考虑到 emacs 提供的加载功能并不限于 el 和 elc 文件,也许我有必要介绍一下动态模块和 native-comp,当然这里只是一笔带过,我会在之后的文章中详细介绍这两个功能。
所谓的动态模块就是位于 emacs 外部的功能模块,它可以使用非 elisp 语言来编写,只要遵守 emacs 的 module API 即可被 emacs 载入并使用其功能。
参考 emacs lisp manual 附录 E.8,我们可以写出自己的动态模块,并使用 load 函数进行加载。不过文档有些晦涩,这里有一篇教程,略作参考,我写出了如下 module:
#include "path/to/emacs-module.h"
int plugin_is_GPL_compatible;
static emacs_value
F_yy_add1 (emacs_env *env, ptrdiff_t nargs, emacs_value args[], void*data);
int emacs_module_init (struct emacs_runtime *runtime)
{
if (runtime->size < sizeof(*runtime)) {
return 1;
}
emacs_env *env = runtime->get_environment(runtime);
if (env->size < sizeof(*env))
{
return 2;
}
emacs_value fn = env->make_function(env, 1, 1, F_yy_add1, "add 1", NULL);
emacs_value Qfset = env->intern(env, "fset");
emacs_value Qfn = env->intern(env, "yy-add1");
emacs_value fset_args[] = {Qfn, fn};
env->funcall(env, Qfset, 2, fset_args);
return 0;
}
static emacs_value
F_yy_add1 (emacs_env *env, ptrdiff_t nargs, emacs_value args[], void*data)
{
intmax_t x = env->extract_integer(env, args[0]);
return env->make_integer(env, x+1);
}
你可以将最上面的 include 换成自己 emacs 的 emacs-module.h 路径,在我的 emacs 中该文件位于 emacs 目录下的 include 目录中。在 MSYS2 中使用如下命令可以得到 dll:
gcc -o lib.dll -shared 1.c -Wall
随后,通过 (load "path/to/lib.dll") 或 (load-file "path/to/lib.dll") (前者必须用绝对路径,或者把当前目录添加到 load-path 再 (load "lib") ),我们可以将函数 yy-add1 载入 emacs 中并调用。
我们知道 emacs 有个字节码编译器,可以将 elisp 函数编译成字节码来加快执行速度。在 28 版本中 emacs 引入了 native-compilation 功能,它通过使用 libgccjit 将 elisp 代码直接编译到机器码,以获得比 byte-compilation 更快的速度。如果我们在编译 emacs 时指定了 --with-native-compilation ,我们得到的 emacs 就能够进行 native-compile。根据文档的说法,native-compilation 能比 byte-compilation 快 2.5 到 5 倍。我在编写我的 brainfuck 解释器时简单测试了一下两者的用时,也许没有文档说的那么快,不过还是有点提高。
如果你是从 emacs 官网或镜像下载的 emacs 28.2 Windows 版,那么应该启用了 native-compilation 功能,并且已经有一些内置的 native 编译后的函数可用了,但是我没有在我下载的 emacs 的目录中发现 libgccjit0.dll ,也许我们需要通过 MSYS2 安装 libgccjit,然后把它移动到 emacs 的 bin 目录下,并且要让 emacs 能够找到 gcc。这个就留到之后折腾 native-compilation 的时候再介绍吧。下面我假设你的 (native-comp-available-p) 返回 t 。
根据文档的说法,native-compilation 是 byte-compilation 的副作用产物。对 Lisp 代码进行 native 编译总会生成字节码。我们可以通过调用 native-compile 或 batch-native-compile 来对函数或文件进行编译,后者只能在 emacs 的 batch mode 下执行。你可以通过以下代码来对比一下 byte-compilation 和 native-compilation 的速度:
(defun fib-el (n)
(cond ((= n 0) 0)
((= n 1) 1)
(t
(+ (fib-el (1- n))
(fib-el (- n 2))))))
(defun fib-by (n)
(cond ((= n 0) 0)
((= n 1) 1)
(t
(+ (fib-by (1- n))
(fib-by (- n 2))))))
(defun fib-na (n)
(cond ((= n 0) 0)
((= n 1) 1)
(t
(+ (fib-na (1- n))
(fib-na (- n 2))))))
(byte-compile 'fib-by)
(native-compile 'fib-na)
(dolist (a '(fib-el fib-by fib-na))
(let ((ti (float-time)))
(fib-el 35)
(message "%s" (- (float-time) ti))))由于我现在的 emacs 没有配好 native-compilation,这里我就不展示结果了。对于如此普通的函数,从普通形式到字节码应该有比较大的提升,但是从字节码到 native code 应该提升不是很大了。很久之前我跑过一次,由于环境和 CPU 都忘了,下面的图就图一乐吧:

顺带附上彩蛋:
关于 native-compilation 还有一些选项可供调整,这里就不一一介绍了,详情可参考 Native-Compilation Variables。
加载一个 lisp 代码文件就意味着将文件中的内容带入 Lisp 环境中。Emacs 会寻找并打开文件,读取文本,对每一项进行求值,然后关闭文件。这样的文件也叫做一个 Lisp 库 。 load 是其他加载机制的基础,我们先从它开始。
就像 eval-buffer 会对 buffer 中所有表达式求值一样,函数 load 会对文件中的所有表达式进行求值。它们的不同之处在于 load 函数作用于文件而不是 Emacs 中的 buffer。被 load 的文件必须包含 Lisp 表达式,它可以是 elisp 源代码或字节编译代码。文件中的 form 被称为 top-level form 。如果 emacs 编译时指定了动态模块支持,那么 load 还可以载入 .dll 或 .so 文件。
这一节的内容大部分都是我对文档内容的翻译,你可以通过访问 elisp 文档来找到原文,或是在 emacs 中打开文档。在介绍文档时我会使用 lread.c 中的源代码和一些例子做补充说明。
load 的函数原型如下:
(load FILE &optional NOERROR NOMESSAGE NOSUFFIX MUST-SUFFIX)
在这一节中,我们通过翻译文档简述一下 load 的调用过程。
首先, load 会尝试寻找 FILE.elc ,也就是 byte-compiled 的文件。如果它找到了文件且 emacs 支持 native-compilation,那么 load 会尝试查找对应的 .eln 文件并加载,否则加载 elc 。如果不存在 elc 文件,那么 load 会查找名为 FILE.el 的文件,如果这个文件存在, load 会加载它。如果到了这一步还是找不到,而且 emacs 支持动态模块(dynamic modules),那么 load 会尝试寻找 FILE.ext 的文件,其中 ext 依赖于系统的动态库扩展名。
如果这些都没有找到, load 会尝试搜索不带后缀的 FILE ,并在该文件存在时加载它。根据以上顺序,如果我们使用 "hello.el" 作为 FILE 参数,那么首先被查找的应该是 hello.el.elc ,接着是 hello.el.eln ,接着是 hello.el.dll (或者 .so),最后才是 hello.el 。
如果开启了 auto-compression-mode (默认开启),那么 load 在找不到文件并尝试其他文件名之前会查找该文件的压缩版本,并在压缩文件存在时解压缩加载。它通过添加 jka-compr-load-suffixes 中的后缀名到文件名来查找文件的压缩版本。 jka-compr-load-suffixes 是由字符串组成的表,它的默认值是 (".gz") 。
如果我们指定 NOSUFFIX 为非空,那么 load 不会尝试对 FILE 添加 el 或 elc 后缀进行查找,我们就必须对 FILE 参数指定带扩展名的文件名。如果 auto-compression-mode 开启的话, load 还会使用 jka-compr-load-suffixes 来查找压缩版本。
如果 MUST-SUFFIX 为非空,那么 load 会认定文件名 必须 以 .el , .elc 或动态库后缀结尾(可能还有额外的压缩后缀),除非文件名显式指定了目录名。从参数位置和文档描述来看,这个选项似乎是对 NOSUFFIX 的加强,但事实真的是这样吗(笑)。
如果 load-prefer-newer 非空,那么 load 会选择最新的文件( elc, el 等等)。在这种情况下 load 不会加载 eln 文件,即使它存在。
如果 FILE 是相对位置文件名,比如 foo, foo/bar.baz ,那么 load 会使用 load-path 来搜索文件。它会将 FILE 加到 load-path 中的各个目录后面,然后加载第一个匹配的文件。如果 default-directory 也在 load-path 中, load 也会在当前目录搜索,要想这样做的话我们可以将 nil 添加到 load-path 中。
load 会按照 load-path 中元素的顺序一个个尝试可能的后缀。当最终找到名字对应的文件和目录时,emacs 会将 load-file-name 设为文件的名字(文件的绝对路径)。
如果我们的 el 文件比对应的 elc 文件新,那么 Emacs 会提醒我们重新编译 el 文件。当加载 el 文件时, load 会使用 Emacs 打开文件时使用的编码行为来处理字符。
在加载未编译的文件时(.el),Emacs 会尝试展开文件中所有的宏调用。这也被称为 eager macro expansion ,这样做(而不是将宏展开推迟到运行时)可以大幅提高未编译代码的执行速度。有时由于循环依赖这样的宏展开不会进行,最简单的情况是 load 的文件中使用的宏在另一个文件中,而那个文件又依赖了被 load 的文件。一般来说这样是无害的,Emacs 会显示 Eager macro-expansion skipped due to cycle… 的 Warning 并继续加载文件,只不过会放弃宏展开。你可以重构代码来避免该 warning。加载字节编译文件不会有这样的问题,因为宏展开已经在编译时发生过了。
当 NOMESSAGE 参数为空时,加载开始时 echo area 会显示 "Loading foo…",加载完成时会显示"Loading foo…done"。如果该参数非空则不会显示。对于 eln 文件也会有加载 message。
在加载时出现的任何未处理的错误都会中断加载过程。如果加载是通过 autoload 触发的,那么任意加载的函数都会回退。
如果 load 不能找到需要加载的文件,那么他会引发 file-error 错误。但是如果 NOERROR 为非空, load 只会返回 nil 。
我们可以使用变量 load-read-function 来指定用于替换 read 的读取函数。
如果加载成功, load 会返回 t 。
在读完上面的内容后想必你对 load 的行为有了一定的了解,现在让我们通过一些源代码来消除一些模糊部分。下面我们按照代码顺序开始吧。
首先,如果我们给出的 FILE 后缀为 .elc ,那就表明我们不想加载 native code, no_native 会被设为真值:
bool no_native = suffix_p (file, ".elc");
紧接着就是对 MUST_SUFFIX 的处理。如果我们给出的 FILE 带有满足后缀条件的后缀,那么 must_suffix 会被设为 nil ,从这里的代码来看,符合 MUST_SUFFIX 的还包括 native 的 eln 后缀:
if (! NILP (must_suffix))
{
/* Don't insist on adding a suffix if FILE already ends with one. */
if (suffix_p (file, ".el")
|| suffix_p (file, ".elc")
#ifdef HAVE_MODULES
|| suffix_p (file, MODULES_SUFFIX)
#ifdef MODULES_SECONDARY_SUFFIX
|| suffix_p (file, MODULES_SECONDARY_SUFFIX)
#endif
#endif
#ifdef HAVE_NATIVE_COMP
|| suffix_p (file, NATIVE_ELISP_SUFFIX)
#endif
)
must_suffix = Qnil;
/* Don't insist on adding a suffix
if the argument includes a directory name. */
else if (! NILP (Ffile_name_directory (file)))
must_suffix = Qnil;
}
再接下来就是对 NOSUFFIX 的处理了,如果它为非空,那么 suffixes 列表为空,否则为 get-load-suffixes 加上 (在 MUST_SUFFIX 为假的情况下) load-file-rep-suffixes :
if (!NILP (nosuffix))
suffixes = Qnil;
else
{
suffixes = Fget_load_suffixes ();
if (NILP (must_suffix))
suffixes = CALLN (Fappend, suffixes, Vload_file_rep_suffixes);
}
在此之后 must_suffix 和 nosuffix 就再也没有出现过了,现在让我们来捋一捋它们的作用吧。根据上面的代码,如果 nosuffix 为真,那么 suffixes 总是为 Qnil 也就是没有后缀,这也就说明 MUST_SUFFIX 仅在 NOSUFFIX 为假时才会发挥作用,这和我在上一节的猜想是冲突的。
如果 NOSUFFIX 为假且 MUST_SUFFIX 为假,那么我们得到的 suffixed 就是 (get-load-suffixes) 加上 load-file-rep-suffixes ;如果 NOSUFFIX 为假但 MUST_SUFFIX 为真,那么 suffixes 就是 (get-load-suffixes) 的返回值。 MUST_SUFFIX 影响的仅仅是 load-file-rep-suffixes 是否被添加到 suffixes 中。
这也就是说在 NOSUFFIX 为假时,如果我们的 FILE 参数不符合后缀要求时指定 MUST_SUFFIX 为真才有用,否则 suffixes 总是会被添上 load-file-rep-suffixes 。现在让我们来看看 get-load-suffixes 这个函数:
DEFUN ("get-load-suffixes", Fget_load_suffixes, Sget_load_suffixes, 0, 0, 0,
doc: /* Return the suffixes that `load' should try if a suffix is \
required.
This uses the variables `load-suffixes' and `load-file-rep-suffixes'. */)
(void)
{
Lisp_Object lst = Qnil, suffixes = Vload_suffixes;
FOR_EACH_TAIL (suffixes)
{
Lisp_Object exts = Vload_file_rep_suffixes;
Lisp_Object suffix = XCAR (suffixes);
FOR_EACH_TAIL (exts)
lst = Fcons (concat2 (suffix, XCAR (exts)), lst);
}
return Fnreverse (lst);
}
这里面用到了一个奇怪的宏 FOR_EACH_TAIL ,不过我们很容易看出来这是个二重循环,它将 load-suffixes 和 load-file-rep-suffixes 组合了起来,类似二二得四,二三得六。在我的 emacs 中, load-suffixes 的值为 (".dll" ".elc" ".el") 而 load-file-rep-suffixes 的值为 ("" ".gz") ,经过这么一组合,我们就得到了:
(get-load-suffixes)
=> (".dll" ".dll.gz" ".elc" ".elc.gz" ".el" ".el.gz")
如果再加上 load-file-rep-suffixes 那就是 (".dll" ".dll.gz" ".elc" ".elc.gz" ".el" ".el.gz" "" ".gz") 。文档中对这个变量的说明是:它是用来表示不同后缀但实为同一文件的后缀列表。这个说法真够绕的,如果你在编译 emacs 时忘了指定 --without-compress-install ,那么你得到的 elisp 源文件是 gz 压缩版本,当然 emacs 能够正确处理这些文件就是了。 load-file-rep-suffixes 估计就是为了处理类似情况而出现的,有了它我们就能够识别文件的不同形式。
下一步就是通过 load-path 和 FILE ,以及 SUFFIX 来找到对应的文件名了,这是通过如下的 openp 调用完成的:
// prototype
int
openp (Lisp_Object path, Lisp_Object str, Lisp_Object suffixes,
Lisp_Object *storeptr, Lisp_Object predicate, bool newer,
bool no_native);
fd = openp (Vload_path, file, suffixes, &found, Qnil, load_prefer_newer,
no_native);
根据注释内容来看, openp 的作用是通过第二参数的文件名,根据第一参数的 load-path 和第三参数的 suffixes ,尝试找到匹配的文件,它的返回值是表示状态的描述符,第四参数是存储找到文件的对象指针。第六参数为 t 表示寻找的是二进制文件,这里为 Qnil ,第七参数为是否寻找最新的文件,第八参数是是否寻找 native code file,也就是上文中出现的 no_native 。这个返回值 fd 有些讲究,我们下面再说。
对于 openp 这个函数我只关注它对不同后缀的搜索顺序,它对 load-path 肯定是按着顺序一个一个来。事实上也确实是顺着 (get-load-suffixes) 的顺序来:
/* Loop over suffixes. */
AUTO_LIST1 (empty_string_only, empty_unibyte_string);
tail = NILP (suffixes) ? empty_string_only : suffixes;
FOR_EACH_TAIL_SAFE (tail)
{
Lisp_Object suffix = XCAR (tail);
ptrdiff_t fnlen, lsuffix = SBYTES (suffix);
Lisp_Object handler;
...;
}
这似乎说明 .dll 在 .elc 之前?我们可以做个实验验证一下。这里我们将上一节提到的 lib.dll 放入一个目录并将该目录添加到 load-path ,随后在该目录下创建 lib.el 并写入如下内容:
(defun yy-add1 (x) (+ x 2))
然后调用 (load "lib") ,可以看到如下效果:
(yy-add1 1) => 2
嘿, .dll 还真在 elc 和 el 之前,也许文档的顺序有问题。不过这是在 Windows 上得到的结果,我在 wsl 上的 emacs 27.1 通过调用 (get-load-suffixes) 得到的是 (".elc" ".elc.gz" ".el" ".el.gz" ".so" ".so.gz") 。看来文档针对的是 Linux 上的 emacs。
接着就是文档中提到的“如果 elc 存在,那么就会尝试加载 eln”。这是通过在 openp 中调用一个叫做 maybe_swap_for_eln 的函数完成的,它仅在 no_native 为假且文件是 .elc 后缀时才会尝试替换。这个函数的实现细节这里我就不介绍了。
在进行查找后,如果 openp 返回 -1 则表示没有找到,那么 load 会根据 NOERROR 判断是报错还是直接返回 Qnil :
if (fd == -1)
{
if (NILP (noerror))
report_file_error ("Cannot open load file", file);
return Qnil;
}在经过一些额外的处理后,我们来到了文件类型判断代码处,通过找到的文件的后缀可以得出加载文件的类型:
#ifdef HAVE_MODULES
bool is_module =
suffix_p (found, MODULES_SUFFIX)
#ifdef MODULES_SECONDARY_SUFFIX
|| suffix_p (found, MODULES_SECONDARY_SUFFIX)
#endif
;
#else
bool is_module = false;
#endif
#ifdef HAVE_NATIVE_COMP
bool is_native_elisp = suffix_p (found, NATIVE_ELISP_SUFFIX);
#else
bool is_native_elisp = false;
#endif再之后是对死循环载入的检测代码,根据代码来看似乎一个文件 连续 自加载多次就会引发错误:
/* Also, just loading a file recursively is not always an error in
the general case; the second load may do something different. */
{
int load_count = 0;
Lisp_Object tem = Vloads_in_progress;
FOR_EACH_TAIL_SAFE (tem)
if (!NILP (Fequal (found, XCAR (tem))) && (++load_count > 3))
signal_error ("Recursive load", Fcons (found, Vloads_in_progress));
record_unwind_protect (record_load_unwind, Vloads_in_progress);
Vloads_in_progress = Fcons (found, Vloads_in_progress);
}我们可以使用下面的代码做个实验:
(if (not (boundp 'yyds))
(progn (setq yyds 1)
(load "yyds"))
(when (< yyds 4)
(cl-incf yyds)
(load "yyds")))
如果我们将上面的 4 改为 3 然后调用 (load "yyds") 没有任何问题,但是直接使用上面的代码(如果调用过一次记得用 makunbound 清理一下)会得到这样的报错:
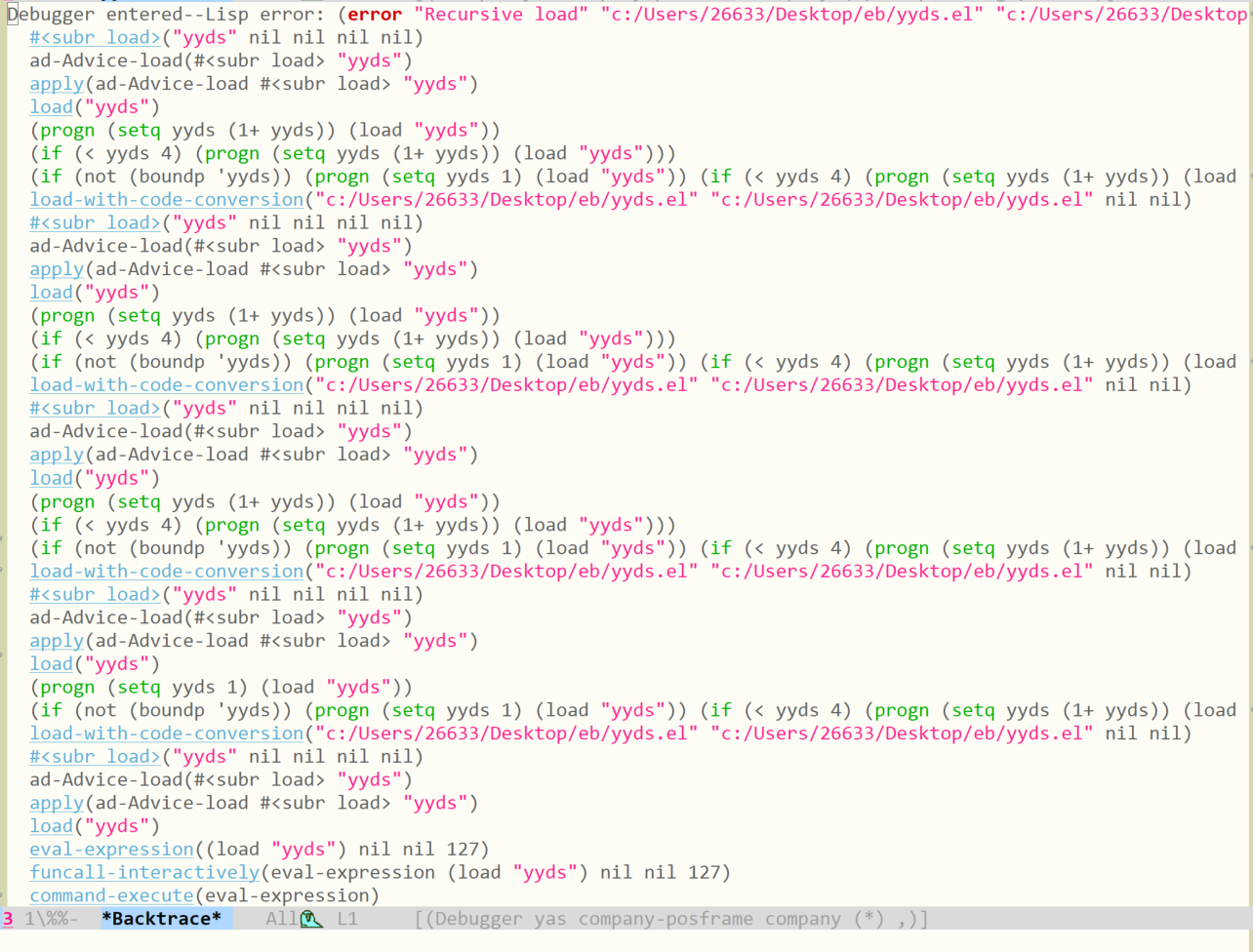
算上我们调用的那次 load ,这样的调用一共进行了 5 次,并在第五次时报错了。
接着,如果文件类型是 elc 的话 load 会尝试加载它。根据内容来看,这部分就是时不时出现的 Source file newer than byte-compiled file 的来源:
/* If we won't print another message, mention this anyway. */
if (!NILP (nomessage) && !force_load_messages)
{
Lisp_Object msg_file;
msg_file = Fsubstring (found, make_fixnum (0), make_fixnum (-1));
message_with_string ("Source file `%s' newer than byte-compiled file; using older file",
msg_file, 1);
}
接着,如果文件既不是动态模块也不是 native file, 而且 load-source-file-function 非空的话, load 会直接载入它:
else if (!is_module && !is_native_elisp)
{
/* We are loading a source file (*.el). */
if (!NILP (Vload_source_file_function))
{
Lisp_Object val;
if (fd >= 0)
{
emacs_close (fd);
clear_unwind_protect (fd_index);
}
val = call4 (Vload_source_file_function, found, hist_file_name,
NILP (noerror) ? Qnil : Qt,
(NILP (nomessage) || force_load_messages) ? Qnil : Qt);
return unbind_to (count, val);
}
}
再之后就是正常处理过程了,根据不同的文件类型选择不同的加载方法,文档中提到的 Eager macro-expansion 是由 readevalloop 中的 readdevalloop_eager_expand_eval 完成的。
到此为止,我们就完成了对 load 的部分代码分析。由于我们平时根本用不上 load 的后几个参数,这一通分析有些多余,不过多了解一些也没什么坏处就是了。
(load-file filename),这是个用于加载文件的命令,通过M-x调用后可以选择当前目录下的文件来加载。该函数不会使用load-path,也不会添加额外的后缀。不过如果auto-compression开启的话它还是会寻找文件的压缩版本
(load-library library),用于加载 library 的命令。它在功能上等同于load,通过M-x调用它会向用户展示所有load-path下的 library ,例如:
load-in-progress,若该变量非空说明正在载入一个文件,否则为空load-file-name,在载入过程中时,该变量的值是被加载文件的绝对路径,否则为空load-read-funtion,用于在load或eval-region时替换read来读取表达式的函数,它的默认值就是read。若我们要指定其他函数,它应该像read一样接受一个参数
在上一篇文章中我们已经比较详细地介绍了 load-path 的初始化过程,这里就结合文档做一些补充吧。
我们可以使用 EMACSLOADPATH 这个环境变量来指定最初的 load-path 值。不同的路径可以使用 ; 或 : 分隔(根据不同系统使用不同符号)。不要想当然地认为可以使用这个环境变量来指定自己的配置的位置,这个变量是指定 emacs 代码库位置的,一般我们用不上它。我们可以使用 -L 命令行参数向 load-path 中添加额外的路径。
在翻找一些 emacs 包时你可能会在 Readme 中看到这样的代码,比如这是 parrot 的部分 Readme:
;;Or the old-fashioned way:
(add-to-list 'load-path "/path/to/parrot-dir/")
(require 'parrot)
;; To see the party parrot in the modeline, turn on parrot mode:
(parrot-mode)
如果我们使用 package 安装包的话我们就不太用管 load-path , package 在初始化时会帮我们添加好各个包的路径。
下面介绍几个函数吧:
(locate-library library &optional nosuffix path interactive-call),这个命令会查找某个library的路径,它的nosuffix和load的一致,若指定了path那么该函数会在path而不是load-path中搜索
(list-load-path-shadows &optional stringp),这个命令会查找被遮蔽的 elisp 文件。所谓被遮蔽是指某个文件被位于它所在目录之前的某个load-path中的目录中的同名文件顶替了,这样我们在load它时只能够找到位于它前面的同名文件而不是它,除非我们指定绝对路径。在我的 emacs 配置中当我调用该命令时我得到了如下结果:

当然这些遮蔽并没有对我的日常使用造成什么影响,但是你注意到最后的三个深蓝色的标记了吗?这说明我的一些包已经遮蔽了 emacs 代码库中的某些文件。这也是为啥我在上一篇文章中说到我不是很想使用
normal-top-level-add-subdirs-to-load-path来加载包路径的原因。
如上一节所说,emacs 在支持 native compilation 时会通过 elc 找到对应的 eln ,这一查找过程是通过在 native-comp-eln-load-path 中的目录中查找来完成的。在我的 emacs 中它的值为:
native-comp-eln-load-path
=>
("c:/Users/26633/my/software/emacs-28.2/.emacs.d/eln-cache/"
"c:/Users/26633/my/software/emacs-28.2/lib/emacs/28.2/native-lisp/")(我这 .emacs.d 目录的位置可能有点奇怪,这是因为我专门设置了 emacs 启动时的 HOME 目录为 emacs 目录)
最后的目录是 emacs 安装时就完成编译的文件所在目录。
自从我用起 emacs 我就没怎么关注过 autoload 这个功能,我所有的配置和包在 emacs 启动时就全部加载完毕了,就算这个过程要用几秒或十几秒,我的 emacs 一般都是开到系统重启了,这点加载时间也不是什么问题。但是随着配置的积累,如果配置中出了问题,有时还不得不通过重启来找到问题所在的话,这十几秒还是挺折磨的。也许我有必要了解并使用 autoload 来将启动时间降至 2 秒或 1 秒以下。
通过使用 autoload,我们能够仅仅注册某个定义的存在,而不需要立刻加载该定义所在的文件,直到第一次调用该定义时 emacs 才会自动加载该文件。这样做的好处就是加载时只需要读入定义的注册表达式而不需要加载全部文件,大大缩短了 emacs 启动时 的加载时间。注意这只是为了节省启动时间,如果我们最终还是要加载所有的模块,那总用时只多不少(毕竟还要算上加载注册表达式的时间),但这样一来感知上应该没有太大感觉了,加载时间被分散了。如果我们需要频繁启动 emacs 的话这点时间还是挺有用的。
具体来说,使用 autoload 就是使用包含注册表达式的文件替代了原来的文件进行加载,比如对于 foo.el ,我们根据文件中的内容选取我们想要 autoload 的定义,然后把注册表达式写到 foo-auto.el 中,在自己的配置文件中加上 (load "foo-auto") 即可。举例来说,假设 foo.el 的内容如下所示:
;; foo.el
(defun foo (x) (+ x 2))
我们可以创建并加载如下的 foo-auto.el 文件,记得把当前目录添加到 load-path :
;; foo-auto.el
(autoload 'foo "foo")
我们在加载 foo-auto.el 后就可以尝试调用 (foo 2) 了,不出意外的话我们可以得到返回值 4 。可见 autoload 成功地完成了它的工作。如果函数比较少我们可以这样手动添加,但是函数数量一多这样做就很蠢了。
所幸除了手写 autoload 外 emacs 还提供了另外一种机制,我们可以在函数的前面加上魔法注释 ;;;###autoload ,就像这样:
;; foo.el
;;;###autoload
(defun foo (x) (+ x 2))
这段注释本身没什么用,我们需要其他的命令来根据注释生成对应的 autoload 表达式。如果你看过文档你应该会知道一个叫做 update-file-autoloads 的函数,它会根据魔法注释创建 autoload 调用并添加到输出文件中。对于上面的 foo.el ,我们可以如此调用:
(update-file-autoloads (expand-file-name "foo.el") nil (expand-file-name "foo-a.el"))下面是生成的 autoload 文件:
;;; foo-a.el --- automatically extracted autoloads -*- lexical-binding: t -*-
;;
;;; Code:
^L
;;;### (autoloads nil "foo" "foo.el" (25601 46374 0 0))
;;; Generated autoloads from foo.el
(autoload 'foo "foo" "\
\(fn X)" nil nil)
;;;***
^L
(provide 'foo-a)
;; Local Variables:
;; version-control: never
;; no-byte-compile: t
;; no-update-autoloads: t
;; coding: utf-8
;; End:
;;; foo-a.el ends here
根据文档的内容来看, update-file-autoloads 的用处似乎是用于 emacs 在安装时生成 autoload 并输出到 loaddefs.el 中。如果我们仅指定第一参数,该函数会直接报错,这是因为我们所处的环境与安装环境不同。如果你通过 emacs 的 package 功能安装过包,你可以在包目录下发现 xxx-autoload.el 的文件,这是包在安装过程中 package.el 做的处理。它通过调用 make-directory-autoloads 为目录下所有的文件根据魔法注释生成包含 autoload 的文件。
所幸这几天我在 Ubuntu 上尝试编译了 emacs 30.0.50,然后我发现整个 autoload.el 已经被废弃了:
;;; autoload.el --- maintain autoloads in loaddefs.el -*- lexical-binding: t -*-
;; Copyright (C) 1991-1997, 2001-2023 Free Software Foundation, Inc.
;; Author: Roland McGrath <[email protected]>
;; Keywords: maint
;; Package: emacs
;; Obsolete-since: 29.1
;;; Commentary:
;; This code helps GNU Emacs maintainers keep the loaddefs.el file up to
;; date. It interprets magic cookies of the form ";;;###autoload" in
;; Lisp source files in various useful ways. To learn more, read the
;; source; if you're going to use this, you'd better be able to.
;; The functions in this file have been superseded by loaddefs-gen.el.
;; Note: When removing this file, also remove the references to
;; `make-directory-autoloads' and `update-directory-autoloads' in
;; subr.el.
而且就连 28 中的注释也建议我们不要使用 update-file-autoloads :
;; FIXME This command should be deprecated.
;; See https://debbugs.gnu.org/22213#41
;;;###autoload
(defun update-file-autoloads (file &optional save-after outfile)
...)
在 emacs 28 中, package.el 中调用 make-directory-autoloads 来生成包的 autoload 文件,而在 29 及以上中调用的是 loaddefs-generate :
;; emacs 30.0.50
(defun package-generate-autoloads (name pkg-dir)
"Generate autoloads in PKG-DIR for package named NAME."
(let* ((auto-name (format "%s-autoloads.el" name))
;;(ignore-name (concat name "-pkg.el"))
(output-file (expand-file-name auto-name pkg-dir))
;; We don't need 'em, and this makes the output reproducible.
(autoload-timestamps nil)
(backup-inhibited t)
(version-control 'never))
(loaddefs-generate
pkg-dir output-file nil
(prin1-to-string
'(add-to-list
'load-path
;; Add the directory that will contain the autoload file to
;; the load path. We don't hard-code `pkg-dir', to avoid
;; issues if the package directory is moved around.
(or (and load-file-name (file-name-directory load-file-name))
(car load-path)))))
(let ((buf (find-buffer-visiting output-file)))
(when buf (kill-buffer buf)))
auto-name))
由于现在 emacs 29 的文档还未出现(指还没有挂上官方文档的网页,如果自己编译的那么 info 里有),我也懒得去分别读一遍 autoload.el 和 loaddefs-gen.el 的实现,由于 autoload 是 C 中实现的,所以这两个文件和它的关系没那么大,我们这里就从 autoload 这个函数分析起。它的原型如下:
(autoload FUNCTION FILE &optional DOCSTRING INTERACTIVE TYPE)
我在 eval.c 和 subr.el 中找到的和 autoload 有关的函数有 autoload , autoload-do-load , un_autoload 和 autoloadp 四个函数,整个 autoload 核心应该就是它们了。我们先从 autoload 开始说起。
autoload 可以用来定义自动加载的函数或宏 FUNCTION , FILE 指定了从其中获取 FUNCTION 定义的文件。如果 FILE 即不是目录名也没有后缀,那么 autoload 会认为它有 el 或 elc 后缀,且不会加载名称仅为 FILE 的文件。
参数 DOCSTRING 是函数的文档字符串,如果我们在 autoload 中指定了它,那么我们在查看函数的文档时就不需要加载函数的定义。一般来说它应该和函数真正的文档字符串一致,如果不一致的话,在函数真正载入后你看到的文档字符串就是真正的文档字符串。
如果 INTERACTIVE 非空,这就表示函数可以被作为命令调用。这样在按下 M-x 且补全时不会加载该函数。如果 INTERACTIVE 是一个表,那么它会被解释为命令适用的各个 mode。
如果 autoload 的对象不是 function,那么我们需要通过 TYPE 指定类型,比如对宏用 macro ,对 keymap 用 keymap ,文档似乎只给出了这两种类型。
如果 autoload 的函数已经存在于 emacs 中(指 symbol 的 function cell 非空),那么 autload 什么也不做并返回 nil :
/* If function is defined and not as an autoload, don't override. */
if (!NILP (XSYMBOL (function)->u.s.function)
&& !AUTOLOADP (XSYMBOL (function)->u.s.function))
return Qnil;
否则它会构建起一个 autoload 对象,然后将函数定义存储在其中,
return Fdefalias (function,
list5 (Qautoload, file, docstring, interactive, type),
Qnil);对象形式如下:
(autoload filename docstring interactive type)
我们可以通过 autoloadp 来判断某个对象是不是 autoload 对象,比如 (autoloadp (symbol-function 'foo)) 。
既然有了 autoload 对象,那么接下来要看的就是真正定义的载入过程了,它是通过 autoload-do-load 进行的,我们可以在 eval_sub 函数(位于 eval.c)中找到对它的调用:
if (EQ (funcar, Qautoload))
{
Fautoload_do_load (fun, original_fun, Qnil);
goto retry;
}
autoload-do-load 的实现也位于 eval.c 中,它在内部调用 load_with_autoload_queue 完成加载工作,这个函数在遇到错误时会 Undo 之前的加载内容。这也就是文档中说明的行为:如果在 autoload 真正定义的加载过程中出现了错误,那么所有加载的函数定义或 provide 表达式会被回退。这样可以保证下一次对 autoload 函数的加载会尝试重新加载文件。如果不这样做的话,有些函数可能会在错误加载过程中被加载,但是它们可能因为缺少某些子函数而不能正常工作。
un_autoload 会被 load_with_autoload_queue 使用,这里我就不介绍了。对我们用户来说,真正重要的只有 autload 这个函数而已。
文档中说魔法注释也可叫做 autoload cookie ,它位于我们想要 autoload 函数的上一行。上面我们提到了可以调用 update-file-autoloads 来获取文件中的 autoload 函数并输出到一个文件中,由于这个函数已经(即将)被废除了,这里我就不过多说明了。
文档中说到,我们还可以在魔法注释的后面加上一些表达式在 autoload 文件加载时被调用,使用如下文件:
;;;###autoload (message "Hello")在生成 autoload 文件后,我们可以在文件中看到:
;;; la.el --- automatically extracted autoloads -*- lexical-binding: t -*-
;;
;;; Code:
^L
;;;### (autoloads nil "foo" "foo.el" (25601 59122 0 0))
;;; Generated autoloads from foo.el
(message "Hello")
;;;***
^L
(provide 'la)
可见确实有用。如果我们使用的定义方式不是 autoload 能够识别的,我们可以使用相同的方式来加载,比如下面的 foo :
;;;###autoload (autoload 'foo "myfile")
(mydefunmacro foo
...)
autoload 能够识别的定义形式可以参考文档。
这里我们介绍一些可用于生成 autoload 文件的函数,由于 update-file-autoloads 已经废弃了这里就不介绍了。
(make-directory-autoloads dir output-file),对位于目录中的文件更新 autoload 定义,dir可以是一个目录或目录组成的表(不建议用表),生成的 autload 会输出到output-file(update-directory-autoloads &rest dirs),对位于 dirs 中的 lisp 文件更新 autoload ,并将 autoload 输出到generated-autoload-file,如果通过M-x调用该命令则需手动输入目标文件。同样,这个函数也不建议使用多目录
我在 emacs 30.0.50 中的 subr.el 中找到了关于这两个函数的说明:
;; These are in obsolete/autoload.el, but are commonly used by
;; third-party scripts that assume that they exist without requiring
;; autoload. These should be removed when obsolete/autoload.el is
;; removed.
(autoload 'make-directory-autoloads "autoload" nil t)
(autoload 'update-directory-autoloads "autoload" nil t)也许这两个函数永远都不会消失吧(笑)。
最后就是我们的新函数 loaddefs-generate ,这里简单展示一下它的用法,还是使用我们上面的 foo.el :
;;;###autoload
(defun foo (x) (+ x 2))
然后调用 (loaddefs-generate default-directory "f.el") ,我们会得到:
;;; f.el --- automatically extracted autoloads (do not edit) -*- lexical-binding: t -*-
;; Generated by the `loaddefs-generate' function.
;; This file is part of GNU Emacs.
;;; Code:
^L
;;; Generated autoloads from foo.el
(autoload 'foo "foo" "\
(fn X)")
^L
;;; End of scraped data
(provide 'f)
;; Local Variables:
;; version-control: never
;; no-byte-compile: t
;; no-update-autoloads: t
;; no-native-compile: t
;; coding: utf-8-emacs-unix
;; End:
;;; f.el ends here
请在 29 以上的版本尝试上面的操作。自 29 版本之后我们需要使用的应该只有 loaddefs-generate 了吧。
文件建议我们仅在必要的时候添加魔法注释。一旦函数作为 autoload 被引入,那么没有比较好的办法来让 emacs 回到没有引入的状态。对此文档给出了如下建议:
- 一般应该被 autoload 的是库的交互起始点,比如
python-mode,scheme-mode等等,这样用户可以通过M-x python-mode来加载库 - 变量一般不需要 autoload。不过如果变量在整个库没有加载但仍然有用的时候可以考虑为它添加魔法注释
- 不要只是为了让用户能够设定,就对用户选项添加 autoload
- 不要添加魔法注释来消除编译器警告,而应该使用
(defvar foo)或declare-function来消除
关于 autoload 在没有 package 管理的情况下如何使用,网上有非常多的方案,由于本文的目的是介绍 autoload 机制而不是介绍具体的方法,这里就不过多展开了。读者可以使用 autoload , 加载 等关键字搜索。
在文档的 16.6 这一节中,文档建议我们考虑对某一文件多次调用 load 的可能性,并注意 elc 优先于 el 被载入。由于内容比较简单这里我就不多说了,让我们直接来到下一节,即 emacs 的 require/provide 机制。
所谓的 feature 就是代表一系列函数或变量的一个符号,比如我 (require 'cl-lib) ,那我就将 cl-lib 这个 feature 载入了 emacs,然后我就可以使用 cl-lib 中的函数了,比如 cl-incf 。一个文件可以通过 provide 向 emacs 提供 feature,比如 (provide 'cl-lib) 。一般来说 feature 就是不带后缀的文件名,和 elisp 文件保持一致,如果不一致的话我们可以通过 require 的额外参数指定对应的文件,我会在下面详细介绍 require 和 provide 。
如果 require 的 feature 还没有载入 emacs,那么它会被 require 通过 load 加载,如果它能在 features 这个表中找到对应的 feature,那么 require 就什么也不做。 provide 的作用就是向 features 中添加新的 feature 符号。在我们调用 provide 后 emacs 就会执行对应 feature 的 eval-after-load 。
原先我一直以为把 provide 表达式放在文件的最后是为了避免因为加载过程出现错误而导致 feature 被过早地加入 features ,读了文档后我发现如果在 require 的 load 过程出现错误所有的求值都会被回退。现在看来应该和 eval-after-load 有关。
require 的函数原型如下:
(require FEATURE &optional FILENAME NOERROR)
其中 FEATURE 就是一个符号, FILENAME 是可选的加载文件,如果 NOERROR 非空,那么 require 中出现的错误不会引发异常,此时 require 会返回 nil 。如果调用成功, require 会返回 feature 符号。
provide 的函数原型如下:
(provide FEATURE &optional SUBFEATURES)
如果 FEATURE 不在 features 中,它会将 FEATURE 添加到 features 的最前面。这里出现的可选参数 SUBFEATURES 如果给出就会添加到符号 FEATURE 的 plist 中:
tem = Fmemq (feature, Vfeatures);
if (NILP (tem))
Vfeatures = Fcons (feature, Vfeatures);
if (!NILP (subfeatures))
Fput (feature, Qsubfeatures, subfeatures);
LOADHIST_ATTACH (Fcons (Qprovide, feature));
根据文档的说法,如果一个包复杂到了一定程度,我们需要给包中不同部分起名,这就是 SUBFEATURES 起作用的时候。至少到目前位置我从来没看到过这个第二参数的使用。文档给出了一个例子。
在 provide 结束添加 ferature 后,它会调用各处使用它的 eval-after-load ,然后返回:
/* Run any load-hooks for this file. */
tem = Fassq (feature, Vafter_load_alist);
if (CONSP (tem))
Fmapc (Qfuncall, XCDR (tem));
return feature;
我们可以使用 featurep 来判断某个 feature 是否已经载入 emacs 了,它的函数原型如下:
(featurep FEATURE &optional SUBFEATURE)这个函数是比较简单的,如果存在 FEATURE 它就会尝试比较 SUBFEATURE :
DEFUN ("featurep", Ffeaturep, Sfeaturep, 1, 2, 0,
doc: /* Return t if FEATURE is present in this Emacs.
Use this to conditionalize execution of lisp code based on the
presence or absence of Emacs or environment extensions.
Use `provide' to declare that a feature is available. This function
looks at the value of the variable `features'. The optional argument
SUBFEATURE can be used to check a specific subfeature of FEATURE. */)
(Lisp_Object feature, Lisp_Object subfeature)
{
register Lisp_Object tem;
CHECK_SYMBOL (feature);
tem = Fmemq (feature, Vfeatures);
if (!NILP (tem) && !NILP (subfeature))
tem = Fmember (subfeature, Fget (feature, Qsubfeatures));
return (NILP (tem)) ? Qnil : Qt;
}我们可以用一个例子说明 subfeature 是如何使用的:
(provide 'yyemacs-1 '(:use-native-comp
:use-sqlite
:use-company))
(featurep 'yyemacs-1) => t
(featurep 'yyemacs-1 :use-native-comp) => t
(featurep 'yyemacs-1 :use-sqlite) => t
(featurep 'yyemacs-1 :use-company) => t
(featurep 'yyemacs-1 :use-yy) => nil
我们可以使用 symbol-file 来找到这个符号被定义的文件,这是通过查找 load-history 这个变量来完成的。 load-history 是一个 alist,其中 key 是文件的决定路径,value 是文件中经过求值的表达式,一共有这几种形式:
var,表示变量(defun . fun),表示函数(t . fun),表示在文件载入前已有该函数的 autoload 对象,它后面总是跟着(defun . fun)(autoload . fun),表示 autoload 表达式(defface . face),表示 face(require . feature),表示 require(provide . feature),表示 provide(cl-defmethod method specializers),表示 cl-defmethod(define-type . type),表示定义的 type
你可以通过 C-h v load-history 来观察这个变量的值。
我们可以通过 unload-feature 来撤销对某个 feature 的 require,它会取消掉对函数,变量,宏等在 feature 中定义的东西,并将 autoload 对象重新赋给对应的符号。根据文档内容来看,它会处理 defun, defalias, defsubst, defmacro, defconst, defvar, defcustom 。
在回退开始前该函数会执行 remove-hook 来移除一些钩子中的在这个库中定义的函数,这些钩子包括以 -hook 结尾的变量加上在 unload-feature-special-hooks 中列出的那些,以及 auto-mode-alist 。这样做是为了避免因为在一些比较重要的钩子中调用已不存在的函数而引发可能的 emacs 崩溃的出现。
如果默认的回退行为还不够,我们可以在库中定义 feature-unload-function (其中 feature 是这个库的 feature 名)。如果我们定义了这个函数, unload-feature 会在做任何其他事情之前对它进行无参调用。如果它返回 nil , unload-feature 会继续执行一般的回退,如果它返回 t ,那么 unload-feature 就认为它的事情干完了。
一般情况下 unload-feature 不会回退被其他库依赖的库(其他库通过 require 引入了该库),但如果指定 unload-feature 的第二参数(可选)为非空,那么该函数不会在意某个库是否是其他库的依赖项。
after-load-functions 这个钩子会在加载一个文件后被调用,钩子中的每个函数都会使用加载文件的绝对路径作为参数被调用。不过既然这个钩子以 functions 结尾,作为普通用户的我们最好还是不要动它。
如果你抄过别人的配置的话,你应该看到过 eval-after-load 和 with-eval-after-load 的使用。后者是对前者的简单包装,所以这里我只是简单介绍下 eval-after-load 吧:
(defmacro with-eval-after-load (file &rest body)
"Execute BODY after FILE is loaded.
FILE is normally a feature name, but it can also be a file name,
in case that file does not provide any feature. See `eval-after-load'
for more details about the different forms of FILE and their semantics."
(declare (indent 1) (debug (form def-body)))
`(eval-after-load ,file (lambda () ,@body)))
(eval-after-load file form)
eval-after-load 会在 file 每一次 被加载时执行 form 表达式。如果库已经被载入了,那么调用 eval-after-load 会立即执行 form 。从这个特性来看 eval-after-load 能与 autoload 很好的配合,我们可以把一些要执行的表达式留到包加载之后。
文档中说到:良好设计的 elisp 程序一般不会使用 with-eval-after-load 。但对我们一般用户来说,用户配置就不用管这个告示了。
在下一篇文章中,我会对 emacs 内置的包管理器做一些介绍,不过也说不好,也许是 use-package 呢?