ("python" "1.txt 2.txt")
(combine-and-quote-strings '("python" "1.txt 2.txt")) => "python \"1.txt 2.txt\""
(split-string-and-unquote "1$2$3" "\\$") => ("1" "2" "3")
按照文档的说法, split-string-shell-command 和 split-string-and-unquote 的主要用途是将来自 minibuffer 的用户输入切分为参数列表后来作为 make-process, call-process 或 start-process 的命令行参数。需要注意的是, combine-and-quote-strings 不会负责对字符串进行转义,我们需要调用 shell-quote-argument 。
到了这里就基本完成了对在 Emacs 中创建和使用同步子进程的介绍,相比异步进程它要简单许多,没有那么多的额外概念,毕竟调用完成后进程就结束了。下面让我们学习一下如何创建和使用异步子进程。
你应该注意到了上面在调用 ping 命令时的 coding-system-for-read ,这是因为在中文编码环境下 ping 的输出编码是 GBK,如果直接调用的话汉字部分将会是乱码。文档中也建议我们在处理子进程 IO 时明确指定编码:
if the coding system chosen for decoding output is undecided, meaning deduce the encoding from the actual data, then redisplay sometimes cannot continue once non-ASCII characters are encountered.
39.3 Creating a Synchronous Process
Coding systems such as undecided, which determine the coding system from the data, do not work entirely reliably with asynchronous subprocess output. This is because Emacs has to process asynchronous subprocess output in batches, as it arrives. Emacs must try to detect the proper coding system from one batch at a time, and this does not always work. Therefore, if at all possible, specify a coding system that determines both the character code conversion and the end of line conversion—that is, one like latin-1-unix, rather than undecided or latin-1.
进程通信不可避免地涉及到编码和解码,这里我会介绍一些一般性的编码知识,由于 Windows 上的编码环境比 Linux 要复杂很多,这是非常有必要的。几个月前我尝试使用 jsonrpc 但没有成功,现在想来应该是编码出现了问题。老实说我也是花了很多时间看了很多 blog 才逐渐对字符集和编码有了一点点认识,如果你对编码和字符集感到很生疏的话,等碰到相关问题或者过了一段时间后就能明白了。
几年前在 Windows 的 VS 上入门 C++ 时,有一件事我一直非常奇怪,wchat_t 类型的字符串为啥能在命令行中输出中文。现在 ChatGPT 出来了,这个很难在搜索引擎中描述清楚的问题终于得到了解答:
为什么我在 C 源代码中写汉字也能被编译,并且当我将它作为 wchar_t 类型字符串在 Visual Studio 中输出时能看到汉字
在 C 语言中,字符编码和字符集处理是由编译器和运行时库负责的。C 语言标准本身并没有规定特定的字符编码,而是由编译器和运行时库根据环境进行处理。
当你在 C 源代码中写汉字,编译器和运行时库会根据当前环境的字符集进行处理。在大多数情况下,Windows 操作系统默认使用的字符集是 GBK(或者叫 GB2312),其中包含了汉字等字符。因此,当你在 C 源代码中写入汉字时,编译器和运行时库会将它们视为 GBK 编码的字符,并进行正确的处理。
在 Visual Studio 等开发环境中,当你将 wchar_t 类型的字符串输出到控制台或其他输出终端时,运行时库会根据当前环境的字符集进行解码和显示。由于 Windows 默认使用的是 GBK 字符集,所以 wchar_t 类型字符串中的汉字会被正确显示。
需要注意的是,虽然在当前环境中能够正确显示汉字,但是这种处理方式可能在其他环境中不适用。在跨平台开发或处理不同字符集的环境中,需要谨慎处理字符编码,以确保文本的正确显示和处理。
读者可以试试在 Emacs 中使用 UTF-8 和 GBK 的情况下分别保存以下代码并使用 MSVC 编译运行(Emacs 中可以使用 revert-buffer-file-with-coding-system 或 C-x RET f 来重置 buffer 编码):
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("我");
return 0;
}下面是源代码分别在 GBK 编码时和 UTF-8 编码时编译并运行的结果:
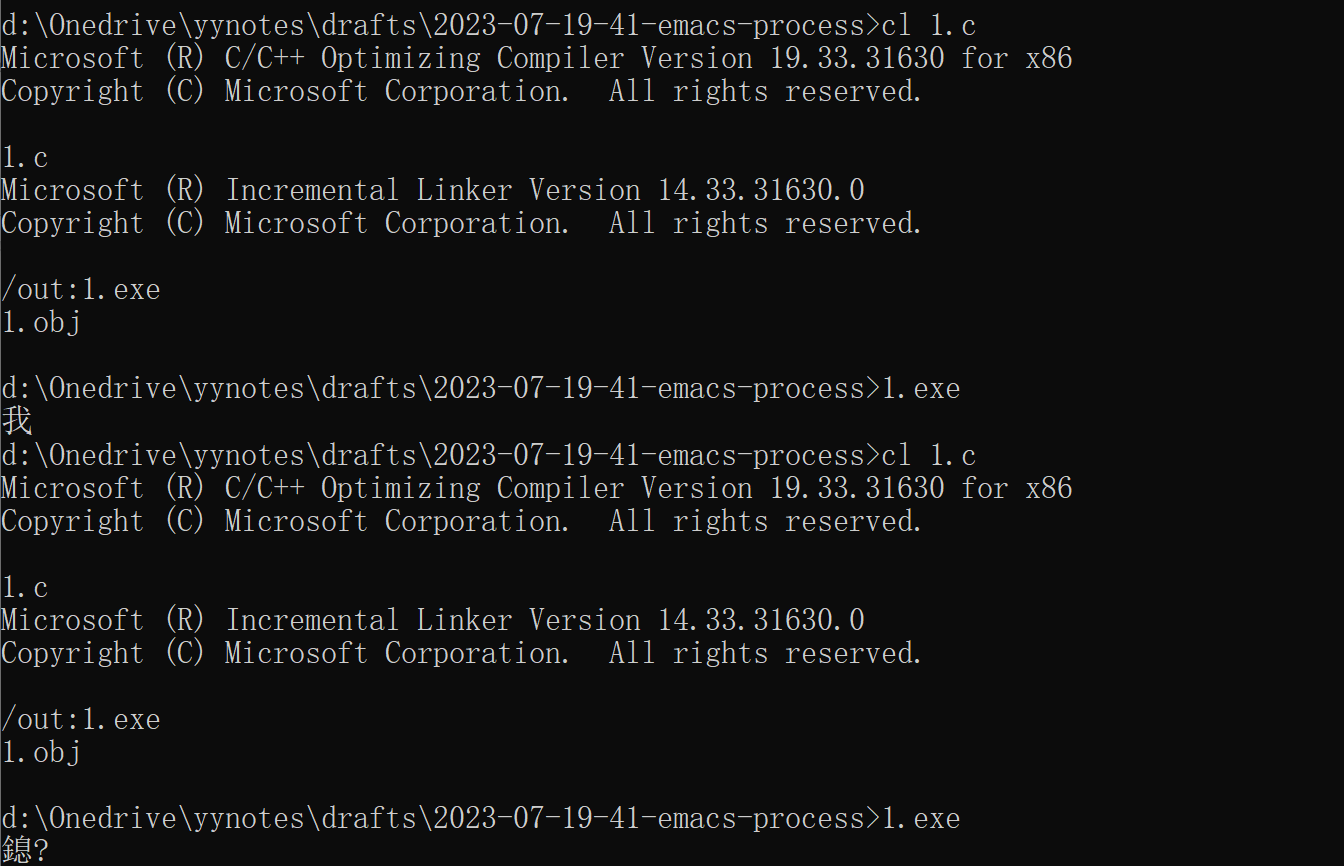
嗯?这个奇怪的字符是什么?出现这个“乱码”的原因是命令行窗口根据 UTF-8 编码在 GBK 中查到的对应字符。 鎴 的 GBK 编码是 E688 ,而 我 的 UTF-8 编码是 0xE6 0x88 0x91 ,可见它的前两个字节正对应的是 鎴 的 GBK 编码, 0x91 在 GBK 中是双字节编码的开头,所以命令行窗口会输出 ? 表示无效。可见 C 语言根据不在意字符串里面是什么东西,只要是字节就行。
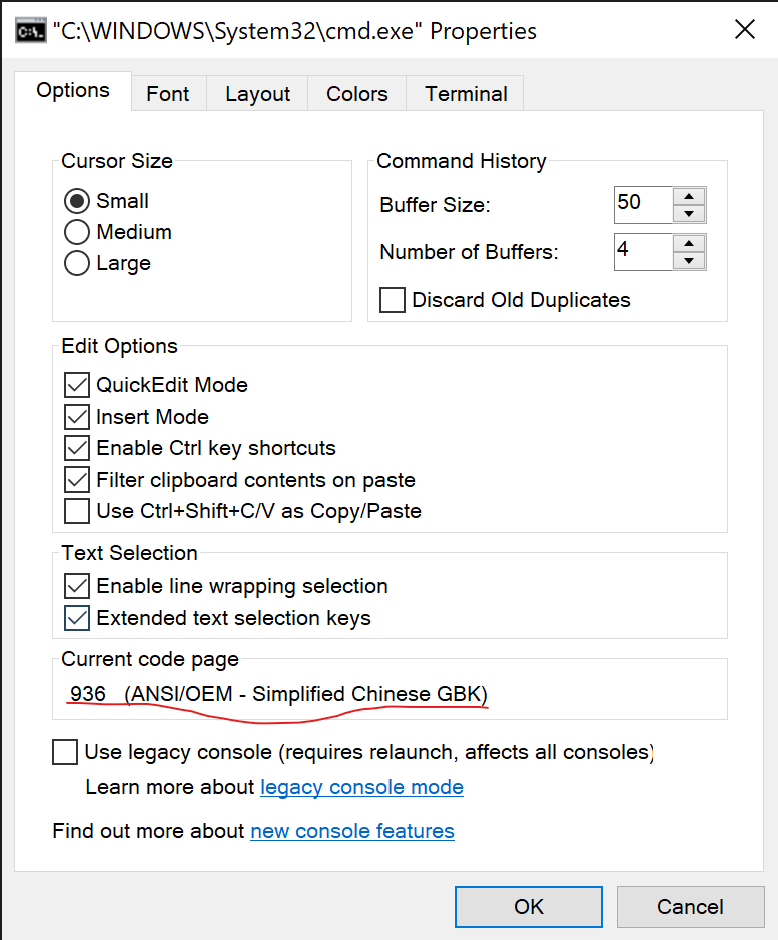
当然能得到上面的结果是因为我处在中文计算机环境中,通过命令行窗口的设置可以看到当前的代码页(codepage)是 936,也就是 GBK:
如果我们在 cmd 中使用 chcp 65001 将代码页修改为 UTF-8 的话,对 UTF-8 编码的源代码编译执行输出结果将能够正确显示 我 :(如果此时还显示 ? 则需要修改当前字体,此时可能使用了英文字体,修改为仿宋 FangSong 即可,我这里使用的是 SimHei):
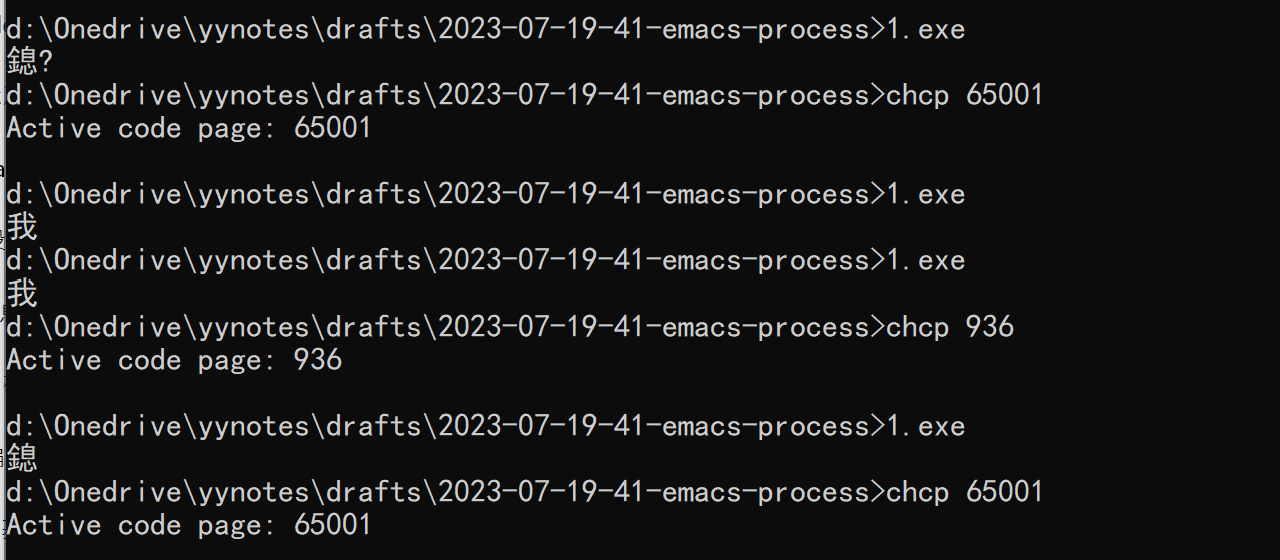
在 Windows11 中, Win+R cmd 会启动 Windows Terminal,打开属性页可能并不怎么方便,这里我推荐使用 Win+R conhost ,这样就可以看到经典黑框框了。
Windows 上的代码页是什么
在 Windows 操作系统上,代码页(Code Page)是指用于字符编码和字符集处理的一种配置。Windows 支持多种代码页,每个代码页对应着一种字符编码方式,用于支持不同语言和字符集的处理。
默认情况下,Windows 系统的代码页是根据所使用的区域和语言设置来自动选择的。在不同的区域和语言环境下,可能会使用不同的代码页来处理字符编码。
在命令行中,可以使用 chcp 命令来查看当前的代码页设置。
代码页的设置可能会影响字符的显示和解析。如果你在 C 程序中输出文本到命令行或控制台,代码页的设置会影响文本的显示方式。如果你希望在命令行中正确显示某种字符编码的文本,可能需要根据需要设置合适的代码页。
这里似乎可以提一嘴 <locale.h> ,不过和本文关系不是很大,读者若有兴趣就去问问 ChatGPT 吧(笑)。
上面我们已经见识到了 我 的 UTF-8 编码: 0xE6 0x88 0x91 。从字面意思上来看“编码”很容易理解,把东西编成一串码嘛。对于 C 语言的初学者来说除了 ASCII 编码外另一个比较熟悉的编码可能是 EBCDIC,不过现在可能不怎么常用了。得益于 Emacs 对编码变态般的支持,我们可以通过 encode-coding-string 转换编码:
(encode-coding-string "Hello world" 'ebcdic-us)
=> "\310\205\223\223\226@\246\226\231\223\204"
H 在 EBCDIC 中的编码是 C8 ,八进制表示就是 #o310 。读者可以在维基找到 EBCDIC 中各字符的编码。
你可能知道“我”的 Unicode 值是 U+6211 ,但这是它的码点(code point)而不是编码,Unicode 是一个字符集而不是编码方案,所谓字符集就是字符的集合,下面是来自维基百科的对 Unicode 的介绍:
Unicode 伴随着通用字符集 ISO/IEC 10646 的标准而发展,同时也以书本的形式对外发表。Unicode 至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为 2022 年 9 月公布的15.0.0,已经收录超过 14 万个字符(第十万个字符在 2005 年获采纳)。Unicode 标准不仅仅只是为文字指定代码。除了涵盖视觉上的字形、编码方法、标准的字符编码资料外,联盟官方出版品还包含了关于各书写系统的细节及呈现方式,如规范化的准则、拆分、测序、绘制、双向文本显示、书写方向、字符特性(如大小写字母)等等。此外还提供参考资料和视觉图像,以帮助开发者和设计师正确应用标准。
对于某一字符集可以有多种不同的方案,不严谨地说 ASCII 和 EBCDIC 就是 26 个英文字符的两种编码方案。常见的 Unicode 编码方案有 UTF-8,UTF-16,UTF-32,其中 UTF-8 最为流行。
我并不是非常了解字符集规范之类东西,关于字符集和编码就说到这里了,再推荐几篇文章吧:
在 Emacs 中,如果我们想要知道某个字符的 Unicode 码是多少,我们只需要在字符的前面加上 ? ,然后将光标移至字符后面按下 C-x C-e 即可:
?我 => 25105, #x6211对字符,Emacs 直接使用了 Unicode 码点来作为字符的数值,这也就像上面展示的那样,Elisp Manual 的 34.1 节是这样描述的:
Emacs extends this range with codepoints in the range #x110000..#x3FFFFF, which it uses for representing characters that are not unified with Unicode and raw 8-bit bytes that cannot be interpreted as characters. Thus, a character codepoint in Emacs is a 22-bit integer.
但这并不是 buffer 或字符串中的字符表达,为了节省空间 Emacs 对它们使用了一种可变长度的字符表示,根据不同字符长度可以为 1 到 5 个字节。这一种表示被叫做 multibyte ,除了它还有一种叫做 unibyte 的表达,从名字来看这种字符的范围只能是一个字节,事实也确实如此,它可以表达和存储 0~255 之间的数值,可以用来处理二进制数据或编码后的文本,不过 Emacs 不太建议我们在除此之外的场景使用它。 multibyte 和 unibyte 就是 Emacs 中的唯二字符串或 buffer 内容表示方式了, multibyte 使用的是扩展后的 UTF-8:
This internal representation is based on one of the encodings defined by the Unicode Standard, called UTF-8, for representing any Unicode codepoint, but Emacs extends UTF-8 to represent the additional codepoints it uses for raw 8-bit bytes and characters not unified with Unicode.
Emacs chooses the representation for a string based on the text from which it is constructed. The general rule is to convert unibyte text to multibyte text when combining it with other multibyte text, because the multibyte representation is more general and can hold whatever characters the unibyte text has.
读者可以阅读 Manual 34.3 节来了解一些对 multibyte 和 unibyte 相互转化的函数,这里我就不介绍了。对于 buffer,我们可以通过 toggle-enable-multibyte-characters 这个命令来控制当前 buffer 使用 multibyte 还是 unibyte。
内部统一的字符表示也就意味着 Emacs 只需要在读取和写入文件时分别对文件中的字节进行解码和编码即可。Emacs 内部支持了一大堆的字符集,标识字符集的符号存储在 charset-list 中:
(length charset-list) => 203
但光有字符集是不够的,我们在读写文件时会使用某种编码方案来解码和编码。所有的编码系统存储在 coding-system-list 中:
(length coding-system-list) => 1071
(coding-system-p 'utf-8) => t
(coding-system-p 'utf-8-dos) => t
(coding-system-p 'utf-8-unix) => t
(coding-system-p 'utf-8-mac) => t
如果你简单检查一下这个列表,你能看到需要符号都有 unix, mac 和 dos 后缀,这是为了处理三种操作系统下不同的换行约定,Unix 下是 \n ,DOS/Windows 下是 \r\n ,早期的 MacOS 下是 \r ,现在是 \n 。在这些编码中比较特殊的有这些:
raw-text不进行编解码,按照文件的原始字节在 buffer 中显示内容,一般用于二进制文件no-conversion(或binary)等价于raw-text-unix,使用\n作为换行标记utf-8-emacs直接使用 Emacs 的内部表示undecided使用启发式方法来确定编码
Emacs Manual 在 34.10.5 一节描述了一些用于选择默认编码的选项。和本文关系比较大的可能是 process-coding-system-alist, network-coding-system-alist 和 default-process-system :
process-coding-system-list指定了匹配某些名字的应用应该使用的编码,默认只有 plink 和 comproxy ,前者是 tramp 需要的连接程序,后者是 Emacs 在 Windows 上经过简单包装的 cmd,所有shell-command相关命令会在内部使用它process-coding-system-alist (("[pP][lL][iI][nN][kK]" undecided-dos . undecided-dos) ("[cC][mM][dD][pP][rR][oO][xX][yY]" undecided-dos . undecided-dos))我们可以通过
set-process-coding-system来修改进程的编码系统network-coding-system-alist,匹配网络连接名的编码,默认为nil,如果pattern是数字的话匹配的将是端口,是正则则匹配service namedefault-process-coding-system,子进程默认使用的编码系统,默认为(undecided-dos . undecided-unix)
在上面的例子中,我使用 coding-system-for-write 指定了子进程的输出编码,我们也可以使用 coding-system-for-read 指定进程的输入编码,它们的优先级非常高。如果我们在创建子进程时使用它们指定了编码(而不是 :coding 参数),那么子进程会在编码被修改之前一直使用。
在 34.10.7 节中提到了一些显式编码的函数,似乎并不怎么常用,这里简单列举一下:
encode-coding-region将 region 内的文本使用某一编码系统编码decode-coding-region对 region 内的文本解码encode-coding-string将字符串按某编码系统编码,并返回 unibyte 字符串作为结果decode-coding-string解码字符串
异步子进程与 Emacs 是并行的,这样我们不至于在 Emacs 等待进程结束时什么也做不了。但这也为我们管理子进程带来了一些挑战,毕竟在使用同步子进程时我们只需要等待进程结束时的输出而已,作为用户的我们并不能 直接 立刻处理来自异步子进程的输出,这是因为我们并不能准确知道异步进程的输出 何时 会到达,如果干等的话那又回到同步的情况了。好在 Emacs 是知道的,它提供了一种回调机制来处理异步进程的输出。
根据 Evolution of Emacs Lisp 中的说法,异步进程是 Emacs 为数不多并发能力的来源(另一个是 timer),掌握好如何在 Emacs 中使用异步子进程是绝对有必要的。这一章主要是介绍如何创建异步子进程,以及介绍 Emacs 与子进程之间的通信机制。
这是个非常复杂的函数,某些参数都得花一小节来讲清楚,原本我打算最后再介绍它,不过写成总分式也不错。 make-process 的函数原型只是一个简单的 (&rest ARGS) ,所有参数都需要用关键字符号指定:
:name,指定进程的名字,如果这个名字已经存在了,那就会在名字的末尾加上<num>,num从 1 开始依次递增。这样可以保证每个进程的名字都是唯一的:buffer,指定用于进程输出的 buffer,若为 nil 则表示进程不与任何 buffer 关联:command,指定命令行参数,它是一个字符串列表,首元素必须是可执行文件的名字- 若首元素是 nil,那么 Emacs 会打开一个
pty并将 IO 与:buffer关联,此时将忽略剩余的参数
- 若首元素是 nil,那么 Emacs 会打开一个
:coding,指定子进程 IO 编码,形式为(decoding . encoding),decoding对子进程到 Emacs 的输出解码,encoding用于编码 Emacs 发送给子进程的数据,encoding也用于命令行参数的编码- 若不指定
:coding则使用默认编码default-process-coding-system
- 若不指定
:connection-type,指定连接类型,可用类型包括pty或pipe,前者表示使用 pseudoterminal,后者使用管道- 若指定为
nil则根据process-connection-type选择,该变量为t,默认为pty。若指定:stderr则连接类型必为管道 - MS-Windows 不支持
pty连接
- 若指定为
:noquery,指定子进程的 query-flag:stop,若指定则必须为nil,一个向后兼容的选项,尽量不要用它:filter,指定 process filter,若为nil则使用默认 filter:sentinel,指定 process sentinel,若为nil则使用默认 sentinel:stderr,指定进程的 stderr 输出。可以是 buffer 或使用make-pipe-process创建的管道进程。若为nil则错误输出与标准输出混合file-handler,若为非空则根据当前 buffer 的default-directory查找一个 file handler,并使用该 file handler 创建进程
在上面的参数中, :name, :buffer, :command, :coding 指定了子进程的一些基础信息, :filter 和 :sentinel 和进程与 Emacs 的 IO 相关,其余参数也许不用太过关注。
由于现在还没有进一步的介绍,这里我只能举个最简单的例子了:
(make-process :name "yy"
:command '("notepad"))
我们可以通过 list-processes 来找到这个进程, *Process List* 中会显示进程名字,PID,状态,buffer 等信息。在 *Process List* 中通过 d 键我们可以 删除 某个进程,它会调用 delete-process 。

下面,让我们在对各参数的相关功能介绍中慢慢了解 make-proecess 的用法。
通过调用 process-send-string ,我们可以将字符串发送给子进程,通过 process-send-eof 我们可以单独发送 EOF 。以下 Python 程序将输入转化为数字加一后输出:
import sys
print ('hello')
sys.stdout.flush()
tbl = {'一' : 1, '二' : 2, '三' : 3, '四' : 4, '五' : 5,
'六' : 6, '七' : 7, '八' : 8, '九' : 9, '十' : 10 }
while True:
print('---')
a = input()
b = tbl[a]
print(b+1)
sys.stdout.flush()
使用下面的代码,我们可以将一到十的汉字发送给子进程,并在 *a* buffer 中找到将数字加一后的输出:
(make-process
:name "yy"
:buffer (get-buffer-create "*a*")
:coding 'gbk
:command '("python" "1.py"))
(process-send-string "yy" "十\n")注意这里我选择 gbk 编码,这是将 Windows 设置为中文时默认使用的编码。如果我们想避免掉语言环境导致的需要选择编码,我们就得自己编码和解码了:
import sys
sys.stdout.buffer.write('hello\n'.encode(encoding='UTF-8'))
sys.stdout.flush()
tbl = {'一' : 1, '二' : 2, '三' : 3, '四' : 4, '五' : 5,
'六' : 6, '七' : 7, '八' : 8, '九' : 9, '十' : 10 }
while True:
sys.stdout.buffer.write('---\n'.encode(encoding='UTF-8'))
sys.stdout.flush()
n = sys.stdin.buffer.read(1)
a = sys.stdin.buffer.read(int.from_bytes(n, "big")).decode(encoding='UTF-8')
b = tbl[a]
sys.stdout.buffer.write((str(b+1) + '\n').encode(encoding='UTF-8'))
sys.stdout.flush()(make-process
:name "yy"
:buffer (get-buffer-create "*a*")
:coding '(utf-8 . binary)
:command '("python" "1.py"))
(process-send-string "yy" (unibyte-string 3))
(process-send-string "yy" (encode-coding-string "七" 'utf-8))
现在的 :coding 参数表示发送时使用 binary 原样按字节发送,接受时使用 UTF-8。由于接受的是字节流而不是带换行的文本流,我选择使用第一个字节来表示接下来接受的字节数量,随后在读取后进行 UTF-8 解码得到汉字。在使用 Elisp 代码时需要注意首先发送 3 (这是一般汉字在 UTF-8 中的编码长度),然后再发送汉字编码。
除了 process-send-string 外,我们也可以使用 process-send-region 来将选中的内容发送到子进程,比如以下程序可以统计某一行的 region 内的字符个数:
import sys
s = sys.stdin.readline()
print(s)
print(str(len(s)-1))
sys.stdout.flush()(make-process
:name "yy"
:buffer (get-buffer-create "*a*")
:coding 'gbk
:command '("python" "1.py"))
(defun yy-cnt (beg end)
(interactive (list (region-beginning)
(region-end)))
(process-send-region "yy" beg end)
(process-send-string "yy" "\n"))懒得录 gif 这里就不放图了,读者(以及之后的我)想看效果的话就自己试一试吧。
在上一节的例子中,来自子进程的输出都到达了 *a* 这个 buffer 中,我们只是看着这些输出到达而已。如果想利用这些输出的话,我们当然可以把其中的字符串复制到别处然后干点什么,但 Emacs 也提供了机制来将这个过程自动化,它在 Emacs 中被叫做 process filter。在此之前,我们先来简单研究一下进程对象用于接收子进程输出的 buffer。
在异步子进程关联 buffer 后,我们可以通过 process-buffer 来获取这个 buffer,或者是通过 buffer 来反查进程:
(make-process
:name "yy"
:buffer (get-buffer-create "*a*")
:command '(nil))
(process-buffer (get-process "yy")) => #<buffer *a*>
(get-buffer-process "*a*") => #<process yy>
如果有多个进程关联了同一个 buffer, get-buffer-process 可能会返回最近创建的那个,但最好不要依赖这个没有标准化的结果( currently, the one most recently created, but don’t count on that )。除了调用 delete-process 或在 *Process-List* 中按下 d 来删除进程,我们还可以直接 kill 掉这个与进程关联的 buffer 来删除进程。
除了在创建进程对象时指定 buffer 外,我们也可以对进程对象调用 set-process-buffer 来指定与之关联的 buffer。如果我们没有为异步进程指定 buffer 的话,它的输出不会到达 Emacs。但这个输出不会被丢弃,文档是这样描述的:
you can safely create a process and only then specify its buffer or filter function; no output can arrive before you finish, if the code in between does not call any primitive that waits.
只要我们不让 Emacs 等待 ,子进程的输出不会无故消失,它会等待我们完成 process buffer 和 process filter 的设置。这也就意味着我们可以在创建完异步进程后立刻设置 buffer 或 filter,下面的 Python 代码会输出 Hello World,即使我们在创建进程时没有指定 buffer,它也能够正常输出 Hello World 到当前 buffer:
print('hello world')(progn
(make-process
:name "yy"
:command (list "python" "1.py"))
(set-process-buffer (get-process "yy") (current-buffer)))
当然了,如果我们一个一个按 C-x C-e 对 make-process 和 set-process-buffer 分别求值就不行了,在两次按键间隔之间 Emacs 已经在 等待 了,我会在下下节说明 Emacs 的等待时机。
当 Emacs 收到进程的输出时,它会调用进程关联的 filter 函数来处理。在上面的例子中我们没有指定 filter,Emacs 为我们使用了默认的 filter,也就是将输出插入到进程 buffer 的末尾,这样可以保证原内容的顺序输出。
filter 函数需要接受两个参数:进程对象和接收到的字符串,文档中给出的默认 filter 实现大致如下,它首先需要判断 process buffer 是否存在,然后保存当前 buffer 并在 process buffer 中插入内容后更新 process mark 。如果 point 位置与 prcess mark 重合的话,最后还需要更新 point :
(defun ordinary-insertion-filter (proc string)
(when (buffer-live-p (process-buffer proc))
(with-current-buffer (process-buffer proc)
(let ((moving (= (point) (process-mark proc))))
(save-excursion
;; Insert the text, advancing the process marker.
(goto-char (process-mark proc))
(insert string)
(set-marker (process-mark proc) (point)))
(if moving (goto-char (process-mark proc)))))))
上一节忘了说 process-mark ,这里简单提一下。 process-mark 用于获取进程的 marker,它用来标记来自进程的输出应该插入到 buffer 的位置。如果进程没有 buffer,它会返回一个指向 nowhere 的 marker。输入并不是自动插入到 process marker 的位置,还得我们在 filter 函数中显式使用它。
我们可以通过 process-filter 获取某个进程的 filter 函数,也可以通过 set-process-filter 来设置 filter。若 set-process-filter 的 filter 参数为 nil 那么进程会使用默认的 filter;若 filter 参数为 t ,那么 Emacs 会停止接收来自进程的输出。
需要注意的是,Emacs 每一次接收到的数据可以是任意大小的,这也意味着 200 字符的输出可能是分 5 次每次 40 字符到达 Emacs。不知你听说过“TCP 粘包”这个名词没有,虽然这是个错误的名词,但 Emacs 在处理来自异步进程的输出时也可能碰到这个问题:多个 printf 或 print 可能合并为一条,一条 print 也可能拆分为多条。在编写 filter 函数时我们不能假设收到的字符串是一条完整的 print 输出,我们可能需要额外的操作来保证接收到了完整的数据。jsonrpc.el 中的 jsonrpc--process-filter 被用于处理来自子进程的 json 数据,它通过读取数据头来获取接下来需要接受的数据字节数,是个不错的 filter 例子。
The output to the filter may come in chunks of any size. A program that produces the same output twice in a row may send it as one batch of 200 characters one time, and five batches of 40 characters the next. If the filter looks for certain text strings in the subprocess output, make sure to handle the case where one of these strings is split across two or more batches of output; one way to do this is to insert the received text into a temporary buffer, which can then be searched.
filter 函数的 caller 不是我们而是 Emacs,如果在 filter 函数执行期间我们想要终止执行的话,我们可以在 filter 函数内将 inhibit-quit 设置为 nil ,这样就可以通过 C-g 来退出执行。filter 中出现的错误不会触发 debugger,我们可以通过设置 debug-on-error 为非空来让错误正常触发从而更方便地调式 filter。
这是一个令我困惑已久的问题,文档中是这样描述 Emacs 接受输出的时机的:
Output from a subprocess can arrive only while Emacs is waiting: when reading terminal input (see the function waiting-for-user-input-p), in sit-for and sleep-for (see Waiting for Elapsed Time or Input), in accept-process-output (see Accepting Output from Processes), and in functions which send data to processes (see Sending Input to Processes). This minimizes the problem of timing errors that usually plague parallel programming.
39.9 Receiving Output from Processes
Output from asynchronous subprocesses normally arrives only while Emacs is waiting for some sort of external event, such as elapsed time or terminal input.
文档中说明了输出何时会到达 Emacs:等待用户输入时,调用 sit-for 或 sleep-for 时,调用 accept-process-output 时和向进程发送数据时。最初看到这个描述时我以为只有在显式调用等待函数时 Emacs 才能接受到子进程的输出,这让我瞬间失去了对异步子进程的兴趣,既然得手动等待进程输出那我要你干啥?现在回来再看我忽略了 等待用户输入 这个异步输出触发的大头,要说的话 Emacs 几乎无时不刻处于 idle 状态,用户输入以及处理用时只占整个 Emacs 运行时间的一小部分,所以异步输出的接收对 Emacs 来说并不是一个问题。
在我困惑的时候我在 reddit 和 github 上找到了一些资料,希望能对你有所帮助:
What that means here is that the filter function of the process object can be called at these times. IOW, "output arrives" when it is handed to some Lisp function that your Lisp program can use to get at that output.
And yes, "functions that send data" are the process-send-* functions documented in that section.
Emacs never "pauses execution" (if you forget about Lisp threads for a moment, and consider only the main Lisp thread). So there's no "yield". When Emacs finishes the command it is running, it returns to the main loop, where it can run timers, check for input from any of the possible sources (including from sub-processes), etc. If any of the possible sources of input has some input ready to be read, Emacs reads the first one, executes whatever is needed to be executed for that input, then goes back to the main loop.
sit-for, accept-process-output, etc. call the function which checks for available input directly, without going through the main loop.
通过调用 accept-process-output ,我们可以让 Emacs 显式等待某个进程输出的到来,它的原型如下:
(accept-process-output &optional PROCESS SECONDS MILLISEC JUST-THIS-ONE)
这个函数可以读取来自某个进程的待读取数据,读取到的数据将传递给进程的 filter 函数。如果不指定 PROCESS 参数那将等待全部进程的输出,若指定则会等待来自 PROCESS 的输出或等待 PROCESS 关闭连接。 SECONDS 和 MILLISEC 参数用于指定超时时间,前者是秒,后者是微秒,它们的和是等待总时间( MILLISEC 这个参数已经弃用了,我们最好传 nil)。
如果指定了 PROCESS 且 JUST-THIS-ONE 非空,那么 Emacs 只会处理这个进程的输出,来自其他进程的输出将会暂时挂起,直到这个进程的输出被处理或 accept-process-output 超时。如果 JUST-THIS-ONE 为整数将会禁止 timer 的执行,一般来说我们用不到 JUST-THIS-ONE 这个参数。
如果等到了输出, accept-process-output 会返回非空值,如果等待的进程被关闭了或等待超时,这个函数会返回 nil。如果我们想读取来自某进程的全部输出,文档建议我们这样做:
(while (accept-process-output process))关于错误输出的处理文档略有提及,这里就不多废话了。
sentinel 这个单词一看就直到不是什么常用词,这也成了阻碍我学习 Emacs 进程的障碍之一(笑)。sentinel 的中文意思是“哨兵”,通常指特殊值或标记,用于表示某种特定情况或条件。在异步编程中,sentinel 通常用来表示异步操作的状态。在 Emacs 中,异步进程的 sentinel 是一个函数,进程的默认 sentinel 会在进程状态发生变化时在 process buffer 中插入状态消息。它接受两个参数:出现事件的进程对象和描述状态的字符串。状态字符串有以下几种:
- "finished\n".
- "deleted\n".
- "exited abnormally with code exitcode (core dumped)\n".
- "failed with code fail-code\n".
- "signal-description (core dumped)\n".
- "open from host-name\n".
- "open\n".
- "run\n".
- "connection broken by remote peer\n".
我们可以调用 set-process-sentinel 来像设置 filter 一样设置某进程的 sentinel,调用 process-sentinel 来获取某进程的 sentinel。从文档内容来看,sentinel 与 filter 有很多相似之处,这里我就不详细介绍了,读者同样可以看看 jsonrpc.el 中的例子。
类似同步进程调用,异步调用也有一些包装函数来方便我们使用。这里就简单列举一下吧:
start-process,创建异步子进程并返回进程对象(start-process NAME BUFFER PROGRAM &rest PROGRAM-ARGS)
start-file-process,类似process-file之于call-process(start-file-process NAME BUFFER PROGRAM &rest PROGRAM-ARGS)
start-process-shell-command,在 SHELL 环境下异步执行命令(start-process-shell-command NAME BUFFER COMMAND)
start-file-process-shell-command(start-file-process-shell-command NAME BUFFER COMMAND)
shell-command,执行 shell 命令,可同步也可异步,具体参考文档(shell-command COMMAND &optional OUTPUT-BUFFER ERROR-BUFFER)
shell-command-on-region,以 region 作为命令的输入
这里的 COMMAND 参数和同步 SHELL 调用函数类似,都是一整个字符串而不是字符串列表。相比 make-process 它们的参数要少上很多,但我们可以通过 getter/setter 来设置或获取其他选项。我们可以在调用这些函数时通过 coding-system-for-write 指定子进程的输出编码,使用 coding-system-for-read 指定进程的输入编码,或者直接通过 set-process-coding-system 设置编码。对于其他的进程选项,比如 filter, sentinel, buffer,都有对应的 getter 和 setter 函数。
从内容上看,Elisp Manual 的第 39 章可以分为几大块,分别是:
- 总览
- 同步进程
- 异步进程
- 39.4 Creating an Asynchronous Process
- 39.5 Deleting Processes
- 39.6 Process Information
- 39.7 Sending Input to Processes
- 39.8 Sending Signals to Processes
- 39.9 Receiving Output from Processes
- 39.10 Sentinels: Detecting Process Status Changes
- 39.11 Querying Before Exit
- 39.12 Accessing Other Processes
- 39.13 Transaction Queues
- 网络连接
- 串口通信
在上面的列表中没有用粗体的章节都是我在文中没有提到或者只是简单说了几句的内容。读者若有需要或者有兴趣可以读一读。
通过上面的介绍和一些简单的编程实践,相信你已经掌握了如何在 Emacs 中创建进程这一技术。现在让我们简单地实践一下,编写一个简单的本地 RPC。当然这里的主要目的还是学会使用 process filter。
The idea of remote procedure calls (hereinafter called RPC) is quite simple. It is based on the observation that procedure calls are a well-known and well understood mechanism for transfer of control and data within a program running on a single computer. Therefore, it is proposed that this same mechanism be extended to provide for transfer of control and data across a communication network.
The primary purpose of our RPC project was to make distributed computation easy. … Our hope is that by providing communication with almost as much ease as local procedure calls, people will be encouraged to build and experiment with distributed applications.
RPC 的全称是 Remote Procedure Call,即远程过程调用,这里的远程是相对于进程内部的函数调用来说的。RPC 希望通过提供类似过程调用的方式来与远端进程通信,隔开一些通信上的细节。上面引用的论文提到了 RPC 的一些优点:
- clean and simple semantics
- efficiency
- generality
一般来说,一个 RPC 系统至少由以下部分组成:
- Client,发起请求
- Server,提供服务
- Protocol,协议,规定 RPC 的调用格式和规则
- Serialization/Deserialization,对象的序列化/反序列化,让对象变为可传输的字节流/从字节流获取对象
- Communication Layer,负责传输 RPC 的请求和响应
这是论文中的一张图片,比较清晰地展示了系统的各个部分:

对我们来说,Client 就是 Emacs,Server 就是启动的子进程,Communication Layer 就是进程间 stdio,序列化/反序列化可以用 Emacs 自带的 json 支持。至于 Protocol 我们可以随便选一个,比如 jsonrpc。由于不用考虑的很全面甚至可以自己搓一个。
完整的 jsonrpc 规范可以在这里找到,它已经是一个非常简单的 RPC 协议了,不过由于我们编写的程序的简单性,我们还可以根据以下几点再做简化:
- 总是在一个调用得到返回值后再开始下一个调用
- 所有的调用都会成功
- 没有通知,没有批量调用
- 不需要版本标识
- 全部使用 ASCII 字符
- …
经过一些简化,我得到了 yyjsrpc 协议(笑),请求方需要指定 method 和 params 字段,前者是函数名,后者是参数,是由参数组成的列表;响应方只需要指定 result 即可。一个简单的调用大致如下:
--> {"method" : "add", "params" : [1, 2]}
<-- {"result" : 5}
Emacs 为我们提供了序列化函数 json-serialize 和反序列化函数 json-parse-buffer 或 json-parse-string 。以下是使用例:
(json-serialize '(a 1 b 2 c 3))
=> "{\"a\":1,\"b\":2,\"c\":3}"
(json-parse-string "{\"a\":1,\"b\":2,\"c\":3}")
=> #s(hash-table
size 3
test equal
rehash-size 1.5
rehash-threshold 0.8125
data ("a" 1 "b" 2 "c" 3))
(json-parse-string "[1,2,3]")
=> [1 2 3]
由于 RPC 是 Clinet/Server 之间的通信,这里使用同步进程似乎不太好,故采用异步进程。我们约定使用 \n 表示一条请求或响应的结尾。对 Emacs 端,发送请求的函数可以这样实现:
(defun yy-rpc-send (pobj method arg)
(let ((data (concat
(json-serialize `(method ,method params ,arg))
"\n")))
(process-send-string pobj data)))Python 端的接受和发送可以这样实现:
import json
# read
a = sys.stdin.readline()
k = json.loads(a)
# write
result = 1
c = {"result" : result}
d = json.dumps(c)
print(d)
如果我们的目的只是看到来自 Python 的输出的话,那么我们的工作已经完成了,使用默认的 filter function 即可,下面是支持 add 和 sub 方法的 Python “服务器”:
import json
import sys
def add (x, y):
return x + y
def sub (x, y):
return x - y
metable = {'add' : add,
'sub' : sub }
print('server start')
sys.stdout.flush()
while True:
a = sys.stdin.readline()
indata = json.loads(a)
method = metable[indata['method']]
params = indata['params']
ret = method(*params)
b = json.dumps({"result" : ret})
print(b)
sys.stdout.flush()通过以下代码我们可以创建子进程,然后开始通信了:
(start-process "yy" (get-buffer-create "*a*") "python" "1.py")
(yy-rpc-send (get-process "yy") "add" [1 2])
(yy-rpc-send (get-process "yy") "sub" [1 2])
(yy-rpc-send (get-process "yy") "add" [114514 191981])
(yy-rpc-send (get-process "yy") "add" [123 456])
(process-send-eof "yy")
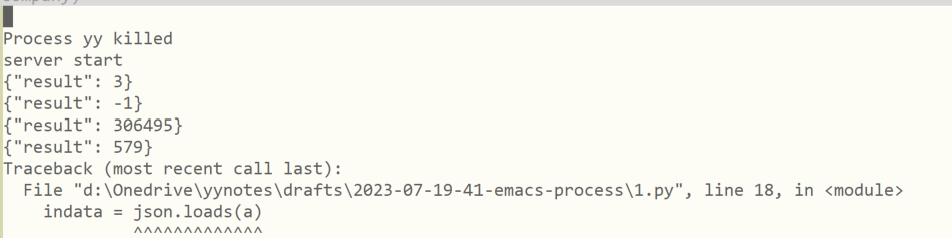
以下是 *a* buffer 中的结果:
我们可以对 yy-rpc-send 调用进行包装让它看上去更像是调用了 add 和 sub 函数,不过当务之急是让 Emacs 在收到结果后能让调用者“知道”,下面让我们通过编写自己的 filter 实现结果的提取。
现在,我们的服务端已经完全实现了,但客户端还有一个问题没有解决:caller 只是发送了调用命令,现在它还不能直接获取 callee 返回的结果。如果你很熟悉 JavaScript 的话,面对通信这种异步操作,一种解决方法是添加回调函数,让响应在到达 Emacs 使用返回结果调用回调函数来完成值的获取。我们定义一个存放回调函数的变量,然后在 filter 发现条件满足时调用它:
(defvar yyrpc-callback (lambda (s) (message "hello %s" s)))
(defun yyrpc-filter (proc string)
(when (buffer-live-p (process-buffer proc))
(with-current-buffer (process-buffer proc)
;; insert string
(save-excursion
(goto-char (process-mark proc))
(insert string)
(set-marker (process-mark proc) (point)))
;; find json data
(when-let* ((curr-point (point))
(search (search-forward "\n" nil t)))
(when (string= "{" (buffer-substring curr-point (1+ curr-point)))
(let* ((hash (json-parse-string (buffer-substring curr-point (1- search))))
(res (gethash "result" hash)))
(funcall yyrpc-callback res)))))))
现在,我们可以考虑给 add 和 sub 一个函数包装,让它们看上去更像是函数调用:
(defvar yyrpc-name "yy")
(defvar yyrpc-buf "*a*")
(defun yyrpc-start ()
(let ((buf (get-buffer-create yyrpc-buf)))
(with-current-buffer buf
(goto-char (point-max)))
(start-process yyrpc-name buf "python" "1.py")
(set-process-filter (get-process yyrpc-name) 'yyrpc-filter)))
(defun yyrpc-send (proc method arg k)
(let ((data (concat
(json-serialize `(method ,method params ,arg))
"\n")))
(process-send-string proc data)
(setq yyrpc-callback k)))
(defun yyrpc-add (a b k)
(yyrpc-send (get-process yyrpc-name) "add" `[,a ,b] k))
(defun yyrpc-sub (a b k)
(yyrpc-send (get-process yyrpc-name) "sub" `[,a ,b] k))
(yyrpc-start)
(yyrpc-add 1 2 (lambda (x) (message "%s" x)))
(yyrpc-sub 1 2 (lambda (x) (message "%s" x)))
(yyrpc-add 114513 1 (lambda (x) (message "%s" x)))有了这些工具,现在让我们写个斐波那契计算函数吧:
(defun yyrpc-fib (n k)
(cond
((= n 0) (funcall k 0))
((= n 1) (funcall k 1))
(t (yyrpc-sub
n 1
(lambda (k1)
(yyrpc-fib
k1 (lambda (k2)
(yyrpc-sub
n 2
(lambda (k3)
(yyrpc-fib
k3 (lambda (k4)
(yyrpc-add
k2 k4 k))))))))))))
(yyrpc-fib 12 (lambda (x) (message "%s" x)))
=> echo area 144算到 12 时差不多就要用一秒钟了,这是因为大部分时间都用在数据传输上了,下图是 process buffer:
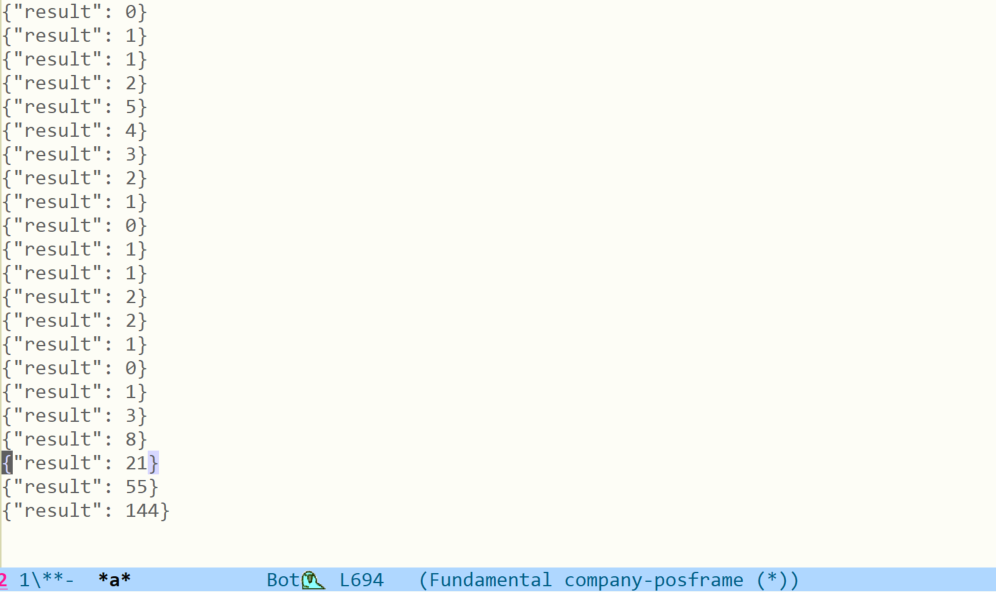
根据行数来看的话总共在 Python 中进行了 697 次加减运算。
虽然我们已经实现了 RPC,但换你可能也不太愿意写上面的代码。我们可以利用 accept-process-output 来让 Emacs 等待 RPC 完成,从而做到异步调用的同步化:
(defun yyrpc-send-sync (proc method arg)
(catch 'yyrpc-fin
(yyrpc-send proc method arg
(lambda (k)
(throw 'yyrpc-fin k)))
(accept-process-output proc 1)))
(defun yyrpc-add-sync (a b)
(yyrpc-send-sync (get-process yyrpc-name) "add" `[,a ,b]))
(defun yyrpc-sub-sync (a b)
(yyrpc-send-sync (get-process yyrpc-name) "sub" `[,a ,b]))
(defun yyrpc-fib-sync (n)
(cond
((= n 0) 0)
((= n 1) 1)
(t (yyrpc-add-sync
(yyrpc-fib-sync (yyrpc-sub-sync n 1))
(yyrpc-fib-sync (yyrpc-sub-sync n 2))))))
(yyrpc-fib-sync 12) => 144现在,我们基本实现了一个非常简陋的,基于标准输入输出的 RPC “框架”。读者可以在此基础上添加一些新玩意,下面是完整代码:
python 代码
import json
import sys
def add (x, y):
return x + y
def sub (x, y):
return x - y
metable = {'add' : add,
'sub' : sub }
print('server start')
sys.stdout.flush()
while True:
a = sys.stdin.readline()
indata = json.loads(a)
method = metable[indata['method']]
params = indata['params']
ret = method(*params)
b = json.dumps({"result" : ret})
print(b)
sys.stdout.flush()elisp 代码
;; -*- lexical-binding: t; -*-
(defvar yyrpc-callback (lambda (s) (message "hello %s" s)))
(defun yyrpc-filter (proc string)
(when (buffer-live-p (process-buffer proc))
(with-current-buffer (process-buffer proc)
;; insert string
(save-excursion
(goto-char (process-mark proc))
(insert string)
(set-marker (process-mark proc) (point)))
;; find json data
(when-let* ((curr-point (point))
(search (search-forward "\n" nil t)))
(when (string= "{" (buffer-substring curr-point (1+ curr-point)))
(let* ((hash (json-parse-string (buffer-substring curr-point (1- search))))
(res (gethash "result" hash)))
(funcall yyrpc-callback res)))))))
(defvar yyrpc-name "yy")
(defvar yyrpc-buf "*a*")
(defun yyrpc-start ()
(let ((buf (get-buffer-create yyrpc-buf)))
(with-current-buffer buf
(goto-char (point-max)))
(start-process yyrpc-name buf "python" "1.py")
(set-process-filter (get-process yyrpc-name) 'yyrpc-filter)))
(defun yyrpc-send (proc method arg k)
(let ((data (concat
(json-serialize `(method ,method params ,arg))
"\n")))
(process-send-string proc data)
(setq yyrpc-callback k)))
(defun yyrpc-add (a b k)
(yyrpc-send (get-process yyrpc-name) "add" `[,a ,b] k))
(defun yyrpc-sub (a b k)
(yyrpc-send (get-process yyrpc-name) "sub" `[,a ,b] k))
(defun yyrpc-fib (n k)
(cond
((= n 0) (funcall k 0))
((= n 1) (funcall k 1))
(t (yyrpc-sub
n 1
(lambda (k1)
(yyrpc-fib
k1 (lambda (k2)
(yyrpc-sub
n 2
(lambda (k3)
(yyrpc-fib
k3 (lambda (k4)
(yyrpc-add
k2 k4 k))))))))))))
(defun yyrpc-send-sync (proc method arg)
(catch 'yyrpc-fin
(yyrpc-send proc method arg
(lambda (k)
(throw 'yyrpc-fin k)))
(accept-process-output proc 1)))
(defun yyrpc-add-sync (a b)
(yyrpc-send-sync (get-process yyrpc-name) "add" `[,a ,b]))
(defun yyrpc-sub-sync (a b)
(yyrpc-send-sync (get-process yyrpc-name) "sub" `[,a ,b]))
(defun yyrpc-fib-sync (n)
(cond
((= n 0) 0)
((= n 1) 1)
(t (yyrpc-add-sync
(yyrpc-fib-sync (yyrpc-sub-sync n 1))
(yyrpc-fib-sync (yyrpc-sub-sync n 2))))))
;; examples
;; (yyrpc-start)
;; (yyrpc-fib 5 'print)
;; (yyrpc-add 1 2 'print)
;; (yyrpc-sub 1 2 'print)
;; (+ 1 (yyrpc-add-sync 2 3)) => 6
;; (+ 1 (yyrpc-sub-sync 2 3)) => 0
;; (yyrpc-fib-sync 15) => 610
网络连接也使用进程对象进行表示,但它们实际上并不是与 Emacs 通信的子进程,因此它们没有进程 ID。将 delete-process 用于这类进程对象会关闭网络连接,但无法杀死远端的进程。它在一些细节上与普通进程有些区别。
创建网络连接的函数只有两个,核心函数 make-network-process 和专用于创建 TCP 连接的 open-network-stream 。网络进程发送数据和接收数据的机制和普通进程几乎一模一样,这里我们先从 make-network-process 讲起。
这个函数和 make-process 一样,参数使用 &rest ARGS 表示,某些在 make-process 介绍过的参数这里就不展开了,只是列举一下:
:name连接名:buffer接收数据的 buffer:coding指定接收和发送使用的编码:noquery指定 query-flag:filter指定 filter:sentinel指定 sentinel
下面这些是 make-network-process 特有的:
:type指定连接类型,nil表示流连接(TCP),datagram表示数据报连接(UDP),seqpacket表示有序包连接,连接和 server 都可以使用这些类型- 可以参考 Unix socket, SOCK_SEQPACKET vs SOCK_DGRAM 了解什么是
seqpacket
- 可以参考 Unix socket, SOCK_SEQPACKET vs SOCK_DGRAM 了解什么是
:server若为非nil则创建 server 而不是连接,对流服务器可以是一个指定最大连接数的整数,默认为 5:host指定连接的主机,它需要是一个主机名或地址字符串,或者是local符号来表示本地主机。- 在指定 server 的
:host时它必须是本地主机的合法地址 - 指定
local时默认使用 ipv4,可以通过:family来显式指定 ipv6 - 要想监听所有的网络接口,ipv4 可指定
"0.0.0.0", ipv6 则是"::"
- 在指定 server 的
:service指定连接的端口号,对 server 则是监听的端口号- 它可以是一般服务名,比如
"https"(对应 443) - 若为
t则表示让系统选择一个未使用的端口号
- 它可以是一般服务名,比如
:family指定地址家族,nil表示根据:host和:service自动确定,local表示使用 Unix socketipv4和ipv6表示使用 IPv4 和 IPv6
:use-external-socket,若非空则使用传递给 Emacs 的 socket 而不是分配一个- 不明所以的参数
:local对 server 用于指定监听地址,它会覆盖familyhost和service:remote对连接,指定连接的地址,它会覆盖familyhost和service- 对数据报 server,它用于初始化远程数据报地址
:local和:remote的格式可以是[a b c d p]和[a b c d e f g h p],前者是 ipv4,后者是 ipv6
:nowait,对流连接,为非nil则表示不等待连接完成,随后会使用 sentinel 通知:tls-parameters,创建 TLS 连接时需要指定 TLS 类型,可以是gnutls-x509pki或gnutls-anon:stop,若为非空,网络连接或 server 以停止状态启动:filter-multibyte,若非空则发送给 filter 的字符串是 multibyte 的,否则为 unibyte- 默认为
t
- 默认为
:log指定用于 server 的 log 函数,每当 server 接受网络连接时函数会被的调用,它接受serverconnection和message三个参数,server是 server 进程,connection是新的连接进程,message是事件描述字符串:plist,初始化进程的 plist
老实说这参数数量实在是有点多,我们有必要简单分个类,顺便去掉一些不常用的选项:
- 通用选项
:name连接名:buffer输出 buffer:coding编解码:filter和:sentinel:filter-multibyte接受 multibyte 或 unibyte:type连接类型:host连接的主机:service连接的端口号:family地址家族:plist进程 plist
- 连接选项
:remote直接指定地址
- server 选项
:server指定为 server:remote指定远端 UDP 地址:local指定监听地址:log指定 log 函数
你可能会好奇这个多出来的 :plist 参数是干什么的,它被用来指定一些额外的选项,具体可以参考 39.17.2 Network Options,我不觉得我会用到它们。我们可以使用 set-network-process-option 来设置它们。
UDP(可能)比 TCP 稍微简单一点,我们只需要发包就行了,但在 Windows 上 emacs 28.2 不支持 UDP:
- #9586 The Windows port does not support datagram sockets
- #45821 28.0.50; Add UDP support for Emacs on Windows
似乎在 Windows 上我们只剩默认的 TCP 可用了……也罢,就介绍一下 TCP 连接的创建吧。
下面的 Python 代码功能是接收连接方发送的数据并发送 Hello:
import socket
import select
host = 'localhost'
port = 11451
def start_server():
server_start = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_start.bind((host, port))
server_start.listen(1)
while True:
try:
readable, _, _ = select.select([server_start], [], [], 1.0)
if server_start in readable:
client, addr = server_start.accept()
print('connect start {}'.format(addr))
while True:
data = client.recv(1024)
if data == b'stop':
client.close()
print('connect close')
break
else:
client.sendall(b'hello')
except KeyboardInterrupt:
print('Ctrol-c')
break
start_server()我们可以使用如下代码创建与它的连接:
(make-network-process
:name "yy"
:buffer "*a*"
:coding 'binary
:remote [127 0 0 1 11451])
(process-send-string "yy" "a")
(process-send-string "yy" "stop")
除了使用 make-network-process 外,我们可以使用比较高级的 open-network-stream ,它会为我们创建 TCP 连接,函数原型如下:
(open-network-stream NAME BUFFER HOST SERVICE &rest PARAMETERS)
NAME, BUFFER, HOST 和 SERVICE 相信不用我过多解释了,最后的 PARAMETERS 可以参考这个函数的 docstring 或 39.14 Network Connections,我不觉得我会用到它们。使用下面的代码我们也能创建和 make-network-process 一样的连接:
(open-network-stream "yy" "*a*" "127.0.0.1" 11451)
(process-send-string "yy" "a")如果你对如何在 Emacs 中创建 TCP 服务器感兴趣的话可以读一读 39.15 节,或者是阅读一些已有的代码,比如 emacs-web-server。这里我就不展开了。
原先我还打算将 RPC 在 TCP 上实现一遍,但写到这里感觉有些累了,而且现成的东西也有不少。我可能会在下一篇文章中详细介绍一下 Emacs 中的 RPC 生态。
我写这篇文章,或者说折腾 Emacs 子进程功能的主要动力还是 RPC,它算是一种写起来比较方便的多语言协作方式了。之前在知乎上看到这样的回答:不同语言为什么不能相互调用 ?也算是让我有所启发。
原先我还以为 RPC 是非常复杂的东西,果然还是小马过河的道理。只要我面对的问题足够简单,那解决方法也不会复杂到哪里去。
如果我们只是想调用一下命令行工具,使用同步进程即可。如果我们需要连续地使用某些服务,可以考虑使用异步进程,如果我们要进行网络通信,那就得使用网络进程了。
感谢阅读。