在一个小型企业中,网络管理员或开发人员会兼任数据库管理员(DBA,Data Base Admins)。在大型企业中,可能会有数十名 DBA 专门负责从设计与架构到维护和开发等许多不同方面的工作。不论你从事 IT 的哪一块工作,你都需要在这里或那里存储数据,对每个人来说,掌握一些数据库的知识以及数据库的工作方式并没有坏处。
本教程的目的是提供一个对数据库的基础介绍。我们会简单讲讲什么是数据库、看看数据库的历史、了解关系型数据库、了解一些从列和行开始的基本概念、接触其他类型的数据库、了解一些额外的概念、最后通过回顾当今市场上的主要商业系统来结束这一切。在大多数情况下,除了基本的计算机知识外,本教程没有任何前置条件。
在最一般的意义上,数据库是一个有组织的数据集合。更具体一点,数据库是一个电子系统,它允许数据被轻松地访问、操作和更新。换句话说,数据库被一个组织用来作为存储,管理和检索信息的电子方式。数据库是企业 IT 的基石之一,它以结构化和可控的方式组织、处理和管理信息的能力是现代企业效率的许多方面的关键。
然而,数据库远远不止简单地存储数据。就像我们将在后面看到的,在如何存储和检索数据方面的内在逻辑和效率可以为一个组织提供一个令人难以置信的强大的商业工具。尤其是当数据库被适当地利用其报告和商业智能(BI,Business Intelligence)能力时。
当下数据库的用途及其重要性
那么,什么样的组织需要数据库并能从数据库的使用中受益呢?答案是需要追踪巨量用户或产品的企业或组织。这里的“巨量”指的是远超人脑记忆的量。
在这一点上,持怀疑态度的人可能仍然会说,数不清的夫妻店使用可靠的账簿和计算器来跟踪库存和损益,而且还做的很不错。此言不虚,但即使是对于非常小的企业,使用电子数据库仍然可以得到回报。例如,如果商店把圆珠笔的价格提高 2 美分,账本没法运行仿真来推断利润,数据库可以做到这一点。账本没法运行一份报告来跟踪所有商品的缺货情况,来提醒店主在一年中的什么时候需要补货,而数据库可以做到这一点。数据库甚至可以通过电子邮件或短信自动提醒店主。
然而,数据库最显著的好处仍然限于大型组织,它们的客户和产品数量多达几十万、几百万或几千万,需要为客户存储大量的单独数据项。例如,一家商业银行需要其上百万用户的个人资料,如名字、生日、住址、社会保障号码(SSN,Social Security Number)等。每个客户又会根据他注册的产品产生另一个数据集合,如账户类型、账户号码、账户余额、抵押贷款金额、信用卡贷款、还款期等等。第三个数据集合与客户的具体交易相关,如交易时间、金额、剩余余额、银行收费、剩余还款额等。
显然,单个用户可以在短时间内产生巨量的数据。将其乘以数百万的客户,就不难理解为什么拥有一个高效的数据存储和检索媒介不仅是一个好主意,而且对于防止银行的运营陷入停顿也是绝对必要的。
等等,在计算机和这些新奇的数据库出现之前,那些组织不照样正常运转吗?如果你还不相信基于提高效率和交易速度的数据库的力量,请考虑一下:你的竞争对手由于使用了数据库系统,会比你更有效率,提供更好的服务。
商业银行是当今组织中使用数据库的一个典型例子。其他服务严重依赖数据库的行业有保险公司、医院和医疗保健、学校和学院、制造业、电信公司以及酒店和酒店业。
数据库(Data bases)确实如其名字一样,是一个组织的数据(Data)系统应该建立于其上的基石(Base)。实际上,可以毫不夸张地说,如果没有数据库,工作场所的计算机只不过是一台更高效的打字机!
需要知道的是,这一种在很大程度上依赖数据库的、有组织有系统的记录存储方法并不是最近的发明。最近发生的是在 20 世纪 60 年代开始的这种方法的计算机化。注意到即使是纸质记录,包括记账本,从技术上来说也是一种数据库的形式。也就是说,数据库不一定非要计算机化。计算机化仅产生了数据库管理系统(DBMS,DataBase Management System),它显然要比一个简陋的账本或一个微不足道的人脑在精确性,便捷性上要强几个数量级。尽管我们经常使用数据库一词来指代 DBMS,但它们并不是同一个东西。就像所有的拇指(DBMS)是手指(数据库),但并非所有手指都是拇指一样。
古埃及人使用精心设计的记录系统来记录粮食收获。亚历山大图书馆使用了一种复杂的方法来记录大量的书籍和卷轴。这些都是数据库的古早例子,当然,与 21 世纪的计算机 DBMS 相比它们的能力看上去有点好笑。
但即便是在 1960 年代,在计算领域还处于单细胞生物阶段的时候,许多人已经看到了计算机在存储和数据检索上的可行性和可用性。因此,数据库的发展几乎与当时算力的总体发展和增长同步进行。随着磁盘容量和处理器速度的增长,当代数据库产品的存储容量和功能也在增强。20 世纪 60 年代中期发生的一个重要飞跃是,从基于磁带的存储切换到直接访问存储,即磁盘。这一改变允许多任务的交互式数据访问,而不是磁带所需要的单操作批处理。
早期的数据库系统本质上是导航型(navigational)的。这意味着应用通过 嵌入数据本身 的指针来处理和读取数据。指针指向下一块数据,而且也允许双链,允许链接到前一或后一数据项。这就像是网页中的超链接,引导读者从当前网页进入一个相关的网页。这一时期的数据模型主要分为两种,分别是集成于 IBM 的 IMS 系统的分层模型(hierarchical model)和 Codasyl(网络)模型。不过这些都已经成了历史中的有趣脚注,它们被杰出计算机科学家 E.F. Codd 提出的关系模型给打败了。
E.F. Codd 和他的关系模型
关系模型从根本上偏离了占统治地位的分层模型,它侧重于按内容搜索数据库的能力,而不是链式的导航系统。这提供了一个显著的优势,即允许数据库增长并存储越来越多的数据,而不必改变或重写访问这些数据的应用程序。从本质上讲,Codd 单枪匹马设计出了一种将数据库骨架与数据库中的数据记录分离的方法。这个模型是如此的优雅,以至于直到今天它仍然是数据库设计的事实(de facto)标准,这样的数据库被称为关系型数据库。现在也有一些非常重要的非关系型数据库(特别是随着大数据和 Web2.0 的出现),但关系型模型仍然被用于绝大多数的商业数据库产品中。
今天,E.F. Codd 的名字对大多数人来说可能是“这人谁呀”的印象,对许多 IT 人来说也是如此。然而,他的工作直接带来了提供巨大优势与效率的关系型数据库。他对计算机世界的贡献在规模上可与艾萨克·牛顿爵士对物理世界的贡献相媲美。
Codd 在牛津大学学习数学和化学,二战期间在皇家空军担任飞行员,1948 年移居美国,在 IBM 担任数学程序员。在加拿大呆了十年之后,他于 1963 年返回美国,并于 1965 年获得博士学位。
1970 年,Codd 在 IBM 发表了一篇关于数据管理的论文,题为《大型共享数据库的数据关系模型》(A Relational Model of Data for Large Shared Data Banks)。然而,这家巨头公司在其信息管理系统(IMS)上对分层模型进行了大量投入,蓝色巨人的高管们对为他们有利可图的产品线之一开发一个竞争对手不感兴趣。Codd 表现出了在学者或科学家中少有的狡诈,他狡猾地讲自己的模型展示给选定的 IBM 客户,他们在看到后立刻就体会到其优越性。这些有影响力的客户反过来又向 IBM 高层施压,要求他们开发这个模型,他们不情愿地(而且,可以想象,他们对 Codd 的愤怒悄然而生)将这个模型放在 IBM 的未来系统项目中进行开发,这个系统叫做 System R。
然而,这些头头们仍然不愿意动 IMS,并通过将 System R 项目交给不熟悉它的开发人员来破环 Codd 的工作。开发人员因此没有使用 Codd 自己的 Alpha 语言进行开发,而是选择了一种名叫 SEQUEL 的更简单的语言。这反而成了一个意外的大手笔,因为 SEQUEL 更容易理解和使用。由于版权的原因,这个名字被改成了 SQL,今天数据库开发人员和管理人员都非常熟悉这个名字,它是编写数据库查询的首选语言。
一个精明的年轻商人正在开发自己的数据库系统,他在 1979 年的一次会议上了解到了 SQL。他认识到了 SQL 的优越性,并将这种语言复制到自己小公司的数据库产品中。这位商人之前也看过 Codd 关于关系模型的工作,并确信这是数据库系统的发展方向。尽管 IBM 拒绝与他分享 System R 的代码,他还是在此基础上开发了自己的产品。记住,IBM 对关系模型不感兴趣。那家小公司已经发展得相当好;今天它被称为甲骨文(Oracle)公司。至于那个商人,他的名字叫 Larry Ellison,他的信念帮助他成为世界上最富有的人之一。这恰恰说明了 IBM 对 Codd 的关系模型潜力的误判有多严重。事实上,Oracle DB 是当今企业使用最广泛的关系型数据库。
正如我们已经看到的,Codd 的工作将关系模型确立为明显优越的数据存储方法。关系模型在存储和操作数据方面的优雅是如此有效,以至于自 20 世纪 70 年代以来,没有任何一个觊觎其王位的人能够推翻它。
让我们来详细了解一下关系模型的具体工作方式。关系型数据库本质上是一组表,或者用技术名称来说,是一组实体(entity)(参考 Codd 的关系型数据 12 规则中的第 0 条和第 1 条)。每个表都是由行(元组)和列(属性)构成的。表与表之间的关系被定义为使用一个表中的某一列来引用另一个表中的某一列。
这就是关系型数据库的基本定义。但你很快就会看到,它可以变得比这更复杂。例如,关系型数据库的一个基本概念是参照完整性(referential integrity)。这一规则指出,表之间的关系必须始终保持一致。换句话说,位于外键(foreign key)的任何字段(field)都必须与外键引用的主键(primary key)保持一致。因此,对一个主键字段的任何更新和删除都必须同时应用于它所有的外键,否则就不允许更新。同样的限制也适用于外键;任何更新(不一定是删除)也必须传播到相应的父主键(parent primary key)上,否则不允许更新。
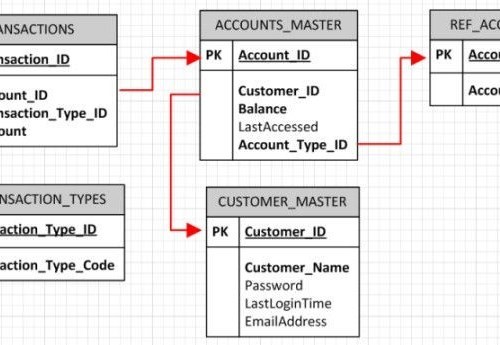
参照完整性的概念最好通过说明来解释。假设在银行的数据库中有两个表: CUSTOMER_MASTER 表用于保存客户/账户持有人的基本数据, ACCOUNTS_MASTER 表用于存储银行账户的基本数据。为了唯一地识别 CUSTOMER_MASTER 表中的每个客户/账户持有人,我们创建了一个主键列,将它称为 CUSTOMER_ID 。
你可以看到,为了识别 ACCOUNTS_MASTER 表中的某个银行账户所属的客户,我们必须引用 CUSTOMER_MASTER 表中的一个现有客户。这意味着我们也需要在 ACCOUNTS_MASTER 表中创建一个 CUSTOMER_ID 列,这就被称为外键。这个列很特别,因为它包含的值并不是随意的新值。它们必须引用另一个表的主键列中相同的现有值,在这个例子中,就是 CUSTOMER_MASTER 表的 CUSTOMER_ID 列。

很清晰不是吗?现在,参照完整性只是意味着你不能在不编辑 ACCOUNTS_MASTER 表中的相应值的情况下,编辑 CUSTOMER_MASTER 中的任何 CUSTOMER_ID 值。如果你在 CUSTOMER_MASTER 中改变了 Andrew Smith 的客户 ID,你也必须在 ACCOUNTS_MASTER 中改变它。稍微想一想你就会觉得这非常合理。不然我们如何将 Andrew Smith 的账户与他本人联系起来?记住,表 ACCOUNTS_MASTER 除了将他们的 CUSTOMER_ID 作为外键存储外,并没有保存任何关于账户持有人的信息。根据同样的逻辑,如果允许银行账户表中的客户 ID 存在,而在 CUSTOMER_MASTER 表中没有相应的客户 ID,这通常意味着一个银行账户可以没有账户持有人,这显然是不合理的。
现在,顺着这个思路再往下看,如果你删除了 CUSTOMER_MASTER 中的一个客户 ID,你也必须删除 ACCOUNTS_MASTER 中所有对应的条目。这只是现实生活中一个简单的后续行动的体现,如果某人不再是客户,你也必须取消掉他们的银行账户。正如星际迷航(Star Trek)中的 Spock 所说的那样,这是合乎逻辑的。
关系型数据库的十二条规则
当关系型模型在 20 世纪 80 年代开始成为数据库设计的时尚时,即使并不适用,所有其他数据库供应商会在他们的产品上贴上关系型标签,Codd 起初对这种趋势感到困惑和愤怒。他想到了一个由十二条规则组成的清单,来判断一个数据库是否可以被称为“关系型”。他与 IBM 的矛盾在这个时候达到了顶峰,他离开 IBM 后与一位名叫 Chris Date 的教师/顾问成立了自己的咨询公司。
下面是 Codd 的十二条规则,某些人叫它们十二条戒律。实际上有十三条,但是它们的编号是从 0 到 12,所以最后叫十二规则。一旦我们开始深入研究关系型数据库的特点,我们将更详细地研究它们,并在那时参考它们,以便你能真正理解 Codd 规则。这些原始形式的规则对于那些不在数据库领域工作的人来说没有什么意义,不过这也无所谓就是了:
- 基础规则 Foundation Rule
- 一个关系型数据库管理系统必须只通过它的关系型能力来管理存储的数据
- 信息规则 Information Rule
- 数据库中的所有信息应该使用且仅使用一种方式表示 —— 作为表中的值
- 保证访问规则 Guaranteed Access Rule
- 每一个数据(原子值)在逻辑上都可以通过使用表名、主键值(主码)和列名的组合进行访问
- 空值的系统化处理 Systematic Treatment of Null Values
- 空值(不同于空字符串,空白字符字符串,零或任何其他数字)在完全的关系型 DBMS (RDBMS)中被支持,并以系统的方式表示缺失的信息,它与数据类型无关
- 基于关系模型的动态联机数据字典 Dynamic Online Catalog Based on the Relational Model
- 数据库描述在逻辑层面上的表示方式与普通数据相同,因此授权用户可以使用相同的关系语言对其进行查询,就像用于普通数据一样
- 统一的数据子语言规则 Comprehensive Data Sublanguage Rule
- 一个关系型系统可以支持几种语言和各种终端的使用模式。然而,必须至少有一种语言,其语句可以按照某种定义明确的语法,作为字符串来表达,并能全面地支持各种规则:
- 数据定义
- 视图定义
- 数据操作(交互式操作以及通过程序操作)
- 完整性约束
- 授权
- 事务边界(事务开始、提交与回滚)(begin, commit and rollback)
- 一个关系型系统可以支持几种语言和各种终端的使用模式。然而,必须至少有一种语言,其语句可以按照某种定义明确的语法,作为字符串来表达,并能全面地支持各种规则:
- 视图更新规则 View Updating Rule
- 所有理论上可更新的视图也是可被系统更新的
- 高级的插入、更新和删除 High-Level Insert, Update and Delet
- 将基础关系或派生关系作为单一操作数处理的能力不仅适用于数据的检索,也适用于数据的插入、更新和删除
- 数据的物理独立性 Physical Data Independence
- 当存储表示或访问方法发生任何变化时,应用程序和终端活动在逻辑上保持不受影响
- 数据的逻辑独立性 Logical Data Independence
- 当对基本关系进行理论上信息不受损害的任何改变时,应用程序和终端活动都保持逻辑上的不变性
- 数据完整独立性 Integrity Independence
- 关系数据库的完整性约束条件必须是用数据库语言定义并存储在数据字典中的
- 分布独立性 Distribution Independence
- 关系数据库系统在引入分布数据或数据重新分布时保持逻辑不变
- 无破坏规则 Nonsubversion Rule
- 如果一个关系型系统拥有或支持低级语言,那么该低级语言不能被用来破坏或绕过高级关系型语言中的完整性约束或规则
现在我们来了解一些关键的数据库概念和数据对象。任何称职的数据库管理员都必须对这些概念和对象绝对熟悉。它们并不仅仅具有理论意义;几乎所有的 DBA 每天都会密切接触这些概念和对象。它们对数据库管理的作用就像人体知识对医学领域的作用一样。
这里我们只对每个术语进行简短的定义。为了更好地掌握这些概念并顺带了解现实生活的例子,请点击并访问术语链接来了解每个概念的作用,以及它与数据库管理领域中其他概念的关系。
表是关系型数据库中的基本数据存储单元。表由列和行组成。列是我们想要表达的属性或品质,而行则是实际数据,每行有一个(或没有)项。想想电子表格的布局;这与关系表的逻辑组织非常相似。
下面是一个商业银行数据库中表的简单例子:
关系是关系型数据库运行良好的根本原因。如果你只学习一个关于数据库的概念的话,那么关系就是你需要的 那个 。顾名思义,关系是关系型数据库的核心。
在关系型数据库中,当其中一个表有一个引用另一个表的主键的外键时,两个表之间就存在关系(稍后会有更多关于主键和外键的内容)。
在下图中,你可以看到关系的例子。例如,
AccountTypes 表中的 AccountTypeID 字段(列)引用了 Customer 表中的 AccountTypeID 列。
(原文中此处没有图,可能作者忘了加上去,所以我们可以看上面的一张图,可见表 ACCOUNTS_MASTER 中的 Customer_ID 列引用了表 CUSTOMER_MASTER 中的 Customer_ID 列)
行,也叫记录(record),代表了一组关于一个特定项的数据。表中的每条记录都有完全相同的结构,当然数据是不同的。想想 Excel 电子表格中的行,它与数据库中的行的概念非常相似。表中的每一行都由不同的数据项组成,表中的每一列都有一个(或零个)项。尽管不是很常见,行也被称为元组(tuple)。
请看下面的记录(行)的例子:
列是相同类型的表中的一组特定值。它定义了表或数据的一个特定属性。例如,我们可以在一个表中创建一个名为 CUSTOMER_SURNAME 的列。这是一个不言自明的列,其目的是为了存储客户的姓氏,每行一个值。同样,想想 Excel 电子表格中的行,你就会对关系表中的列是如何工作的有一个很好的概念。
主键是一个特殊的列或列的组合,用于唯一识别表中的每条记录(行)。主键列的每一行都必须是唯一的,并且不能包含任何空值。因此,假如为了在属于美国各政府部门的各种数据库中标识自己,你需要分配并使用一个唯一的标识符,即 SSN。
主键和外键是定义关系的主要方式。主键也可以是一个列的组合。例如,对许多公司来说,一个日历月是一个短期财务期。因此,为了唯一地识别任意时间,你可以把月列和年列结合起来,如 2011 年 5 月,形成一个主键来唯一地标识每一个财务时期。
就像阴阳( ^ω^)一样,我们不能只谈主键而不谈外键,这两者是相辅相成的。主键唯一地定义了一条记录,而外键用来从另一个表中引用同一记录。
在一个商业银行数据库中,假设你有一个 CUSTOMER_ID 列作为 CUSTOMER_MASTER 表中的主键。它唯一地标识了每个用户;我们还假设同一张表在其他列中也包含了其他相关的用户信息,比如 CUSTOMER_SURNAME , CUSTOMER_FIRSTNAME , CUSTOMER_SOCIAL_SEC_NUMBER , CUSTOMER , CUSTOMER_GENDER ,等等。
我们还有一个名为 LOANS_MASTER 的表,用来记录同一银行的用户的贷款。现在我们只需要在这个表中用一列来标识哪个用户获得了某项贷款。我们可以称这一列为 CUSTOMERID ,它将引用 CUSTOMER_MASTER 表中的 CUSTOMER_ID 列。我们不需要在贷款表中存储客户的所有其他信息(姓名,性别,SSN 等)。这就是关系模型的优雅之处。
结构化查询语言(SQL)是用于管理和操作关系型数据库数据的事实标准语言。SQL 可以用来查询、插入、更新和修改数据。所有主要的关系型数据库都支持 SQL,这使得数据库管理员(DBA)的生活更加轻松,因为他们必须支持多个不同平台上的数据库。熟练掌握 SQL 通常是任何 DBA 在他的职业生涯早期必须学习的东西之一。请注意,有些人将 SQL 读作一个词,即 "sequel"。
请注意,SQL 语言与微软的关系型数据库平台 SQL Server 不同。由于它使用了 SQL 这个通用术语,这可能会让初学者感到困惑。
大多数商业 RDBMS 平台都会有自己的定制 SQL 实现,但它们大都会与标准 SQL 完全兼容。
“Excel 也能存储我的数据,我可以使用过滤器检索和处理数据,把它连接到其他文件和工作表,执行 VLOOKUP, PivotTable 等高级函数。那我为什么需要你说的这个花里胡哨的数据库呢?你们这些 IT 人员只是想从我这里榨取钱财(milk money from me,有趣的表达(笑))。没门,我的 Excel 表已经完全够用了!”
如果你曾经担任过小企业的数据库顾问,这话听着是不是很熟悉?乍一看,数据库提供的很多功能似乎可以通过电子表格更容易(而且便宜!)地实现。然而,电子表格有许多限制,这使它不适合管理一些数据:
电子表格一般不能处理多用户访问。如果你在一个使用共享文件的组织中工作,你更有可能遇到恼人的“文件被其他用户锁定”的错误信息。即使特定类型的电子表格有一些多用户功能,它也是相对有限的。另一方面,数据库可以完美地处理多用户访问,甚至是对于同一数据项的读-写和只读的混合访问。
电子表格提供了糟糕的数据验证功能和完整性保证。你很难阻止你的用户完全删除 Excel 文件中的数据。当然,你可以使用工作表密码,但这些密码提供了非常有限的安全水平,而且不能阻止有人删除整个文件。数据库可以提供精细的安全级别,甚至可以保护用户不受自己的人为错误影响。例如,可以轻松设置数据库应用程序,以确保在创建用户时还必须输入 SSN。
查询和报告是电子表格不擅长的一项功能。针对数据集运行查询的能力是非常有用的。当然,电子表格可以通过过滤器和图表提供一些基本的报告,但和它进行比较的可是数据库的 SQL 查询操作,后者可以连接多个表并执行复杂的操作。这就好比将 Fred Flinststone 的车与全新的奔驰 S 级轿车作对比,后者是汽车技术的典范。
处理大型电子表格需要非常多的计算机资源。数据库可以轻松地保存并提供对数百万行数据的访问,组织成数百个表,所有这些都在一台基础服务器上运行,而不需要费一点力气。试着将你的 Excel 文件中的行数增加到数十万行,然后观察计算机的响应时间会发生什么变化。
电子表格更容易创建和维护。数据库在财务支出和人员培训方面都需要更多的投资。然而,这样做的回报是一个更加健壮和安全的数据存储和数据检索系统。当你对以下一个或多个问题回答 "YES" 时,你可能需要从电子表格转到基于数据库的系统了:
- 电子表格中的数据是否需要长期或经常性的使用,而不是一次性工作?
- 是否有很多人需要访问这些数据?
- 你是否需要防止错误的输入?
- 数据是否需要被保护以防止无意中的破坏?
需要更多的说服力吗?好吧,美国政府等权威机构通过 Sarbanes-Oxley 法案的第 404 条规定,所有上市公司必须将关键财务数据的报告从电子表格中移出。
正如我们已经确定的那样,关系型数据库占主导地位的原因是它在管理通用数据方面的简单性、健壮性、灵活性、性能、可扩展性和兼容性。
然而,为了提供所有这些,关系型数据库的内部不得不非常复杂。例如,一个相对简单的 SELECT 语句就可能有数百条潜在的查询执行路径,优化器会在运行时评估这些路径。所有这些对作为用户的我们来说都是隐藏的,但在引擎盖下,RDBMS 通过使用基于成本的算法等东西来确定最能满足要求的“执行计划”。
美国 2000 年代最畅销的轿车是丰田凯美瑞,这不难看出原因。凯美瑞在许多用于评判汽车的类别中都不是最好的,如安全性、油耗、内部空间、可靠性和其他一些类别。然而,它在每个类别中总是接近顶端,使它的综合得分名列前茅。那么,你可能会问,中型家庭轿车与我们讨论的数据库有什么关系?就像凯美瑞一样,关系型数据库在优秀数据库的任何一个品质方面都不出色,也没有真正的闪光点,但是它很好地满足了所有的部分,这足以使它称为默认的首选项。
随着 Web 2.0 的出现,特别是云计算的出现,人们越来越需要具有网络功能的数据库来提供、存储和管理数量惊人的内容。例如 Fackbook 的用户资料和全世界数百万人的帖子;谷歌对其他网站的数十亿次搜索和网络抓取;Dropbox 存储的数百万用户的文档和文件;eBay 数以百万计的拍卖清单,等等。广义上讲,这一领域的流行语是“大数据”(big data)。
对所有这些以网络为中心的数据库,主要的问题是可扩展性。随着越来越多的应用程序在具有大规模工作负载的环境中被推出(想想今天网络上的各种服务),它们的可扩展性要求可能会变化得非常快,而且增长得非常大。关系型数据库的扩展性非常好,但通常只有当扩展发生在单台服务器上时才是这样。当达到单台服务器的容量时,你需要扩展并将负载分配到多台服务器上,进入所谓的分布式计算。这时,关系型数据库的复杂性开始抵消其扩展潜力。尝试扩展到数百或数千台服务器,其复杂性就会变得令人难以承受。RDBMS 的关系型特征在吸引人的同时也大大降低了它们作为大型分布式系统平台的可行性。
为了使云服务可行,供应商必须解决这一限制,因为没有快速可扩展的数据存储的云平台几乎是无用的。因此,为了给客户提供一个可扩展的地方来存储应用数据,供应商不得不实现一种新型的数据库系统,它专注于可扩展性,而牺牲了关系型数据库的其他好处。接下来,我们将更详细地了解这些新的非关系型数据库。
关系型数据库最严重的限制之一是,每个项只能包含一个属性。在我们之前看过的银行例子中,客户与银行关系的每个方面都必须(或者说最好)作为单独的行项存储在不同的表中。客户的主信息在一个表中,账户信息在另一个表中,贷款信息在另外的一个表中,投资又在另一个表中,等等。所有这些表都是通过使用关系、或者叫主键与外键来相互连接的。
非关系型数据库,特别是数据库的键值(key-value)存储或键值对,与这种模式有着本质的区别。键值对允许你在同一张表中的一个“行”的数据中存储几个相关的项。我们把“行”这个词放在引号里,因为这里的行与关系表或电子表格中的行其实不是一回事,尽管为了比较起见,这样称呼它还是很有用的。例如,在同一家银行的非关系表中,每一行都包含客户的详细信息以及他们的账户、贷款和投资细节。所有与一个客户有关的数据都将作为一条记录方便地存储在一起。
这似乎是一种明显优越的数据存储方法。那么,究竟为什么我们还要使用关系型数据库而不是这种模式呢?嗯,键值存储的问题是,与关系型数据库不同,它们不能强制保证数据项之间的 关系 。例如,在我们的键值数据库中,客户的详细资料(姓名、社会保险、地址、账号、贷款处理号码等)都将被存储为一条数据记录(而不是像关系模型那样存储在几个表中)。客户的交易(账户提款、账户存款、贷款偿还、银行收费等)也将被存储为另一个单一的数据记录。
在关系模型中,有一种内置的、万无一失的方法来确保和执行数据库层面的业务逻辑,例如,提款被记入正确的银行账户。在键值存储中,这一责任完全落在了应用逻辑上。许多人对把这一关键责任留给应用程序感到不安,这就是为什么关系型数据库不会很快消失。
然而,当涉及到基于网络的数据库时,严格执行业务规则方面往往被排在优先事项的后面。最重要的是为大量的用户请求提供服务的能力,通常是只读查询。例如,在像举行在线拍卖行 eBay.com 这样的网站上,大多数用户只是浏览和查看发布的物品(只读操作)。只有一小部分用户真正出价或保留物品(读写操作)。请记住,我们谈论的是每天数百万,有时是数十亿的页面浏览量。这样一个网站的所有者对快速响应更感兴趣,这样可以确保为网站的用户更快地加载页面,而不是传统的执行业务规则或确保读和写之间的平衡。你可以对网络上其他大型知名网站进行推断 —— Google、Facebook、Amazon、Twitter 等等。
关系型数据库可以进行调整和设置,以运行大规模的只读操作(通过数据仓库和数据集市),从而有可能为这类用户服务。然而,真正的挑战是关系模型缺乏可扩展性,正如我们前面指出的那样。这就是非关系型模型真正可以发光的地方。它们可以很容易地将数据负载分布在几十个、几百个,在极端情况下(想想谷歌搜索)甚至几千个服务器上。由于每台服务器只处理用户总请求的一小部分,这对每个用户的响应时间非常好。尽管这种分布式计算模式也存在于关系型数据库中,但它的实现是非常痛苦的。这是因为关系模型坚持所有级别的数据完整性,即使数据被几个不同的服务器访问和修改,也必须保持这种完整性。这就是非关系模型成为云计算和社交网络等 Web 2.0 应用的首选架构的原因。
为知名网站提供动力的非关系型数据库的一些例子是亚马逊的 SinpleDB 和谷歌搜索的 BigTable。其他非关系型引擎,无论是开源的还是商业化的,有 CouchDB,Mongo,Drizzle 和名字很怪的 Project Voldemort。(伏地魔)
数据仓库是一种为查询、报告和分析而优化的特殊类型的数据库。仓库中的数据几乎总是只读的,数据通常来自于操作型(operational)数据库和其他系统。然后,它被设置为使用提取、转换和加载(ETL,Extract, Transform and Load)过程定期上传数据至仓库,以将其转化为更适合报告和深入分析的形式。这种转换的具体细节很复杂,所以我们不会在这里深入研究。相对于企业的事务数据库,使用数据仓库进行报告的主要好处是,仓库允许更好和更精细的数据分析用于业务消费。数据仓库的使用也消除了主要交易系统的报告负载,报告对大型组织来说可能会有很大的压力,特别是在季度末或年末报告等时期结束时。此外,数据仓库还保留了所有数据历史的清晰和完整的历史,即使交易系统可能不提供这种能力。
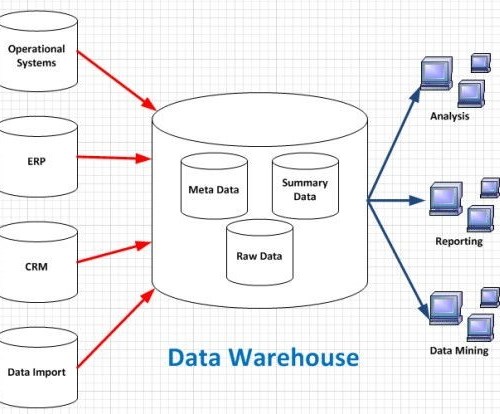
数据仓库的有用性的一个很好的例子是在金融服务行业。银行通常会利用他们的数据仓库能力来进行深入的预测和规划。他们使用模式和趋势分析来回答这样的问题:
什么是最有可能拖欠贷款的客户类型?客户的收入、信贷还款模式和自动取款机提款与他的贷款偿还能力之前是否存在任何关系?一年中向商业农民提供融资的绝对最佳时间是什么?他们通常是在收获季节之前或之后需要金融援助,还是在种植周期的一半?为什么这么多大学生在毕业和找到工作后不在我们这里维持他们的账户?他们从其他银行获得了哪些我们没有提供的功能或好处?
数据仓库在其他行业也很有用,如保险欺诈分析和模式匹配,电信呼叫记录分析,农业天气和气候预测,以及许多其他行业。
数据仓库所提供的分析能力的一个很好的例子是众所周知的一个大型零售店运营商的故事。在分析了他们的数据仓库的数据后,商店经理注意到了一个令人费解的趋势:深夜尿布和婴儿食品的销售也对应着饮料,特别是罐装啤酒的激增。在对这些深夜客户进行了一番研究后,答案终于揭晓。情况是这样的,最近的父母,特别是年轻的父亲,被他们的妻子或女朋友派去为婴儿购买尿布,而这些压力巨大的年轻父亲也决定,当他们在买尿布的时候,他们不妨拿一杯饮料来帮助他们放松。然后,这家零售店精明地将这两类商品放在更近的过道上,以抓住更多的市场,使他们在晚上 9 点以后的酒精饮料销售量增加了三倍。
正如你所看到的,数据仓库有别于典型的数据库,它们被用于更复杂的数据分析。这与事务数据库(transactional database)不同,后者的主要用途是支持操作型系统并提供日常的小规模报告。数据仓库有时还需要与市场研究部和其他部门紧密合作。
我们已经讨论了基本的数据库概念,但这些并不是唯一的概念。还有其他重要的二级概念和数据结构值得学习。在本节中,我们将对这些概念进行简要介绍。
RDBMS 中的索引是一种数据结构,它与表和列紧密配合,以加快数据检索操作的速度。它的作用很像一本书开头的索引。换句话说,它提供了一个参考点,使你能够快速找到并访问你想要的数据,而不必遍历整本书(数据库)。
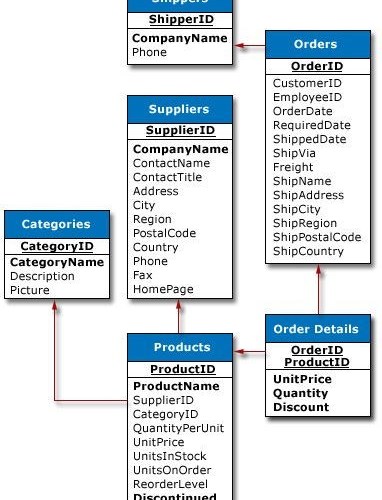
模式是数据组织背后的结构。它是对不同的表之间关系的一个可视化概述。它的作用是描绘和实现创建数据库的基本业务规则。
Oracle 数据库对模式的定义有些不同。在这里,模式指的是一个用户的数据库对象的集合。模式名称和用户名是一样的,但功能却截然不同;也就是说,一个用户可以被删除,而他在数据库中的对象集合(模式)却保持不变,甚至可以被重新分配给另一个用户。
请看下面一个简单的数据库模式的可视化例子:
规范化是对数据库中的数据进行(重新)组织的过程,使其满足两个基本要求:没有数据冗余(所有数据只存储在一个地方),数据的依赖性是符合逻辑的(所有相关的数据项都存储在一起)。例如,对于一个银行的数据库来说,所有客户的静态数据,如姓名、地址和年龄,都应该存储在一起。所有的账户信息,如账户持有人、账户类型、账户分行等,也应该存储在一起;它应该与客户静态数据分开存储。
规范化的重要性有很多原因,但主要是因为它能使数据库尽可能少地占用磁盘空间,从而提高性能。有几种增量规范化类型,它们可能会变得有些复杂。
在 RDBMS 世界中,约束指的是与现实世界中完全相同的东西。约束是对你可以输入到某一列的数据类型的限制。约束总是被定义在列上。一个常见的约束是“非空”约束。它简单地规定,表中的所有行必须在定义为非空的列中有一个值。
考虑一家银行正在建立其数据库系统。想象一下,如果它在电汇过程中崩溃了。大问题,是吧?这就是交易背后的基本理念:一系列变化中所有项目都需要一起进行。在一个简单的转账案例中,如果你借记一个账户,你需要贷记另一个账户。
在关系型数据库中,保存一个事务被称为提交(commit),而撤销任何未保存的改变被称为回滚(rollback)。这是基本的定义,但是当你考虑到数据库通常要同时为几个用户服务时,它就会变得更加复杂。在事务被保存之前,当其他用户查询相同的数据时会发生什么?其他用户在什么时候会看到保存的数据?所有的 RDBMS 都必须能够令人满意地回答这些问题,它们通过提交/回滚功能来做到这一点。
数据库还必须提供容错功能,即使在磁盘故障的情况下。当数据被提交时,必须有一个像金子一样的保证数据确实被保存了。关系型数据库有巧妙的方法来实现这一点,比如两阶段提交和使用日志文件。
这里的 ACID 一词并不是帮助 DBA 们工作得更嗨的迷幻性物质(psychedelic trip-inducing substances,ACID 或 LSD)。相反,它是一个缩写,描述了任何 RDBMS 的四个非常理想的特性:
- 原子性(Atomicity)。数据库完整处理或完整回滚一个事务的能力
- 一致性(Consistency)。数据库必须确保所有写在其中的数据都遵循数据库中指定的所有规则和约束
- 隔离性(Isolation)。事务必须被安全和独立地处理,而不会互相干扰
- 持久性(Durability)。数据库必须确保所有提交的事务被永久保存,即使在数据库崩溃的情况下也不会被意外删除
正如我们之前看到的,数据库允许多个用户同时访问一组数据。因此,一个不可避免的问题是如何处理两个或更多用户想要访问或更新同一份数据的情况。RDBMS 通过使用锁来解决这个问题。
有多种类型的锁,如只是锁定一个数据字段的事务锁或数据级锁、锁定整个数据记录的行级锁,和限制对整个表的访问的表级锁。你可以看到最后一种锁类型的限制性特别强。因此,只有在绝对必要的时候才会采用这种锁,例如在执行全表数据加载或全表备份时。
顺便说一下,电子表格只能使用表级锁。这是它们与数据库相比劣势的一个典型例子。如果你在办公环境中工作,你可能遇到过这样的情况,当你在一个共享的 Excel 电子表格上工作时,你会收到恼人的“文件被另一个用户锁定”信息。锁是实现 RDBMS 的 ACID(原子性,一致性,隔离性,持久性)属性的一种重要方式。
最常见的锁的类型是数据级或事务性锁。它的发生通常对用户来说是完全不可见的。当一个用户更新(但不一定要提交)一个特定的数据项时,它就会被锁定,以防止其他用户对其进行任何其他的修改。然而,其他用户仍然可以读取同一个数据项。这是 RDBMS 的一个巧妙的功能。这时,其他用户只能看到修改前的数据项的“旧”值。一旦主用户提交(保存)了更改,所有现在查询数据的用户将看到新的、更新的值。请记住,“新值”一词甚至可以包括删除原来存在的数据,在这种情况下,该字段现在是空的。如果用户放弃更改并执行回滚,其他用户仍将看到相同的数据,但他们现在也可以更新数据项。
如果一个用户试图改变一个已经被第一个用户锁定的项目,第二个用户会收到一个错误信息,或者系统会挂起一小段时间,等待第一个用户提交(保存)改变或回滚(撤销)。
一种奇怪的情况是,两个用户各自锁定了一个数据项,然后都试图访问并修改另一个用户持有的那个数据项。在这种情况下,有可能无限期地锁定该项目,而每个用户都在等待对方。这被称为死锁,大多数 RDBMS 都有办法检测和解决。系统通常会随机选择一个用户并回滚他的修改,从而释放被该用户锁定的数据并结束死锁。
你可以推测出,就数据库和计算机资源而言,锁定是一项昂贵的活动。托管写密集型数据库的系统需要足够强大,以支持锁定所消耗的资源,特别是 CPU。应用程序也需要精心设计,以便尽可能不频繁地锁定数据。做到这一点的一个方法是在应用程序本身中建立数据保留能力。一旦从数据库中读取一个数据项,应用程序就应该在内部执行所有的修改,而不需要先与数据库进行交互。只有当用户点击“保存”时,应用程序才会迅速将项目写回数据库。这样,从数据库的角度来看,一个数据项处于“已更改”但尚未“提交”或“回滚”的悬而未决的状态的时间最小。
表级锁,正如我们所提到的,是非常有限制性的,因为它们锁定了整个表。虽然它们很少被使用,但在某些操作中是非常有价值的,比如批量上传数据或重组整个表的零散数据时。在这种情况下,确保在操作期间没有其他用户可以访问该表是很方便的,而且一旦操作结束,锁应该立即释放。因此,这些锁通常只由 DBA 在这些特殊操作中使用。表级锁通常需要明确指定;默认情况下,RDBMS 采用行级或事务级锁。
我们现在已经涵盖了关系型数据库的大部分基础知识。它们是最常见的数据库类型,此外也是最重要的软件类型之一,与操作系统、办公效率软件和游戏并列。因此,当听到大型的,成功的 RDBMS 供应商是软件行业的一些巨头,而且不仅在软件界、甚至在主流新闻和文化中也是家喻户晓的名字时,我们就不会感到惊讶。像甲骨文和微软这样的名字无处不在,非常熟悉,甚至对非 IT 人来说也是如此。
许多 RDBMS 供应商也在生产相关和完全不相关的产品。但所有这些厂商的一个共同点是,RDBMS 是他们最关键的产品线之一。他们密切倾听并努力收集来自市场的反馈,这在软件领域并不总是发生。
然而,由于商业战略的原因,他们的许多产品不能很好地与竞争对手的产品或其他软件一起使用。例如,微软的 SQL Server 只适用于 Windows 操作系统,而该系统也是来自微软。有人抱怨说,Oracle DB 与 Windows 操作系统的结合不如与 Linux 的结合好,等等。
业界越来越多的趋势是将 RDBMS 与同一制造商的其他软件进行整合和捆绑,如首选操作系统或其他补充软件,如:
- 额外的数据安全模块,如 Oracle DataGuard
- 与开发平台的整合,如微软的 .NET
- 结合硬件和软件的一体式平台,如 Oracle 的 Exadata 或微软的 Trefis
我们现在将快速浏览一些商业 RDB 产品和它们背后的公司:
Oracle 是 RDBMS 世界的巨无霸之一。该公司由富有魅力、热爱冒险的 CEO Larry Ellison 于 1977 年创立,今天,归功于其旗舰产品 Oracle DB,该公司已成为商业数据库世界中价值数十亿美元的巨人。Oracle 还生产一系列令人困惑的其他产品,从中间件到企业资源规划系统(ERP)和客户关系管理(CRM)产品。其中许多产品不是内部开发的,而是通过收购其他软件公司,如 PeopleSoft、Siebel Systems、Sun Microsystems 和 BEA Systems 而来。这些产品中的一些被整合到了融合中间件(Fusion middleware)产品中,但成功率不高。
Oracle DB 在企业级数据库中被广泛使用。它有不同的版本以满足不同的需求。Oracle DB 完全符合 SQL 语言,尽管它也保持着自己的专有版本,称为 SQL*PLUS。Oracle DB 是领先的 RDBMS,截至 2011 年底,它在 RDBMS 市场上占有 48.8% 的市场份额。
关于 Oracle,值得注意的一点是,在 2009 年,它收购了 Sun Microsystems,即 MySQL 的许可持有者,MySQL 是 Oracle DB 的主要竞争对手之一。因此,Oracle 有两个 RDBMS 产品。然而,Oracle DB 和 MySQL 可能不会相互干扰,因为它们所处的市场空间略有不同,满足的需求也略有不同。
微软是 RDBMS 软件世界中的另一个大块头,它有 SQL Server 产品,尽管它因其通用的 Windows 操作系统和 Office 办公软件套件而更出名。
SQL Server 是在 1989 年左右与 Sybase systems 共同开发的,但这两家公司分道扬镳,分别开发了不同的产品。微软保留了 SQL Server 的名字,而 Sybase 则选择将其产品重新命名为 Adaptive Server Enterprise,以避免与 SQL Server 混淆。该 RDBMS 只在 Windows 系列的操作系统上运行。
SQL Server 使用一种叫做 T-SQL 的专有查询语言,它与标准 SQL 非常相似并兼容。截至 2011 年底,RDBMS 占据了约 20% 的市场份额,但近年来也一直在增加其份额。
SQL Server 和 Oracle DB 有很多共同之处,从数据结构到交易处理方法和数据库对象。与 Oracle DB 一样,SQL Server 也支持高级 ETL(提取、转换、加载)操作,这有助于将数据转移到数据仓库,两者都提供高级报告功能。
Postgres,也被称为 PostgreSQL,是一个开源的关系型数据库,也可以支持数据库对象。它不属于任何一个人,而是由 PostgreSQL 全球开发组维护,这时一个由开源软件开发领域的公司(如 RedHat 和 EnterpriseDB)管理和雇佣的专门志愿者小组。
Postgres 可以在 Linux、Windows 和 MacOS 上使用。
MySQL 是另一个开源的 RDBMS。它是一个由瑞典公司 MySQL AB 赞助的全功能数据库系统,在其母公司 Sun Microsystems 于 2010 年被 Oracle 收购后,现在由 Oracle 所有。
MySQL 在基于网络的后端数据库方面非常流行,可以单独使用,也可以作为 Linux、Apache、MySQL、PHP(LAMP)堆栈的一部分,用于交付以网络为中心的应用程序。
像 SQL Server 和 Oracle DB 一样,IBM 的 DB2 是来自软件行业主要玩家的一个全功能的对象 RDBMS。它最初在 80 年代初专门为 IBM 的大型机开发,后来被移植到其他平台,如 Linux,Unix、Windows(LUW)和 IBM 自己的 OS/2。
它是一个广泛使用的商业 RDBMS,也有一个为开发者提供的小型免费版本,叫做 Express-C。2009 年,IBM 发布了 DB2 的 9.7 版本,它密切模仿了市场领导者 Oracle DB 的功能。这帮助它抓住了一些销售机会,使精通 Oracle 的数据库专业人士很容易理解并开始在 DB2 上工作。
恭喜你!你走完了整个教程。
我们实际上只是接触了一些皮毛知识。毕竟,许多人把整个职业生涯都献给了数据库;有很多东西需要学习!让我们回顾一下这里涉及的内容:
- 数据库,从最普遍的意义上讲,是一个有组织的数据集合。更具体地说,数据库是一个电子系统,它允许数据被轻松访问、操作和更新
- 任何需要跟踪大量客户或产品的企业或组织都可以从数据库中受益,但大型组织的受益最大
- 最早的数据库系统在性质上是导航型的。这意味着应用程序通过嵌入数据本身的指针来处理和读取数据
- 早期的分层和网络数据模型被 E.F. Codd 的关系模型所取代
- 关系模型与统治时期的层次模型截然不同,因为它侧重于按内容搜索数据库的能力,而不是按连接的导航系统
- 有一些非常重要的非关系型数据库(特别是随着大数据和 Web 2.0 的出现),但是关系型模型仍然被用于绝大多数的商业数据库产品中
- 关系型数据库本质上是一组表,或者用技术名称来说,是实体(参考 Codd 十二规则中的第 0 和第 1 条)。每个表都是由行(元组)和列(属性)组成的。这些表之间有关系,这些关系被定义为使用一个表中的某一列来引用另一个表中的某一列。有 13 条规则决定了一个数据库是否可以被称为“关系型”
- 表是关系型数据库中的基本数据存储单元。表由列和行组成
- 关系是关系型数据库运行良好的原因
- 在关系型数据库中,当其中一个表有一个引用另一个表的主键的外键时,两个表之间就存在关系
- 行,也被称作记录,代表了一组关于一个特定项目的数据。一个表中的每条记录都有完全相同的结构,但数据当然是不同的
- 列是同一类型表中的一组特定数值。它定义了表或数据的一个特定属性
- 主键是一个特殊的列或列的组合,它能唯一地识别表中的每条记录(行)。主键列必须对每一行都是唯一的,并且不能包含任何空值
- 主键,连同密切相关的外键概念,是定义关系的主要方式。主键唯一地定义了一条记录,而外键是用来从另一个表中引用相同的记录
- 结构化查询语言(SQL)是用于管理和操作关系型数据库中的数据的事实上的语言。SQL 可以用来查询、插入、更新和修改数据
- 电子表格和数据库有一些类似的功能,但电子表格有一些限制,使其不适合管理一些数据情况
- 关系型数据库最严重的限制之一是,每个项只能包含一个属性。非关系型数据库,特别是数据库的键值存储或键值对,与这种模式有着本质的区别。键值对允许你在同一个表中的一个行的数据中存储几个相关的项目
- 数据仓库是一种特殊类型的数据库,为查询、报告和分析而优化。相对于组织的交易型数据库,使用数据仓库进行报告的主要好处是、仓库可以为业务提供更好、更精细的数据分析
- RDBMS 中的索引是一种数据结构,它与表和列紧密配合,以加快数据检索操作的速度
- 模式是数据组织背后的结构。它是对不同的表之间的关系的一个可视化描述
- 规范化是数据库中(重新)组织数据的过程,以便满足两个基本要求:没有数据冗余(所有数据都只存储在一个地方),数据的依赖关系是合乎逻辑的(所有相关的数据项都存储在一起)
- 在 RDMBS 世界中,约束指的是与现实世界中完全相同的东西。约束是对你可以输入到某一列的数据类型的限制
- 在关系型数据库中,保存一个事务被称为提交,撤销任何未保存的变化被称为回滚
- ACID 是 Atomicity Consistency Isolation Durability 的首字母缩写,是 RDBMS 的四个非常理想的特性
- Oracle 公司是 RDBMS 世界中的巨无霸之一。它的旗舰产品是 Oracle DB
- 微软是 RDBMS 软件世界中的另一个大家伙,它有 SQL Server 产品,尽管它因其通用的 Windows 操作系统和 Office 办公软件套件而更出名
- 其他商业 RDBMS 系统包括 Postgres、MySQL 和 DB2
我是在今年的七月份看到这篇文章的,当时想着能不能把很多大约几兆的图片放入数据库中存储来加快访问速度,读完文章后才发现数据库更适合存储体积很小但数量很多的文本,图片文件编号序号直接访问就行了。现在为了搭建简单的 LAMP 需要学点数据库皮毛知识又把文章看了一遍,觉得非常不错,遂决定翻译一下。
在想到要学习数据库时我的第一反应不是去找本书来读读,而是直接搜索引擎。不知道是不是无意识地就认为书中的内容不够浅显入门,或者说还是认为读书相对于“简单了解”来说太重量级了些。就知识的广度而言,看来我已经默认网络优于书本了。
正如文中所说:“我们实际上只是接触了一些皮毛知识。毕竟,许多人把整个职业生涯都献给了数据库”。除了自己花精力专研的东西,我们了解的大多是事情或知识的表面或皮毛。虽说只是皮毛,但也比完全不了解要好。要我说的话,好的书本应该做到在书的开头以浅显易懂且生动的语言让读者来对书中涉及知识有一个全面而鲜明的认识,随后再在某些地方做重点展开。非专业人士可以通过书本了解事情大概,专业人士可以进行深入的了解。我都看了些什么教材啊(笑)。
这又正好让我想到了学习的深度和广度的问题。也许你听说过什么“在保证深度的同时要兼具广度”的说法,我现在的观点可能是“以广度为优先,深度就随缘吧”。就像我学习数据库不一定需要学会数据库的实现方法,而是直接使用已有数据库,学习数据库的使用方法。作为个体的我的能力实在是太有限了,了解别人的知识,利用别人的成果,再随缘(也许根本就找不到呢)在自己感兴趣的方向深入就行了。
作者毕竟不是中国人,文中的许多例子和梗对我来说并不是很熟悉,比如银行和星际迷航,貌似我已经将近八年没有去电影院正经看过电影了。也许原文中的一些常识过个几十年就成了需要注解才能看懂的历史词汇,不过这就不是翻译文章的我需要关心的了。