LSP 是 Language Server Protocol 的缩写,该协议被用在编辑器或 IDE 与语言服务器之间,为编辑器提供自动补全,跳转到定义和引用查找等功能。以下内容来自 LSP 官网:
Adding features like auto complete, go to definition, or documentation on hover for a programming language takes significant effort. Traditionally this work had to be repeated for each development tool, as each tool provides different APIs for implementing the same feature.
A Language Server is meant to provide the language-specific smarts and communicate with development tools over a protocol that enables inter-process communication.
The idea behind the Language Server Protocol (LSP) is to standardize the protocol for how such servers and development tools communicate. This way, a single Language Server can be re-used in multiple development tools, which in turn can support multiple languages with minimal effort.
LSP is a win for both language providers and tooling vendors!
为一种编程语言添加自动补全,跳转到定义或悬停文档等功能需要很大的努力。在过去需要为每个开发工具重复这项工作,因为每个工具都提供不同的 API 来实现相同的功能。
语言服务器旨在提供特定语言的功能,并通过支持进程间通信的协议与开发工具进行通信。
语言服务协议(LSP)背后的想法是对此类服务器和开发工具如何通信的协议进行标准化。这样,单个语言服务器可以在多个开发工具中重复使用,从而可以以最小的努力支持多种语言。
LSP 是语言开发者和工具开发者的双赢!
下面正式开始译文内容,在本翻译完成时原文的更新时间是 2022 年 4 月 25 日。
当下 LSP(language server protocol)非常流行。对于为什么会这样有一个标准的解释。你之前可能看到过这张图片:

我相信这个对 LSP 流行的标准解释是有问题的。本文中我会展示另一种图景。
标准解释是这样的:
有 M 个编辑器和 N 种语言。如果你想在一个特定的编辑器中支持一种特定的语言,你需要为其编写一个专门的插件。对所有的语言和编辑器,这意味着 M * N 的工作,正如左图生动地展示的那样。LSP 所做的是通过提供一个共同的桥梁(thin waist),将其削减为 M + N,就像右图那样。
这个问题也最好通过画图来说明。简而言之,上面的图片比例不太对,这里有一个更好的说明,例如,rust-analyzer 和 VS Code 是这样一起工作的:
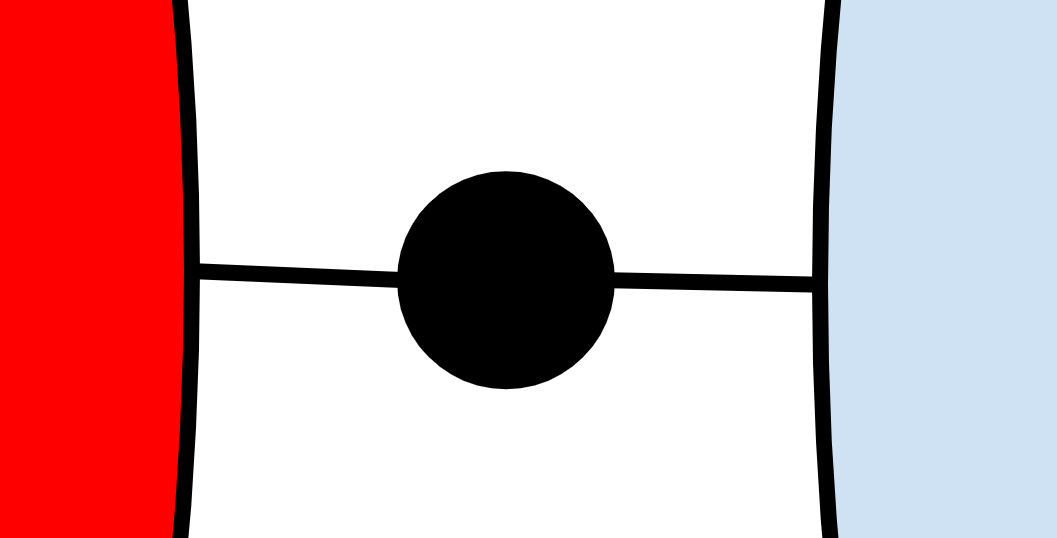
左边的(大)球是 rust-analyzer —— 一个语言服务器。右边相似大小的球是 VS Code —— 一个编辑器。中间的小球是把它们粘在一起的代码,它 包括 LSP 的实现。
这一部分代码不论是相对意义还是绝对意义上都很小。语言服务器和编辑器背后的代码库是巨大的。
如果标准解释是正确的,那么,在 LSP 出现之前,我们会生活在一个某些语言在某些编辑器中拥有极好的 IDE 支持的世界里。比如,IntelliJ 会提供非常好的 Java 支持,再比如 Emacs 对 C++ 或 Vim 对 C# 会提供很好的支持,等等。我对那个时代的回忆是完全不同的。为了得到一个像样的 IDE 支持,你要么使用 JetBrains 产品(如 IntelliJ 或 ReSharper)支持的语言,要么。(译注:此处的 either … or 的 or 后面什么也没有,作者也许想表达别无选择的意思)
只有一个编辑器提供了有意义的语义 IDE 支持。(译注:此处的原文是 There was just a single editor providing meaningful semantic IDE support. 我猜作者想表达的意思是:对于一种语言,一般只会有一种编辑器为其提供 IDE 级别的支持)
我想说,过去 IDE 支持如此之差的原因并不是这个。与其说 M * N 太大,不如说是太小,因为 N 是 0,而 M 只是比它略多。
我想从语言服务器的数量,也就是 N 开始。这是我相对熟悉的那一侧。在 LSP 之前,根本没有很多像是语言服务器一样可用的东西,主要原因是构建语言服务器很困难。语言服务器的本质复杂度(essential complexity)相当地高。众所周知,编译器是很复杂的,而语言服务器在编译器的基础上还要 加上别的东西 。
首先,像编译器一样,语言服务器需要完全理解语言,它需要能够区分有效和无效的程序。然而,对于无效的程序,批处理编译器(batch compiler)可以发出错误信息并及时退出,而语言服务器必须尽可能地分析任何无效的程序。与编译器相比,处理不完整和无效的程序是语言服务器的第一个复杂问题。
第二,批处理编译器可看作将源代码文本转化为机器码的 纯函数 ,而语言服务器必须与一个不断被用户修改的代码库一起工作。它是一个具有时间维度的编译器,而状态随时间的演变是编程中最难的问题之一。
第三,批处理编译器是为最大的吞吐量而优化的,而语言服务器的目标是最小化延迟(同时不完全放弃吞吐量)。增加一个延迟要求并不意味着你需要更努力地优化。相反,它意味着你通常需要把架构颠倒过来,才能有一个可接受的延迟。
这就把我们带到了围绕语言服务器的偶然复杂度(accidental complexity)的一丛(cluster)相关问题中。如何编写批处理编译器是很好理解的,这是一般的知识。虽然不是每个人都读过龙书(我没有真正读过解析章节),但每个人都知道那本书包含了所有的答案。因此,大多数现有的编译器看起来就是个典型的编译器。当编译器作者开始考虑对 IDE 的支持时,第一个想法是“好吧,IDE 有点像编译器,而我们有一个编译器,所以问题解决了,对吗?”。这是完全错误的 —— 在内部,IDE 与编译器是非常不同的,但直到最近,这还不是一个常识。
语言服务器是“永不重写”规则的一个反例。大多数受到好评的语言服务器都是批处理编译器的重写或替代实现。IntelliJ 和 Eclipse 都编写了自己的编译器,而不是在 IDE 中重用 javac。为了给 C# 提供足够的 IDE 支持,微软把他们的 C++ 批处理编译器重写为一个交互式的自托管(self-hosted)编译器(project Roslyn)。尽管 Dart 是一种全新的、相对现代的语言,但它最终有三种实现(主机 AOT 编译器、主机 IDE 编译器(dart-analyzer)、设备上(on-device) JIT 编译器)。Rust 尝试了两种方法 —— rustc(RLS)的增量演进和从头开始的实现(rust-analyzer),rust-analyzer 最终获胜。
我知道的两个例外是 C++ 和 OCaml。奇怪的是,两者都需要前向声明和头文件,我认为这不是一个巧合。详见 Three Architectures for a Responsive IDE。
总而言之,在语言服务器方面,事情处于一种糟糕的平衡状态。实现语言服务器是完全可能的,但这需要一种打破常规的方法,而要成为一个先驱性的标志性人物是很难的。
我不太确定在编辑器那一侧发生了什么。不过我还是想说,我们没有能够成为 IDE 的编辑器。
IDE 体验由一系列的语义特性组成。最显著的例子当然是补全。如果想为 VS Code 实现自动补全,则需要实现 CompletionItemProvider 接口:
interface CompletionItemProvider {
provideCompletionItems(
document: TextDocument,
position: Position,
): CompletionItem[]
}这意味着,在 VS Code 中,代码补全(以及许多其他 IDE 相关功能)是编辑器中的 first-class 概念,具有统一的用户 UI 和开发者 API。
将此与 Emacs 和 Vim 进行对比。他们只是没有把合适的补全作为编辑器的扩展点。相反,它们暴露了低级别的光标和屏幕操作 API,然后人们在此基础上实现了各种相互竞争的补全框架!
而这仅仅是代码补全!还有参数信息(parameter info)、内嵌提示(inlay hints)、面包屑(breadcrumbs,指 VS Code 的面包屑导航,可以展示目前的代码在整个工程里的路径)、扩展选择(extend selection)、辅助(assist)、符号搜索(symbol search)、用途查找(find usages)(其他的我就不说了 ^_^)呢?
简而言之,没有像样的 IDE 支持的问题并不是 N * M,而是两边市场的不充分平衡。
语言提供商不愿意做语言服务器,因为这很难,而且需求低(没有来自其他语言的竞争),而且即使创建了语言服务器,也会发现有至少一打编辑器完全没有准备好作为智能服务器的主机。
在编辑器一侧,添加 IDE 所需的高级 API 的动机很小,因为这些 API 没有潜在的提供者。
这也是为什么我认为 LSP 是伟大的!
我不认为这是一项重大的技术革新(很明显,你是想把一个语言无关的编辑器和语言特定的服务器分开的)。我认为它是一个相当糟糕(也就是“恰到好处”)的技术实现(请期待“Why LSP sucks?”,(译注:现在是 2022-12-15,作者还没写))。但它把我们从一个认为没有语言 IDE 是理所当然的,甚至没有人考虑语言服务器的世界,带到了一个没有工作补全和跳转到定义的语言看起来就不专业的世界。
值得注意的是,微软解决了两边市场的问题,他们同时是语言(C# 和 TypeScript)和编辑器(VS Code 和 Visual Studio)的供应商,而且他们在 IDE 领域通常输给了竞争对手(JetBrains)。虽然我可能抱怨 LSP 的一些技术细节,但我绝对佩服他们在这个特定领域的战略眼光,他们:
- 建立了一个基于 web 技术的编辑器
- 将 webdev 确定为一个巨大的利基市场(niche,意为小众市场),JetBrains 在这个市场上挣扎(在一个 IDE 中支持 JS 几乎是不可能的)
- 构建了一种语言(!!!!),使为 webdev 提供 IDE 支持成为可能
- 构建了一个具有非常前瞻性架构的 IDE 平台(请继续关注我的帖子,我会解释 why vscode.d.ts is a marvel of technical excellence )
- 推出 LSP,以免费增加其平台在其他领域的价值(作为附带利益,将整个世界推向更好的 IDE 平衡)
- 现在,随着 code space 的出现(译注:github 提供的一项服务,可以在浏览器中使用 vscode 远程写代码),如果我们真的停止了在本机上编辑、构建和运行代码,他们将成为“远程优先开发”领域的主导者
不过,公平地说,我仍然希望最终的赢家是 JetBrains,他们认为 Kotlin 是任何平台的通用语言 :-) 微软充分利用了目前占主导地位的 worse-is-better 技术(TypeScript 和 Electron),而 JetBrains 则试图自下而上地解决问题(Kotlin 和 Compose)。
现在我要强调这真不是 M * N 的问题。
首先,M * N 的说法忽略了一个事实,即这是一个令人尴尬的平行问题。既不需要语言设计者为所有的编辑器编写插件,也不需要编辑器为所有的语言添加特殊支持。相反,一种语言应该实现一个使用某种协议的服务器,一个编辑器需要实现与语言无关的 API 来提供补全等功能,而且,如果语言和编辑器都不深奥,那么对两者都感兴趣的人只需要写一点胶水代码就可以将两者结合起来!Rust-analyzer 的 VS Code 插件有 3.2k 行代码,neovim 插件有 2.3k 行,Emacs 插件是 1.2k 行。这三个插件都是由不同的人独立开发的。这就是去中心化的开源开发的魔力,さいこう!如果这些插件支持自定义协议而不是 LSP(前提是编辑器内部支持高级 IDE API),我估计需要为此还需要 2k 行左右的代码,这对于业余兼职开发者仍是力所能及的。
其次,为了优化 M * N 问题,你可能希望协议实现是从一些机器可读的实现生成的。但是直到最新的版本,LSP 规范的来源是一个非正式的 markdown 文档。每种语言和客户端都想出了自己的方法来提取其中的协议,许多人(包括 rust-analyzer)只是手动同步更改,有相当多的重复。
第三,如果 M * N 是一个问题,你会期望每个编辑器只有一个 LSP 实现。实际上,Emacs 中有两个相互竞争的 LSP 实现(lsp-mode 和 eglot),而且我在写 rust-analyzer 的手册时,包含了 6(six) 个不同的 vim LSP 客户端集成的说明,我可没有骗你。让我们再重复第一点,这就是开源!工作总量几乎无关紧要,重要的是完成工作的需要做出的协调。
第四,微软并没有试图利用 M + N 的优势。在 VS Code 中没有通用的 LSP 实现。相反,每一种语言都需要有一个专用插件,其中包含物理上独立的 LSP 实现。
请期待更好的 IDE 支持!我认为今天我们已经跨过了基本的 IDE 支持的门槛,但是除了基本的支持之外,我们还有很多事情可以做。在理想的世界里,我们应该可以使用像检查编辑器 buffer 内容的一样简单的 API,来在光标处检查关于表达式的每一个小的语义细节。
请关注 VS Code 的架构,虽然 Electron 的用户体验值得商榷,但其内部结构却有很多智慧之处。将编辑器的 API 定位在与表现无关的高级功能上。基本的 IDE 功能应该是一个 first class 扩展点,它不应该被每个插件的作者重新发明。特别是将 assist/code action/💡 作为 fist-class 的用户体验概念。这是 IDE 最重要的用户体验创新,虽然它已经出现很久了。而这居然还不是所有编辑器的标准界面,这实在是太荒谬了。
但不要让 LSP 本身成为一个 first class 概念。虽然看起来很惊讶,但是 VS Code 对 LSP 一无所知。它只是提供了一堆扩展点,而不关心它们是如何实现的。LSP 实现只是一个库,由特定语言的插件使用。例如,VS Code 的 Rust 和 C++ 扩展在运行时并不共享相同的 LSP 实现,内存中存在两份 LSP 库!
此外,尝试利用开源的力量。不要强制所有的 LSP 实现都中心化!让不同的团队能够独立地为你的编辑器提供完美的 Go 支持和完美的 Rust 支持。Vs Code 是一个可能的模式,它有一个插件市场和分布式的独立插件。但是,只要语言有独立的维护者,就有可能将工作组织成一个共享的 repo/source tree。
你做得很好!所有语言的 IDE 支持质量都在迅速提高,尽管我觉得这只是漫长道路的一个开始。有一点需要注意的是,LSP 是一个 关于语言语义信息 的接口,但它并不是接口。一个更好的东西可能会出现。即使在今天,LSP 的局限性也阻碍了有用功能的推出。所以,尽量把 LSP 当作一种序列化格式,而不是一种内部数据模型。并尝试写更多关于如何实现语言服务器的文章 —— 我觉得在这方面的知识还不够。
以上です!
P.S. 如果你有机会从使用 rust-analyzer 中受益,请考虑赞助 Ferrous Systems Open Source Collective for rust-analyzer,以支持它的发展!
我在想着找个类似 SQL 提供一个简单接口的例子时偶然发现了这篇文章,本来我的想法是使用类似 LSP 将 M * N 转化为了 M + N 问题来说明 SQL 在其中发挥的类似作用,看来对 LSP 的认识还是不怎么够,毕竟就没怎么用过。
现在看来,LSP 与其说是解决了 M * N 问题,不如说是做了第一个吃螃蟹的人,或者说是“鲢鱼效应”的产生者。LSP 协议将 IDE 提供的常规功能规范化了,这样语言服务器的开发者不愁开发出来没人用,编辑器开发者只要提供了 API 就能用上别人的语言服务器,现在成了个 win-win 局面。学点编译原理现在看来也不是屠龙之技,抄一下其他已有的语言服务器的大致代码应该就可以弄个简单的出来。
我没怎么学过 Rust,不知道 Alex Kladov 是不是 Rust 的开发者之一,不过他的头像上确实有螃蟹(笑)。
