我不是什么神经网络和深度学习专家,所以这一部分参考了许多资料,如果有错误欢迎指正。考虑到和人工智能,深度学习和机器学习相关的文章是如此的多,所以这里也没必要写上很多,我会在这一节的结尾给出一些我有所听闻的学习资料。需要说明的是,由于现在复杂的学科关系,我也没法很明确的说某学科属于某学科,只能表示为相关关系而不是属于关系。
我还是希望弄清概念上从大到小的关系的,所以这里我们从机器学习和人工智能开始说起。人工智能(Artificial intelligence)是指人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术[1]。一句话概括的话,人工智能研究怎么让电脑像个人(以及能智工人)(笑)。人工智能这个概念太大了,要落到实处的话需要将这个整体分为不同的部分来单独研究。这里咱们简单描述一下作为智能体的人所具有的“功能”:
- 能通过眼睛,耳朵,皮肤等器官接受外界输入,并处理为能够理解的信息
- 能进行思考,根据信息做决策和规划
- 能通过身体执行决策
- 能够记忆和学习
(所谓“人的本质就是对社会的模仿”,这里我就不列出“能够创造”这一项了(笑))
对应于第一条的子领域包括机器感知、计算机视觉和语音识别。对应于第二条,就是 AI planning。对于第三条就是各种机器人学。至于第四条,知识工程与记忆有关,至于学习就是本文的主题了:机器学习。
机器学习在近 30 多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法涉及了大量的统计学理论,机器学习与推断统计学联系尤其密切,也被称为统计学习理论[2]。机器学习可以分为监督学习、无监督学习和强化学习。
关于机器学习的流派有个很有意思的说法,说机器学习分为五大流派,分别是符号学派(Symbolists),类推学派(Analogizers),进化学派(Evolutionary),联结学派(Connectionists)和贝叶斯学派(Bayesians)。符号主义使用符号、规则和逻辑来表征知识和进行逻辑推理,代表是规则与决策树;类推主义根据约束条件来优化函数,代表是 SVM(支持向量机,support vector machine);进化主义在遗传学和进化生物学的基础上得出结论,生成变化,然后为特定目标选取最优,代表是遗传算法;联结主义使用概率矩阵和加权神经元来动态地识别和归纳模式,代表是神经网络;贝叶斯主义是获取发生的可能性来进行概率推理,代表是马尔科夫链。
本文中使用神经网络那自然就是联结主义了。在机器学习和认知科学领域,人工神经网络(ANN 或 NN)是一类模仿生物神经网络的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,通常是通过一个基于数学统计学类型的学习方法来进行优化[3]。常见的多层前馈网络一般由输入层、输出层和隐藏层三部分组成。其中隐藏层是输入层和输出层之间众多神经元和链接组成的各个层面。它可以有一层或多层,每层的节点(神经元)数目不定。神经元数目越多网络的非线性越显著,从而使神经网络更健壮。
我对深度学习(deep learning)没有太多的了解,只知道它是对传统神经网络的改进。它的“深”强调的是网络层数的多少,相比于传统神经网络可以有很多层(至少大于三层[4],或者说是经过两次传播过程)。理论上三层神经网络可以用来拟合任意的函数,更多的层数不会增强它的拟合能力,但是深度模型相比浅层模型能更好地提取特征,额外的层有助于有效地学习特征。
下面是一些我听说不错的相关学习资料:
BP 网络即反向传播(Back-Propagation)神经网络,是最传统的神经网络,使用了反向传播算法。它利用梯度下降法,通过不断的反向传播来调整网络的权值和偏移,直到网络对输入的响应达到预定的目标范围为止。作为“深度学习之旅”的开端,网上已经有不少介绍推导过程的文章和视频了,比如:
下面的数学推导也或多或少地借鉴了网上的资料,就不一一列出了,反正 \(\LaTeX\) 至少是我写的(笑)。我们从下面的图开始:

假设神经网络共有 \(1\) 层输入层,\(N\) 层隐藏层和 \(1\) 层输出层,共有 \(m_0\) 个输入,输入层神经元个数为 \(m_{0}\),隐藏层各层神经元个数为 \(m_1, m_2, ..., m_N\),输出层神经元个数为 \(m_{N+1}\)。既然总共层数为 \(N+2\),那么层与层之间的权值矩阵共有 \(N+3\) 个(姑且把从输入到输入层和从输出层到输出的变换也算上)。记各层的权值矩阵为 \(W_i( i=0, 1, 2, ... N+2)\) ,偏移向量为 \(\vec{B_i}(i=0, 1, 2, ... N+2)\),那么有:
\[\begin{align*}&W_0 = I_{m_0}, \quad \vec{B_0} = \vec{0_{m_0}} \\& W_{N+2} = I_{m_{N+1}} \quad \vec{B_{N+2}} = \vec{0_{m_{N+1}}}\end{align*}\]
\[W_p = \left(\begin{matrix}w_{11}^{p}&w_{21}^{p}&w_{31}^{p}&\dots&w_{m_{p-1}1}^{p}\\w_{12}^{p}&w_{22}^{p}&w_{32}^{p}&\dots&w_{m_{p-1}2}^{p}\\\vdots&\vdots&\vdots&\cdots&\vdots\\w_{1m_{p}}^{p}&w_{2m_{p}}^{p}&w_{3m_{p}}^{p}&\dots&w_{m_{p-1}m_{p}}^{p}\end{matrix}\right) \vec{B_p} = \left(\begin{matrix}b_1^{p}\\b_2^{p}\\\vdots\\b_{m_{p}}^{p}\end{matrix}\right) p = 1, 2, 3, ... N+1\]
记初始输入为:\(\vec{X} = [x_1, x_2, x_3, \dots, x_{m_0}]^{T}\),那么输入层输入为 \(\vec{X_0} = W_0 \vec{X} + \vec{B_0}\)。输入层输出为 \(\vec{Y_0} = id(\vec{X_0}\)),其中 \(id\) 是恒等函数。从输入到输入层的计算只有形式意义。对之后的层间计算,以此类推有:
\[\left\{\begin{array}{l}\vec{X_p} = W_p \vec{Y_{p-1}} + \vec{B_p} \\\vec{Y_p} = f(\vec{X_p})\end{array}\right.\ p = 1, 2, 3, ... N+1 \]
若将向量 \(\vec{B} \) 放入矩阵 \(W\) 中,再在向量 \(\vec{X}\) 末尾增补一个 \(1\),则可将由上一层输出 \(\vec{Y}\) 到下一层输入 \(\vec{X}\) 的变换直接写为一个矩阵,无需另外再加上向量 \(\vec{B}\),不过这样一来需要修改激活函数的行为,作用于向量时不处理最后一个元素:
\[W^{'}_p = \left(\begin{matrix}w_{11}^{p}&w_{21}^{p}&w_{31}^{p}&\dots&w_{m_{p-1}1}^{p}&b_1^p\\w_{12}^{p}&w_{22}^{p}&w_{32}^{p}&\dots&w_{m_{p-1}2}^{p}&b_2^p\\\vdots&\vdots&\vdots&\cdots&\vdots&\vdots\\ w_{1m_{p}}^{p}&w_{2m_{p}}^{p}&w_{3m_{p}}^{p}&\dots&w_{m_{p-1}m_{p}}^{p}&b_{m_p}^p\\0&0&0&\dots&0&1\end{matrix}\right) X_p^{'} = \left(\begin{matrix}x_1^{p}\\x_2^{p}\\\vdots\\x_{m_{p}}^{p}\\1\end{matrix}\right) p = 0, 1, 2, 3, ... N+2\]
\[\left\{\begin{array}{l}\vec{X_p^{'}} = W_p^{'} \vec{Y_{p-1}^{'}}\\\vec{Y_p^{'}} = g(\vec{X_p^{'}})\end{array}\right.\ p = 1, 2, 3, ... N+1 \]
\[g([x_1, x_2, x_3, ... x_n, 1]^T) = [f(x_1), f(x_2), f(x_3), ... f(x_n), 1]^T\]
\[g^{'}([x_1, x_2, x_3, ... x_n, 1]^T) = [f^{'}(x_1), f^{'}(x_2), f^{'}(x_3), ... f^{'}(x_n), 0]^T\]
(注意,这里的 \(f^{'}\) 表示 \(f\) 的导数,下面也是。使用的 \('\) 符号不小心和求导冲突了(笑))
从输入开始,经过不断的矩阵变换和非线性的激活函数映射,我们可以一层一层地从前向后传播,直到获得输出层的 \(\vec{Y^{'}}\) 向量为止,也就是 \(\vec{Y^{'}} = \vec{Y^{'}_{N+2}} = id(W^{'}_{N+2}g(W^{'}_{N+1}g(W^{'}_{N}...g(W^{'}_1id(W^{'}_0\vec{X^{'}})))))\)。化简一下可以写成:
\[\vec{Y^{'}} = g(W^{'}_{N+1}g(W^{'}_{N}...g(W^{'}_1\vec{X^{'}})))\]
此处,我们将单个样本经前向传播后获得的向量的 损失函数 (loss function)取为:
\[e = \frac12|| \vec{Y} - \vec{Y_{t}}||^2 = \frac{1}{2}\sum_{i=1}^{N}(y_i - y_i^t)^{2} \]
其中 \(\vec{Y}\) 为样本输出向量,\(\vec{Y_t}\) 为样本的标准输出向量。对于由 \(M\) 个样本经过前向传播得到的 \(M\) 个输出向量,我们取 代价函数 (cost function)为:
\[E = \frac{1}{M}\sum_{i=1}^{M}e_i = \frac{1}{2M}\sum_{i=1}^{M}|| \vec{Y^i} - \vec{Y_t^{i}}||^2\]
代价函数 \(E\) 是神经网络中所有权重偏差和神经网络输入向量的函数,可以写成:
\[E = E(W^{'}_{N+2}, W^{'}_{N+1}, W^{'}_{N}, W^{'}_{N-1}... W^{'}_{1}, W^{'}_0, \vec{X_M}, \vec{X_{M-1}}, ... \vec{X_1})\]
使用反向传播和梯度下降法,我们可以通过训练迭代修改神经网络中的权重和偏移值,并在最后通过训练好的神经网络来获得我们想要的输出结果。例如下面分别对输出层的 \(w_{11}\),\(w_{21}\) 和 \(b_1\),\(b_2\) 求对 \(E\) 的导数:
\[\left\{\begin{array}{l}\frac{\partial E}{\partial w_{11}^{N+1}} = \frac{\partial E}{\partial x_1^{N+1}}\frac{\partial x_1^{N+1}}{\partial w_{11}^{N+1}}=\frac{\partial E}{\partial x_1^{N+1}}y_1^{N}\\ \frac{\partial E}{\partial w_{21}^{N+1}} = \frac{\partial E}{\partial x_1^{N+1}}\frac{\partial x_1^{N+1}}{\partial w_{21}^{N+1}}=\frac{\partial E}{\partial x_1^{N+1}}y_2^{N}\end{array}\right. \quad \ \left\{\begin{array}{l}\frac{\partial E}{\partial b_{1}^{N+1}} = \frac{\partial E}{\partial x_{1}^{N+1}}\frac{\partial x_1^{N+1}}{\partial b_{1}^{N+1}}=\frac{\partial E}{\partial x_{1}^{N+1}}\cdot1\\ \frac{\partial E}{\partial b_{2}^{N+1}} = \frac{\partial E}{\partial x_{2}^{N+1}}\frac{\partial x_2^{N+1}}{\partial b_{2}^{N+1}}=\frac{\partial E}{\partial x_{2}^{N+1}}\cdot1\end{array}\right.\]
稍加观察,我们可以得到 \(E\) 对整个权值偏差矩阵的导数组成的矩阵:
\[\frac{\partial E}{\partial W^{'}_{N+1}} = \vec{\delta^{'}_{N+1}} \cdot \vec{Y^{'}_{N}}^T \]
其中:
\[\begin{align*}\vec{\delta^{'}_{N+1}} &= \frac{\partial E}{\partial \vec{X^{'}_{N+1}}} = [\frac{\partial E}{\partial {x_1^{N+1}}}, \frac{\partial E}{\partial {x_2^{N+1}}}, \frac{\partial E}{\partial {x_3^{N+1}}}, ..., \frac{\partial E}{\partial x_{m_{N+1}}^{N+1}}, 0]^T \\\vec{Y^{'}_{N}} &= [y_1^{N}, y_2^{N}, y_3^{N}, ... y_{m_{N}}^{N}, 1]^T\end{align*}\]
因此,对于每一个权值矩阵,我们都有:
\[\begin{align*}\vec{\delta^{'}{p}} &= \frac{\partial E}{\partial \vec{X^{'}_{p}}} = [\frac{\partial E}{\partial {x_1^{p}}}, \frac{\partial E}{\partial {x_2^{p}}}, ..., \frac{\partial E}{\partial x_{m_{p}}^{p}}, 0]^T \\\frac{\partial E}{\partial W^{'}_{p}} &= \vec{\delta^{'}_{p}} \cdot \vec{Y^{'}_{p-1}}^T\end{align*} \quad p=1, 2, 3, ..., N+1\]
根据网络从前往后一层层传播的特性,我们可以推导出前一层的误差项向量与后一层的误差项向量的关系,以第 \(N\) 个权值矩阵的误差项向量为例:

\[\begin{align*}\frac{\partial E}{\partial w_{11}^{N}} &=\frac{\partial E}{\partial x_1^{N+1}}\frac{\partial x_1^{N+1}}{\partial y_1^{N}}\frac{\partial y_1^{N}}{\partial x_1^{N}}\frac{\partial x_1^{N}}{\partial w_{11}^{N}} + \frac{\partial E}{\partial x_2^{N+1}}\frac{\partial x_2^{N+1}}{\partial y_1^{N}}\frac{\partial y_1^{N}}{\partial x_1^{N}}\frac{\partial x_1^{N}}{\partial w_{11}^{N}} + ... + \frac{\partial E}{\partial x_{m_{N+1}}^{N+1}}\frac{\partial x_{m_{N+1}}^{N+1}}{\partial y_1^{N}}\frac{\partial y_1^{N}}{\partial x_1^{N}}\frac{\partial x_1^{N}}{\partial w_{11}^{N}}\\&=\frac{\partial y_1^{N}}{\partial x_1^{N}}y_1^{N-1} \sum_{i=1}^{m_{N+1}}\frac{\partial E}{\partial x_i^{N+1}}\frac{\partial x_i^{N+1}}{\partial y_1^{N}}\\&=\frac{\partial y_1^{N}}{\partial x_1^{N}}y_1^{N-1} [w_{11}^{N+1}, w_{12}^{N+1}, ..., w_{1m_{N+1}}^{N+1}, 0] \cdot \vec{\delta^{'}_{N+1}}\end{align*}\]
(注意上面公式最后一行的 \(w\) 向量中有一项 \(0\),它只是为了表示我们所用的矩阵是 \(W^{'}\) 而不是 \(W\) 的第一列。)
与之类似,对 \(w_{21}^{N}\),\(b_1^{N}\) 和 \(w_{12}^{N}\) 有:
\[\begin{align*}\frac{\partial E}{\partial w_{21}^{N}} =& \frac{\partial y_1^{N}}{\partial x_1^{N}}y_2^{N-1} [w_{11}^{N+1}, w_{12}^{N+1}, ..., w_{1m_{N+1}}^{N+1}, 0] \cdot \vec{\delta^{'}_{N+1}}\\\frac{\partial E}{\partial b_1^{N}} =& \frac{\partial y_1^{N}}{\partial x_1^{N}} \cdot 1 \cdot [w_{11}^{N+1}, w_{12}^{N+1}, ..., w_{1m_{N+1}}^{N+1}, 0] \cdot \vec{\delta^{'}_{N+1}}\\\frac{\partial E}{\partial w_{12}^{N}} =& \frac{\partial y_2^{N}}{\partial x_2^{N}}y_1^{N-1} [w_{21}^{N+1}, w_{22}^{N+1}, ..., w_{2m_{N+1}}^{N+1}, 0] \cdot \vec{\delta^{'}_{N+1}} \end{align*}\]
以此类推,有:
\[\frac{\partial E}{\partial W^{'}_{N}} = D^{'}_N W^{'^T}_{N+1}\vec{\delta^{'}_{N+1}} \vec{Y^{'}_{N-1}}^T \quad D^{'}_N = \left(\begin{matrix}f^{'}(x_1^{N})&0&0&\cdots&0&0\\0&f^{'}(x_2^{N})&0&\cdots&0&0\\0&0&f^{'}(x_3^{N})&\cdots&0&0\\\vdots&\vdots&\vdots&\vdots&\vdots&\vdots\\0&0&0&\cdots&f^{'}(x_{m_{N}}^N)&0\\0&0&0&\cdots&0&0\end{matrix}\right) \]

由此,我们可以得到每一层的权重矩阵所对应的误差项向量和梯度矩阵:
\[\left\{\begin{align*}\vec{\delta^{'}{p}} &= \frac{\partial E}{\partial \vec{X^{'}_{p}}} = D^{'}_pW_{p+1}^{'^T}\vec{\delta^{'}_{p+1}}\\ \frac{\partial E}{\partial W^{'}_{p}} &= \vec{\delta^{'}_{p}} \cdot \vec{Y^{'}_{p-1}}^T\end{align*}\right. \quad D^{'}_p = \left(\begin{matrix}f^{'}(x_1^{p})&0&\cdots&0&0\\0&f^{'}(x_2^{p})&\cdots&0&0\\\vdots&\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&f^{'}(x_{m_{p}}^p)&0\\0&0&\cdots&0&0\end{matrix}\right)\quad p=1, 2, 3, ..., N\]
对于 \(p = 0\),由于 \(W_{0}^{'}\) 是单位矩阵不会变化,故 \(\vec{\delta_{0}} = \vec{0_{m_0}}\)。对 \(p = N+1\),也就是求第 \(N+1\) 个权值矩阵的误差项向量和梯度矩阵,由于没有 \(N+2\) 的误差项向量了(因为 \(W_{N+2}^{'}\) 是单位矩阵,不会改变),所以只能单独求取,若我们直接指定 \(\delta^{'}_{N+2}\) 的话,还是可以继续套用公式:
\[\begin{align*}\vec{\delta^{'}_{N+1}} &= D^{'}_{N+1}W^{'^T}_{N+2} \vec{\delta{'}_{N+2}} = D^{'}_{N+1}\vec{\delta{'}_{N+2}} \\\vec{\delta^{'}_{N+2}} &= \frac{\partial E}{\partial \vec{Y^{'}}} = [\frac{\partial E}{\partial y_1^{N+1}}, \frac{\partial E}{\partial y_2^{N+1}}, \cdots, \frac{\partial E}{\partial y_{m_{N+1}}^{N+1}}, 0]^T\end{align*}\]
在递推求出所有的 \(\vec{\delta^{'}}\) 向量后,我们就可以将它们分别乘上对应的输出向量来得到各权值矩阵的梯度矩阵了。上面我们只是求得了一个样本的梯度,我们需要将这些梯度加起来,这样得到的梯度才能反映所有样本的情况:
\[\frac{\partial E}{W^{'}_p} = \sum_{i=1}^{M}\frac{\partial E(\vec{X_i})}{\partial W^{'}_{p}} \]
至此,我们就完成了 BP 网络的前向传播和反向传播的推导。随后在训练过程中根据公式 \(W^{'}_p(new) = W^{'}_p(old) - \eta \frac{\partial E}{\partial W^{'}_p}\) 更新权值偏移到收敛即可,其中的 \(\eta\) 即学习率。收敛与否可以通过误差函数是否非常接近 \(0\) 来判断。下面让我们拆除使用的 \('\) 脚手架,重新写出 BP 网络的前向传播和反向传播公式:
\[\vec{X} = [x_1, x_2, x_3, ...x_{m_0}]^T\]
\[\begin{align*}&W_0 = I_{m_0} \quad \vec{B_0} = \vec{0_{m_0}} \\& W_{N+2} = I_{m_{N+1}} \quad \vec{B_{N+2}} = \vec{0_{m_{N+1}}}\end{align*}\]
\[W_p = \left(\begin{matrix}w_{11}^{p}&w_{21}^{p}&w_{31}^{p}&\dots&w_{m_{p-1}1}^{p}\\w_{12}^{p}&w_{22}^{p}&w_{32}^{p}&\dots&w_{m_{p-1}2}^{p}\\\vdots&\vdots&\vdots&\cdots&\vdots\\w_{1m_{p}}^{p}&w_{2m_{p}}^{p}&w_{3m_{p}}^{p}&\dots&w_{m_{p-1}m_{p}}^{p}\end{matrix}\right) \vec{B_p} = \left(\begin{matrix}b_1^{p}\\b_2^{p}\\\vdots\\b_{m_{p}}^{p}\end{matrix}\right) p = 1, 2, 3, ... N+1\]
\[\left\{\begin{array}{l}\vec{X_p} = W_p \vec{Y_{p-1}} + \vec{B_p} \\\vec{Y_p} = f(\vec{X_p})\end{array}\right.\ p = 1, 2, 3, ... N+1 \]
前向传播的计算:
\[\vec{Y} = f(W_{N+1}f(W_{N}...f(W_2f(W_1\vec{X} + \vec{B_1}) + \vec{B_2}) + ... + \vec{B_N}) + \vec{B_{N+1}})\]
接着是反向传播:
\[\left\{\begin{align*}\vec{\delta{p}} &= \frac{\partial E}{\partial \vec{X_{p}}} = [\frac{\partial E}{\partial {x_1^{p}}}, \frac{\partial E}{\partial {x_2^{p}}}, ..., \frac{\partial E}{\partial x_{m_{p}}^{p}}]^T \\\frac{\partial E}{\partial W_{p}} &= \vec{\delta_{p}} \cdot \vec{Y_{p-1}}^T \\ \frac{\partial E}{\partial \vec{B_p}} &= \vec{\delta_p}\end{align*}\right. \quad p=1, 2, 3, ..., N+1\]
根据所有样本的反向传播获取梯度平均值:
\[\begin{align*}\frac{\partial E}{\partial W_{p}} &= \sum_{i=1}^{M}\frac{\partial E(\vec{X_i})}{\partial W_{p}} \\ \frac{\partial E}{\partial \vec{B_p}} &= \sum_{i=1}^{M}\frac{\partial E(\vec{X_i})}{\partial \vec{B_{p}}}\end{align*}\]
相邻两层间的误差项向量的关系:
\[\vec{\delta_{p}} = \frac{\partial E}{\partial \vec{X_{p}}} = D_pW_{p+1}^{^T}\vec{\delta_{p+1}} \quad D_p = \left(\begin{matrix}f^{'}(x_1^{p})&0&\cdots&0\\0&f^{'}(x_2^{p})&\cdots&0\\\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&f^{'}(x_{m_{p}}^p)\end{matrix}\right)\quad p=1, 2, 3, ..., N+1\]
根据误差函数公式:
\[E = \frac{1}{M}\sum_{i=1}^{M}e_i = \frac{1}{2M}\sum_{i=1}^{M}|| \vec{Y^i} - \vec{Y_t^{i}}||^2\]
我们可知:
\[\vec{\delta_{N+2}} = \frac{\partial E}{\partial \vec{Y}} = \frac{1}{M} (\vec{Y} - \vec{Y_t})\]
最后,根据公式
\[W_p(new) = W_p(old) - \eta \frac{\partial E}{\partial W_p(old)} \quad \vec{B_p}(new) = \vec{B_p}(old) - \eta \frac{\partial E}{\partial \vec{B_p}(old)}\]
我们可以对权值矩阵和偏移向量进行迭代,来逐渐减小误差函数 \(E\) 的值,直到最后趋近于 \(0\)。
为了文章的自洽性,这里还是补充一些神经网络的相关知识,我会给出一些我觉得不错的文章来作为补充。
上面我们使用了各种矩阵来表达了前向传播和后向传播的过程,其中的一些求导公式是纯纯地通过观察找出来的,你可能会好奇有没有一种直接的方法来对向量或者矩阵进行求导呢?那还真是有的。可以以“矩阵求导”或“张量求导”为关键字进行搜索,这里我就不作过多叙述了。使用这些求导运算可以让上面的推导更加方便,可惜我在推导的时候还没有学过(笑)。
由于我没有学习过矩阵分析相关的知识,所以上面一些符号使用的可能并不怎么规范,如果你在阅读过程中有违和感欢迎告诉我,我找时间学矩阵分析后修改一下。
这里给出几篇讲矩阵求导的介绍性文章:
在上面的推导过程中我们没有提到任何具体的激活函数,这里做点补充,介绍一些常见的激活函数,并给出它们的图像。不过在开始之前我们简单地说下神经网络为什么需要激活函数。
如果没有激活函数的话,那么整个网络计算过程就是线性的,那整个模型就是一个线性模型了。非线性的激活函数能够增加非线性的变换到输入中,将非线性引入了网络中。
在上面的数学推导过程中,我们在每一层都使用了同样的激活函数 \(f\),实际上网络中的每一层都可以使用不同的激活函数,不过好像一般不这么干,只区分隐藏层中的激活函数和输出层的激活函数。
这应该是大多数学习神经网络的同学见到的第一个激活函数,它和它的导函数分别是:
\[\begin{align*}y &= sigmoid(x) = \frac{1}{1 + e^{-x}} \\ y^{'} &= \frac{e^{-x}}{(1 + e^{-x})^2} = y(1-y)\end{align*}\]
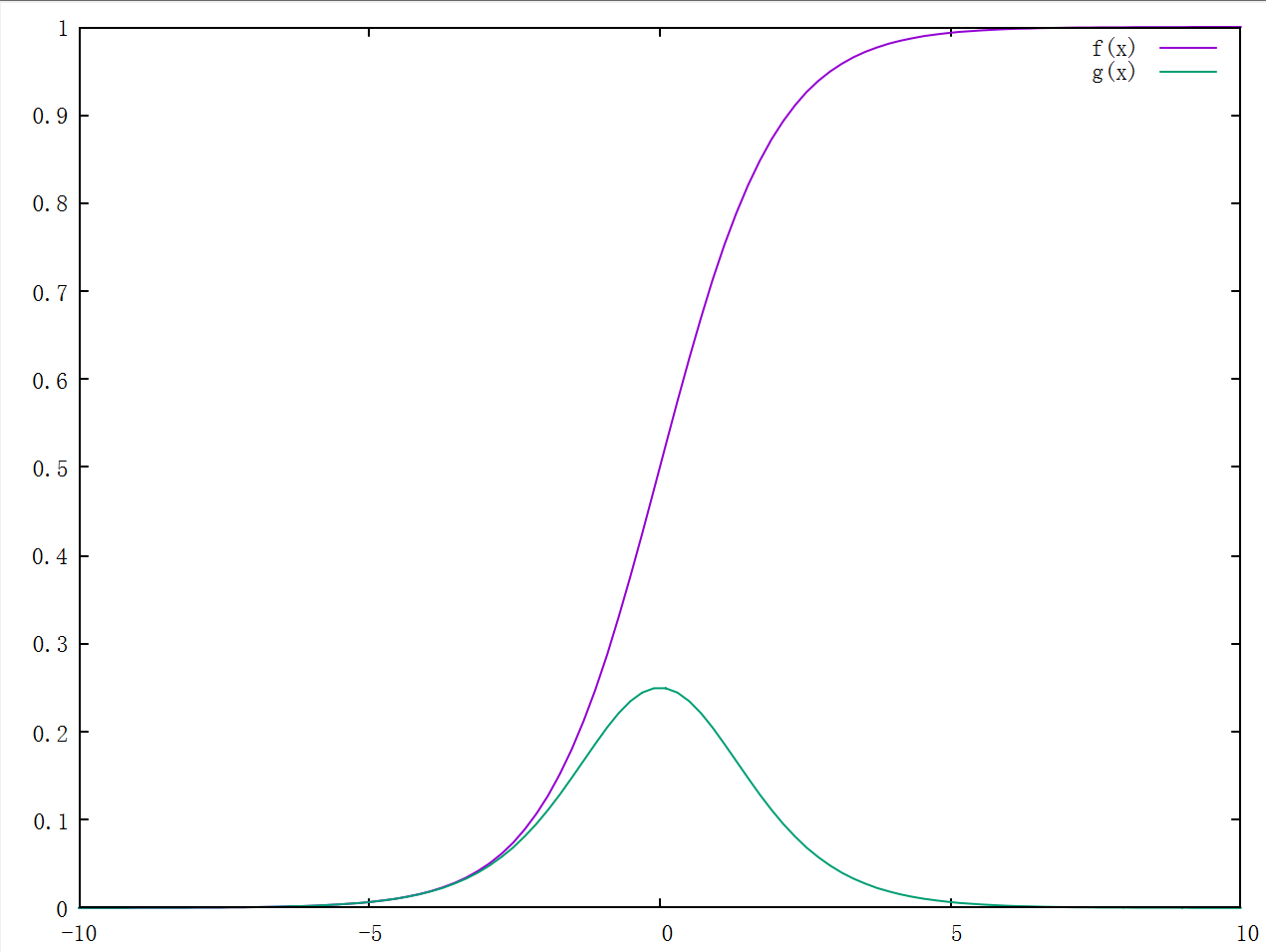
它具有如下特点:
- 左右两侧近似饱和,如果输入过正或过负会导致梯度消失
- 输出不以 0 为中心,会降低权重更新的效率
- 涉及指数运算,运算速度较慢
\[\begin{align*}y &= tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} = \frac{2}{1 + e^{-2x}} - 1\\ y^{'} &= \frac{4}{(e^{x} + e^{-x})^2} = 1 - y^{2}\end{align*}\]
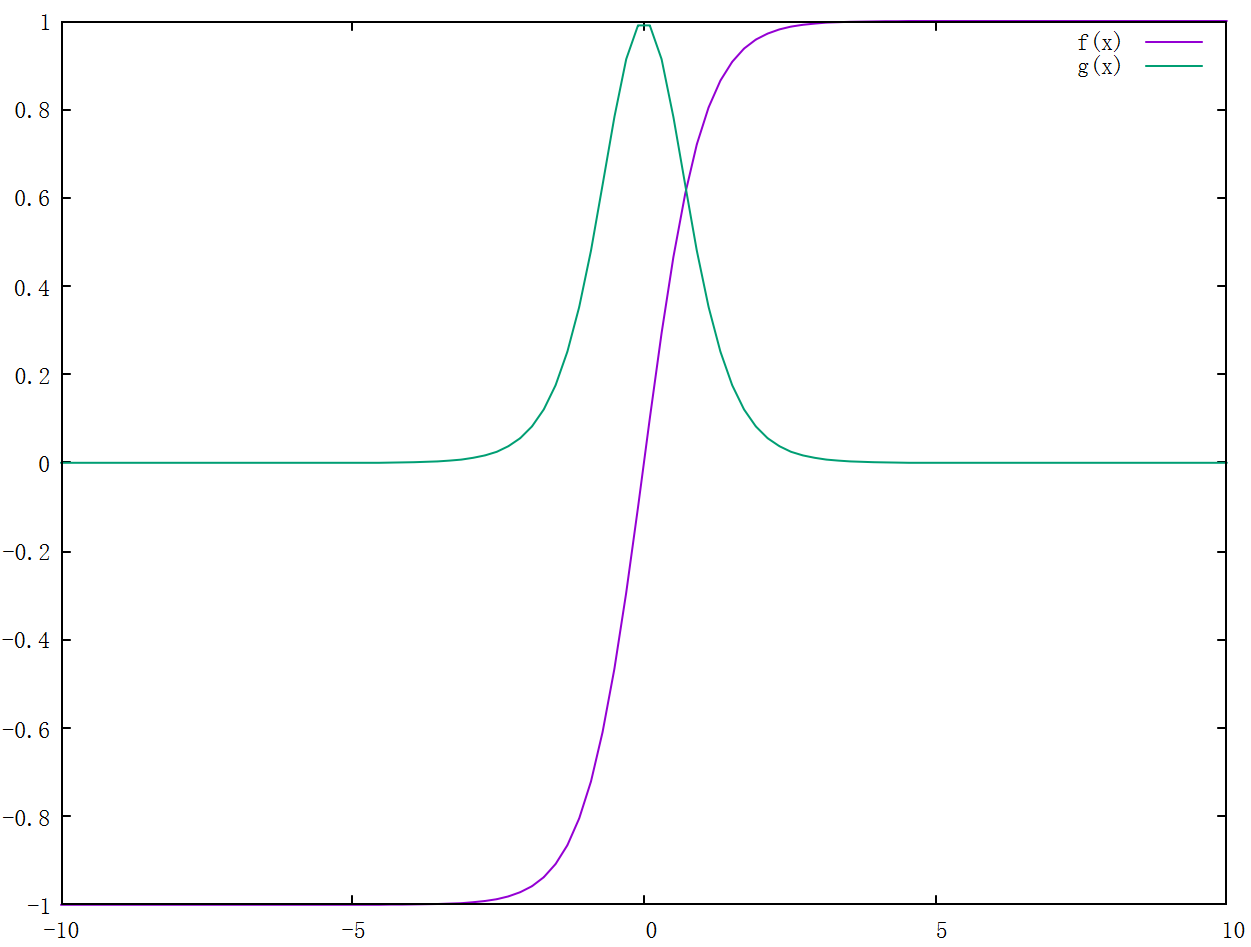
- 相比 \(sigmoid\),输出以 0 为中心,不存在梯度恒正或恒负的情况
- 相比 \(sigmoid\),在 0 附近的斜率更大,收敛速度更快
- 类似 \(sigmoid\),会存在梯度消失问题,而且比 \(sigmoid\) 更显著
Relu 即整流线性函数(Rectified Linear Unit),或称修正线性单元。在 \(x > 0\) 区域上不会出现梯度饱和和梯度消失的问题。相比于 \(sigmoid\) 或 \(tanh\) 没有指数运算,计算简单。
\[\begin{align*} y &= ReLU(x) = x > 0 \ ? \ x : 0\\ y^{'} &= x > 0 \ ? \ 1 : 0\end{align*}\]
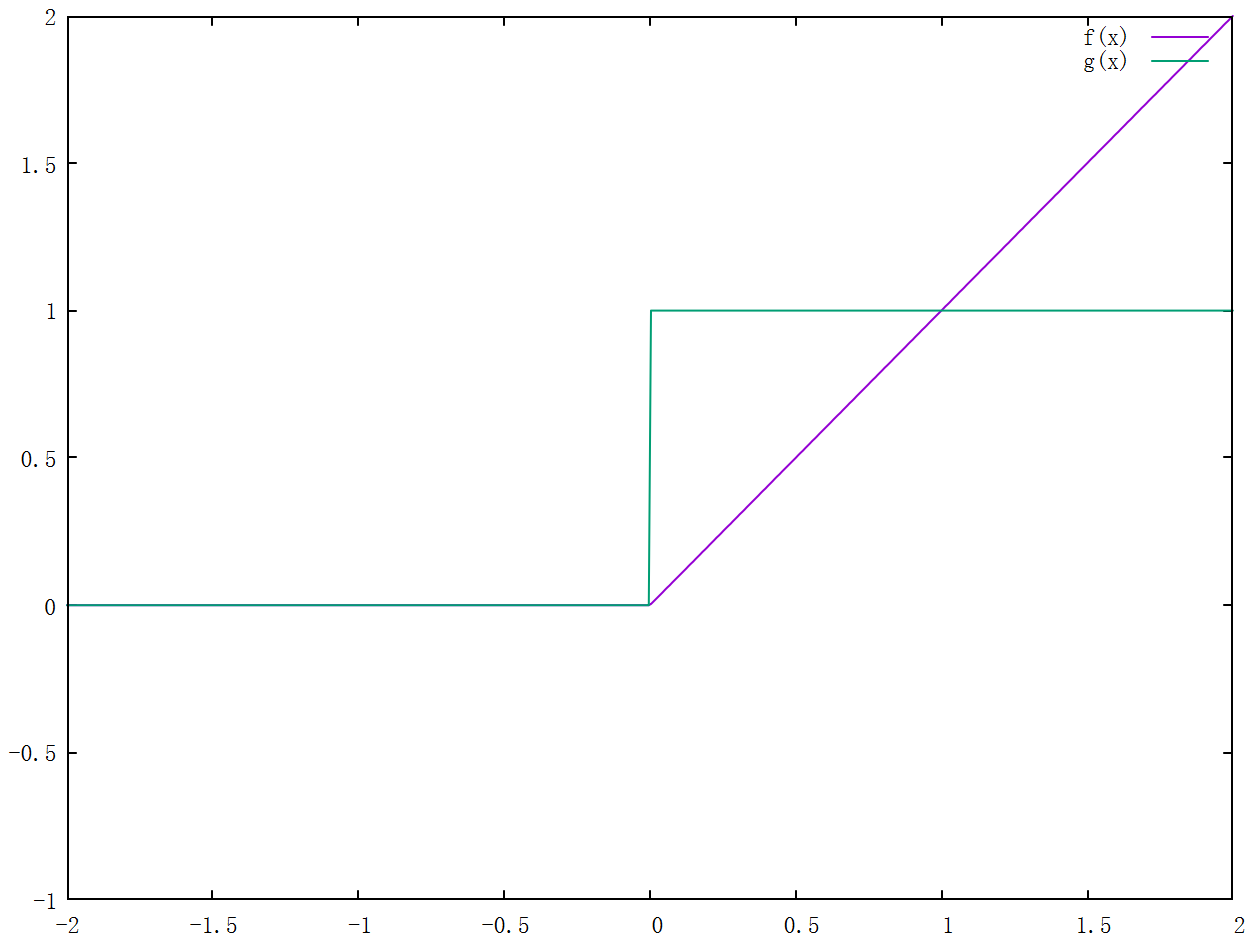
- \(Relu\) 的输出非 \(0\) 对称,可能出现梯度恒正或恒负,影响训练速度
- 当 \(x \lt 0\) 时,\(Relu\) 输出恒为 \(0\),反向传播时梯度恒为 \(0\),形成“死神经元”
softmax 函数比较适合作为多分类模型的激活函数,一般会和 交叉熵损失函数 搭配使用,在从隐藏层到输出层时使用 \(softmax\)。这是一个向量函数,接受一个向量。多元函数我做不出来图,不过如果其他项非常小,那么该函数关于某一项的函数图像和 \(sigmoid\) 非常像。
\[\begin{align*}\vec{Y} &= softmax(\vec{X}) \\ y_i &= \frac{e^{x_i}}{\sum_{j=1}^{n}e^{x_j}}\end{align*}\]
可以看到,它将向量中的各值映射到 \((0, 1)\) 区间,并使它们的和为 \(1\),这可以理解为对应每个类别的预测概率。如果向量中某一项大于其他项,那么它的映射值会非常接近 \(1\),其他值非常接近 \(0\)。
该函数具有以下特点:
- 使用了指数函数,容易将输出拉开距离,但也因为使用了指数函数计算量较大
- 当输入非常大时,指数运算可能会溢出
在本文的最后一节介绍手写数字分类时,我会对它和交叉熵的关系进行详细的说明。
上面我只简单介绍了 4 种激活函数,实际上本文中只会使用两种,即 \(sigmoid\) 和 \(softmax\)。神经网络的激活函数当然远不止这几种,光是 \(ReLU\) 的变种就有一大堆。在这一小节的最后我们拉个清单列举一下:
- sigmoid 相关:hard-sigmoid
- tanh 相关:hard-tanh
- ReLU 相关:leaky ReLU,GeLU,ELU,PReLU,ReLU6,SELU,CELU
现在貌似损失(Loss)函数和代价(Cost)函数在名词使用上没有太大区别了,这里我们还是简单说说它们的关系,顺便提一下目标(Objective)函数,然后介绍一些常见的损失函数。
关于这三种函数的区别和关系,有人认为损失函数等同于代价函数[5],实际上应该也没差,不过我比较喜欢这个回答:
- 损失函数 用来度量拟合的程度,估量模型的预测值和真实值的不一致程度,通常使用 \(L(Y, f(x))\) 表示, 针对单个训练样本
- 代价函数 和损失函数的不同之处在于,它是所有样本误差的平均,也就是所有样本损失函数的平均, 针对整个训练集
- 目标函数 是最优化中的概念,表示任意希望被优化的函数
A loss function is a part of a cost function which is a type of an objective function.
需要说明的是,除了交叉熵之外,下面的公式都是对标量的,但神经网络的输出并不一定是一个标量,它也可以是一个向量,对一个向量我们要怎样获得一个标量损失函数的损失值呢?那可能是是求 L1 损失的时候用 L1 范数,求 L2 损失的时候用 L2 范数了,但我也不确定这是否正确。很明显,输出标量我们就应该用标量的损失函数,输出向量我们就应该用向量的损失函数,对向量用标量函数纯纯吃饱了撑的。上一节的数学推导处我只是简单地使用 \(||\vec{Y} - \vec{Y_t}||^2\) 来表示对两个向量“作差”,这作为损失函数当然没问题,但是我不太清楚它算不算得上向量版的 L2 损失函数。
0-1 损失指预测值与真实值是否相等,相等为 0,否则为 1:
\[L(Y, f(x)) = \left\{\begin{align*}&1 \quad Y \neq f(x) \\&0 \quad Y = f(x)\end{align*}\right.\]
计算目标值与预测值之间的差的绝对值,也叫 \(L1\) 损失:
\[L_1(Y, f(x)) = |Y - f(x)| \\ \frac{\mathrm{d}L_1(x)}{\mathrm{d}x} = \left\{\begin{align*}&1 \quad x > 0 \\&-1 \quad otherwise\end{align*}\right.\]
与它对应的代价函数是平均绝对误差(MAE):
\[MAE = \frac{\sum_{i=1}^{n}|y_i - y_i^p|}{n}\]
其中,\(y_i\) 表示计算预测值,\(y_i^p\) 表示对应的目标值。MAE 是目标值与预测值之差的绝对值的均值,表示了预测值的平均误差幅度。
计算目标值与预测值之间差的绝对值的平方,也叫 \(L2\) 损失:
\[\begin{align*}L_2(Y, f(x)) &= |Y - f(x)|^2\\ \frac{\mathrm{d}L_2(x)}{\mathrm{d}x} &= 2(f(x) - Y)\end{align*}\]
与它对应的代价函数是均方误差(MSE):
\[MSE = \frac{\sum_{i=1}^{n}(y_i - y_i^p)^2}{n}\]
MSE 是预测值与目标值差值的平方和的平均,是最常用的损失函数。有时会在公式前面乘上常数项 \(\frac12\),这是为了方便求导的时候约掉系数。
关于交叉熵网上也有许多非常不错的教程,这里简单列举几篇然后再开始我们的讲解:
交叉熵的计算公式为:
\[H(Y, f(X)) = -\sum_{i=1}^{m}y_iln(f(x_i))\]
其中,\(m\) 为标签的数量。
使用交叉熵损失函数的代价函数是:
\[C = -\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{m}y_jln(f(x_j))\]
其中 \(n\) 为样本数量。
我们会在本文的最后一节推导和使用交叉熵。
梯度消失(vanishing gradient problem)是指在网络很深的情况下反向传播时梯度呈指数减少,导数逐渐缩减为 0,导致权值不更新,网络无法优化。梯度爆炸(exploding gradient problem)和梯度消失相反,反向传播时梯度呈指数增长,会导致梯度非常大,使网络不稳定。
关于梯度消失和梯度爆炸我并不是非常熟悉,所以没法比较详细地分析出现的原因,这里同样丢几篇文章完事:
这三个英文分别是批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-Batch Gradient Descent)的缩写,如果使用汉字的话稍微长了些,所以这里就用英文缩写当标题了。
我们在上一节的推导中使用的就是批量梯度下降,在一轮训练中,取所有样本的梯度的平均值来作为梯度。除了这种方法,我们也可以在一轮训练中随机选择一个样本来更新权重,这就是随机梯度下降法。如果说前者是:
\[W^{'}_p(new) = W^{'}_p(old) - \eta \frac{1}{M}\sum_{i=1}^{M}\frac{\partial E(\vec{X_i})}{\partial W^{'}_{p}(old)}\]
while (epoch > 0) {
let grad_sum = 0.0
for (int i = 0; i < M; i++) {
grad_sum = grad_sum + dLoss(x[i], y[i])
}
current_grad = current_grad - eta * grad_sum / M
epoch = epoch - 1
}那么后者就是:
\[W^{'}_p(new) = W^{'}_p(old) - \eta \frac{\partial E(\vec{X_{r(1, M)}})}{\partial W^{'}_{p}(old)}\]
while (epoch > 0) {
shuffle(x, y)
for (int i = 0; i < M; i++) {
if (epoch == 0)
break
current_grad = current_grad - eta * dLoss(x[i], y[i])
epoch = epoch - 1
}
}(注意,这里我们在每一大轮(也就是遍历所有样本)开始之前先进行了打乱(shuffle)操作,然后再依次使用打乱后的全体样本来更新梯度。我这里没有使用在每一轮中调用随机函数获取样本的方法,我不知道这样行不行,不过我在网上好像没看到这样做的,这里还是随大流吧(笑)。)
BGD 确定的梯度能更好地代表样本总体,从而更准确地向极值所在方向移动,而且它对各样本的计算是个并行的过程,可以使用向量化计算。但它的缺点是样本数量大会导致训练缓慢。SGD 由于每次训练只使用一个样本而不是全部样本,训练速度大大加快,由于随机选择引入了噪声,提高了泛化误差。缺点是单个样本不能代表全体样本的趋势,不收敛。SGD 的一个比较形象的说法是醉鬼下山法。
小批量梯度下降介于 BGD 和 SGD 之间,它不使用全部训练样本,也不只使用一个样本,而是在每一轮训练中随机选取一个合适大小的样本子集,再在这个子集上使用 BGD 进行训练。这也就是它名字中“小批量”的来源。相比于 BGD 它减少了训练样本个数减少了训练时间,相比 SGD 它增加了样本个数,提高了准确度。
\[W^{'}_p(new) = W^{'}_p(old) - \eta \frac{1}{M^{'}}\sum_{i=1}^{M^{'}}\frac{\partial E(\vec{X_i})}{\partial W^{'}_{p}(old)}\]
while (epoch > 0) {
shuffle(x, y)
let times = M / MB_size
for (int i = 0; i < times; i++) {
if (epoch == 0)
break
let grad_sum = 0.0
for (int j = 0; j < MB_size; j++) {
grad_sum = grad_sum + dLoss(x[i * MB_size + j], y[i * MB_size + j])
}
current_grad = current_grad - eta * grad_sum / MB_size
epoch = epoch - 1
}
}(这里也用了上面 SGD 的 shuffle 方法,这样看来 SGD 就是 Batch size 为 1 的 MBGD,好像有时候 MBGD 就叫 SGD)
对于 MBGD 和 SGD,有必要随训练轮数逐渐降低学习率。在梯度下降初期能接受较大的步长,以较快的速度下降。在收敛时,我们希望步长小一些,在最小值附近小幅度摆动。
关于 BGD,SGD 和 MBGD 可以参考下面的这几篇文章,我觉得第一篇最好:
这里我还要提一嘴 Batch Normalization(批标准化,即 BN)。在深度神经网络训练过程中,BN 使得每一层神经网络的输入保持相同分布的。这里有一篇非常不错的文章可以读一读,我简单摘一段:
BN 的基本思想其实相当直观:因为深层神经网络在做非线性变换前的 激活输入值 (就是那个 x=WU+B,U 是输入) 随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近 (对于 Sigmoid 函数来说,意味着激活输入值 WU+B 是大的负值或正值),所以这导致 反向传播时低层神经网络的梯度消失 ,这是训练深层神经网络收敛越来越慢的 本质原因 ,而 BN 就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为 0 方差为 1 的标准正态分布 ,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样 让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
简单来说,它的功能就是对 M 个样本在 每一层 的输入向量做归一化,然后再做仿射变换。画成图的话就是这样,就像是在上一层到下一层的线性变换中间加了一层 BN 层:
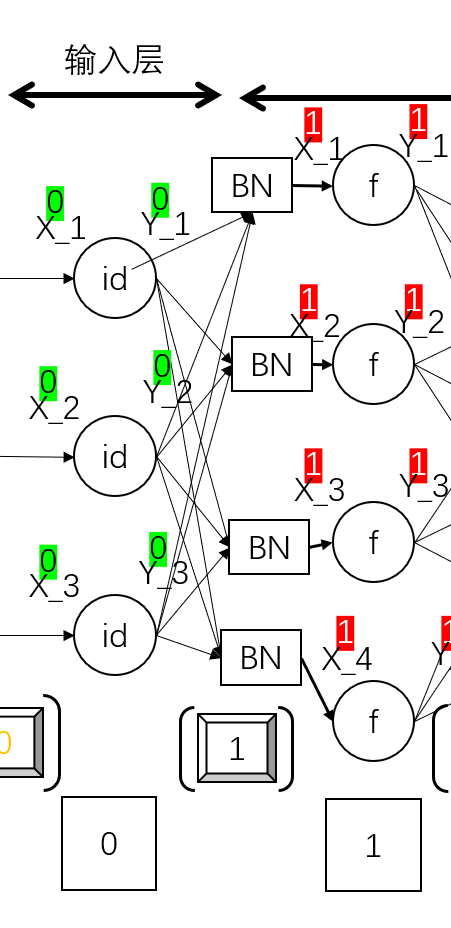
这里给出其他几种归一化的论文,在写到这里时我还没有看过,也许以后有机会来看看。
- https://arxiv.org/pdf/1502.03167.pdf BN, Batch Normalization
- https://arxiv.org/pdf/1607.06450v1.pdf LN, Layer Normalization
- https://arxiv.org/pdf/1607.08022.pdf IN, Instance Normalization
- https://arxiv.org/pdf/1803.08494.pdf GN, Group Normalization
- https://arxiv.org/pdf/1806.10779.pdf SN, Switchable Normalization
刚开始听到超参数这个词我还挺奇怪它到底是个什么东西,后来才知道它是为了和模型参数区分。模型参数就是网络中的权值和偏移参数值,它们会在训练过程中收敛到某些数值。一些需要人为设定的参数就是超参数,调节这些参数就是机器学习中的“调参”。上面提到的学习率就是一个超参数。
关于超参数,我目前只能简单理解为“需要用手调的参数”,以下文章可能有助于更进一步的了解:
现在有了确定的数学公式,可以正式开始我们的实现过程了。由于开头提到的原因,这里我选择 ReScript 来作为神经网络的实现语言。它是一种编译到 JavaScript 的语言,相比 JS 更强调函数式特性,对 JS 中各种令人恼火的问题也做出了相当不错的改进。
首先需要在你的机器上安装 node,node 的安装过程我就略过了。node 安装完成后(Node.js version >= 10),可以前往 ReScript Installation 页面按照文档中的指示来创建 ReScript 项目,当前(2022/11/13)的官方文档指示如下:
git clone https://github.com/rescript-lang/rescript-project-template
cd rescript-project-template
npm install
npm run res:build
node src/Demo.bs.js
在完成上面命令的执行后,你的命令行窗口应该能看到 "Hello world" 输出。这样我们就完成了 ReScript 的安装。如果我们只需要编写简单的代码,那么我们不需要进行任何配置,直接在 src 目录下创建源文件编译执行即可。
在开始下一节的具体实现之前我们可以简单阅读一下语言的 API 文档,来找一找可以表达向量和矩阵运算的标准库函数。一些和数组相关的函数在 Js.Array2 模块中,它位于这里。
- 表达两个向量间的某些操作,我们可以写成
let f = (a,b,f)=>a->Js.Array2.mapi((_,i)=>f(a[i],b[i]))
f([1.0, 2.0], [2.0, 3.0], (x,y)=>x+.y)->Js.log
//[3, 5]- 表达矩阵左乘列向量,我们可以写成
let f = (m0,v1)=>m0->Js.Array2.map((v)=>v->Js.Array2.reducei((s,_,j) =>s+.v[j]*.v1[j],0.0))
f([[1.0, 2.0], [2.0, 1.0]], [1.0, 1.0])->Js.log
//[3, 3]- 表达将标量函数作用于向量的每一个元素,我们可以写成
let f = (v1,fun)=>v1->Js.Array2.map(fun)
[1.0, 2.0, 3.0]->f((x)=>x+.1.0)->Js.log
//[2, 3, 4]- 表达将一个列向量乘一个行向量得到矩阵,我们可以写成
let f = (vec1,vec2)=>vec1->Js.Array2.map((a)=>vec2->Js.Array2.map((b)=>a*.b))
[1.0, 2.0, 3.0]->f([1.0, 2.0, 3.0])->Js.log
//[[1, 2, 3], [2, 4, 6], [3, 6, 9]]- 表达将矩阵转置后乘一列向量,我们可以写成
let f = (mat,vec)=>mat[0]->Js.Array2.mapi((_,i)=>mat->Js.Array2.reducei((s,_,j)=>s+.mat[j][i]*.vec[j],0.0))
f([[1.0, 2.0], [1.0, 1.0]], [1.0, 1.0])->Js.log
//[2, 3]- 对两个矩阵对应元素执行某些操作,我们可以写成
let f = (mat1,mat2,fun)=>mat1->Js.Array2.mapi((v,i)=>v->Js.Array2.mapi((_,j)=>fun(mat1[i][j],mat2[i][j])))
f([[1.0, 2.0], [1.0, 1.0]], [[1.0, 1.0], [1.0, 1.0]], (x,y)=>x+.y)->Js.log
//[[2, 3], [2, 2]]在下面的实现中我们会使用上面提到的方法,这也几乎就是我们需要的所有矩阵运算了。
上面的这种写法偏向函数式一些,如你所见,完全没有赋值操作。那这样的代码与命令式代码会有性能差距吗?时间精力所限,这里我只选取了第一个函数做一些测试,仅图一乐。通过使用 ReScript 标准库 Console 中的 timeStart 和 timeEnd 函数,我们可以比较方便地测试某一段代码的运行时间。
由于 ReScript 会默认地进行柯里化,这对于纯计算的函数是比较不利的,因为我们并不需要柯里化带来的抽象便利,我们的目标是足够快的执行速度。所以,我们在编写计算函数时要在参数列表最前面加上 . 来告诉编译器取消柯里化。由于测试代码有点长,我把它放到了 gist 上,下面是部分代码:
let f = (a, b, f) => a->Js.Array2.mapi((_, i) => f(a[i],b[i]))
let f_c = (. a, b, f) => a->Js.Array2.mapi((_, i) => f(. a[i],b[i]))
let f_unsafe_get = (a, b, f) => a->Js.Array2.mapi((_, i) => f(Js.Array2.unsafe_get(a,i), Js.Array2.unsafe_get(b, i)))
let f_unsafe_get_c = (. a, b, f) => a->Js.Array2.mapi((_, i) => f(. Js.Array2.unsafe_get(a,i), Js.Array2.unsafe_get(b, i)))
let f_add = (a, b) => a->Js.Array2.mapi((_, i) => a[i] +. b[i])
let f_add_c = (. a, b) => a->Js.Array2.mapi((_, i) => a[i] +. b[i])
let f_add_unsafe_get = (a, b) => a->Js.Array2.mapi((_, i) => Js.Array2.unsafe_get(a,i) +. Js.Array2.unsafe_get(b, i))
let f_add_unsafe_get_c = (. a, b) => a->Js.Array2.mapi((_, i) => Js.Array2.unsafe_get(a,i) +. Js.Array2.unsafe_get(b, i))
//......测试循环次数是一千万,得到的结果如下:
######################
# no side effect now #
######################
f: 17.353s
f_unsafte_get: 17.517s
f_add: 3.269s
f_add_unsafe_get: 2.913s
CCCCCCCCCCCCCCCCCCCCCC
f_c: 3.343s
f_unsafe_get_c: 3.225s
f_add_c: 3.225s
f_add_unsafe_get_c: 2.746s
######################
# side effect start! #
######################
|||no create new out vector|||
fs: 17.243s
fs_unsafte_get: 17.375s
fs_add: 3.257s
fs_add_unsafe_get: 2.872s
CCCCCCCCCCCCCCCCCCCCCC
fs_c: 3.270s
fs_unsafe_get_c: 3.256s
fs_add_c: 3.139s
fs_add_unsafe_get_c: 2.733s
----------------------
|||create new out vector|||
fsn: 17.255s
fsn_unsafte_get: 17.362s
fsn_add: 3.251s
fsn_add_unsafe_get: 2.859s
CCCCCCCCCCCCCCCCCCCCCC
fsn_c: 3.274s
fsn_unsafe_get_c: 3.229s
fsn_add_c: 3.156s
fsn_add_unsafe_get_c: 2.755s
test: 2:39.888 (m:ss.mmm)
这里简单解释下上面各符号的意义。带 c 后缀表示取消了柯里化,带 unsafe 表示使用了无检查数组随机访问和写入。带 s 表示带有副作用,带 n 表示在有副作用的同时创建了新的结果向量而不是修改全局的结果向量, add 表示函数直接进行加法运算不使用加法函数。
可以看到,对于接受加法函数的函数,没有去柯里化与去柯里化大约有 5 倍左右的速度差距。使用了 unsafe 操作的函数与未使用在速度上没有太大差距。去柯里化后,接受与不接受加法函数的函数略有差距,但是不是非常大。至于是否使用副作用操作,貌似对最终用时没有太大的影响。
也就是说,只要去掉默认的柯里化就能够有不错的性能。下面让我们用 JS 的 TypedArray 试试,测试代码在这,结果如下:
######################
# no side effect now #
######################
f_unsafte_get: 32.029s
f_add_unsafe_get: 13.576s
CCCCCCCCCCCCCCCCCCCCCC
f_unsafe_get_c: 13.245s
f_add_unsafe_get_c: 12.952s
######################
# side effect start! #
######################
|||no create new out vector|||
fs_unsafte_get: 30.436s
fs_add_unsafe_get: 13.433s
CCCCCCCCCCCCCCCCCCCCCC
fs_unsafe_get_c: 13.176s
fs_add_unsafe_get_c: 13.251s
----------------------
|||create new out vector|||
fsn_unsafte_get: 31.802s
fsn_add_unsafe_get: 15.036s
CCCCCCCCCCCCCCCCCCCCCC
fsn_unsafe_get_c: 14.586s
fsn_add_unsafe_get_c: 13.151s
test: 3:36.685 (m:ss.mmm)也许是我的用法有点问题,使用 TypedArray 反而比 Array 要慢上不少。
根据上面的测试结果,我至少可以得出以下结论:
- 应使用 JS 的 Array 而不是 TypedArray
- 去柯里化对计算性能有很大提升
- 命令式风格对速度提升帮助不大
在下面的实现中,我会对所有的计算函数去柯里化,而且尽量避免赋值操作。
我将整个实现分为了三个部分,分别是矩阵运算模块,网络结构定义模块和 BP 网络计算模块。在矩阵模块中我定义了我们需要用到的向量和矩阵计算函数,在结构模块中我定义了表示网络参数的结构体以及一些辅助函数,在 BP 模块我定义了前向和反向传播函数,以及训练和推理等用户函数。
所有的代码我都放在了 github 上,如果你有兴趣试一试的话,下载后按照 ReScript 文档中描述的安装方式安装即可。除了网络的实现代码,我还添加了一些简单的示例。
首先,我们在 src 目录下创建一个叫做 M.res 的文件,将我们在上面得到的矩阵运算函数放入其中。这里我没有使用 Js.Array2 模块,而是使用了 ReScript 的 Belt.Array 模块,它的速度更快。
- 向量点乘
dot
\[[x_1, x_2, ..., x_n]^T \cdot [y_1, y_2, ..., y_n]^T = \sum_{i=1}^{n}x_iy_i\]
let dot = (. x, y) => {
x->Belt.Array.reduceWithIndexU(0.0, (. sum, _, i) => {
sum +. Js.Array2.unsafe_get(x, i) *. Js.Array2.unsafe_get(y, i)
})
}- 向量转置
tr
let tr = (. mat) => {
mat->Js.Array2.unsafe_get(0)->Belt.Array.mapWithIndexU((. i, _) => {
mat->Belt.Array.mapWithIndexU((. j, _) => {
mat->Js.Array2.unsafe_get(j)->Js.Array2.unsafe_get(i)
})
})
}- 由两向量经过某种运算得到一个新向量
vvf2v(vector-vector to vector by function)- 比如向量相加相减
\[(X, Y, f) \rightarrow [f(x_1, y_1), f(x_2, y_2), ...]^T\]
let vvf2v = (. x, y, f) => {
x->Belt.Array.mapWithIndexU((. i, _) => {
f(. Js.Array2.unsafe_get(x, i), Js.Array2.unsafe_get(y, i))
})
}
let vvadd = (. x, y) => ((. a, b) => a+.b)->vvf2v(. x, y, _)
let vvsub = (. x, y) => ((. a, b) => a-.b)->vvf2v(. x, y, _)
let vvmul = (. x, y) => ((. a, b) => a*.b)->vvf2v(. x, y, _)
let vvdiv = (. x, y) => ((. a, b) => a/.b)->vvf2v(. x, y, _)- 矩阵左乘列向量
matxvec
\[A \cdot \vec{X}\]
let matxvec = (. m, v) => m->Belt.Array.mapU((.mv) => dot(. mv, v))- 将标量函数转化为向量函数
sf2vf(scalar fun to vector fun)
\[y = f(x) \rightarrow \vec{Y} = F(\vec{X})\]
let sf2vf = (. v, f) => v->Belt.Array.mapU(f)- 列向量乘行向量得到矩阵
vxv2m(vector x vector to matrix)
\[ [x_1, x_2, ..., x_m]^T \cdot [y_1, y_2, ..., y_n] = A_{mn}\]
let vxv2m = (. vt, v) => vt->Belt.Array.mapU((.a) => v->Belt.Array.mapU((.b) => a*.b))- 矩阵转置后乘列向量
tmatxvec(t matrix x vector)
\[ A^T\vec{X}\]
let tmatxvec = (. tm, v) => {
Js.Array2.unsafe_get(tm, 0)->Belt.Array.mapWithIndexU((. i, _) => {
tm->Belt.Array.reduceWithIndexU(0.0, (. sum, _, j) => {
sum +. tm->Js.Array2.unsafe_get(j)->Js.Array2.unsafe_get(i) *.
v->Js.Array2.unsafe_get(j)
})
})
}- 由两矩阵经过某种运算得到一个新矩阵
mmf2m,类似于vvf2v
let mmf2m = (. x, y, f) => {
x->Belt.Array.mapWithIndexU((. i, v) => {
v->Belt.Array.mapWithIndexU((. j, _) => {
f(. x->Js.Array2.unsafe_get(i)->Js.Array2.unsafe_get(j),
y->Js.Array2.unsafe_get(i)->Js.Array2.unsafe_get(j))
})
})
}
let mmadd = (. x, y) => ((. a, b) => a+.b)->mmf2m(. x, y, _)
let mmsub = (. x, y) => ((. a, b) => a-.b)->mmf2m(. x, y, _)- 将标量函数变为矩阵函数
sf2mf,类似于sf2vf
let sf2mf = (. m, f) => {
m->Belt.Array.mapU((.v) => v->Belt.Array.mapU((.a) => f(.a)))
}- 最后,是
mmf2m和vvf2v的副作用版本,结构存储在第一个参数中
let mmf2mInPlace = (. x, y, f) => {
x->Belt.Array.forEachWithIndexU((. i, v) => {
v->Belt.Array.forEachWithIndexU((. j, _) => {
let val = f(. x->Js.Array2.unsafe_get(i)->Js.Array2.unsafe_get(j),
y->Js.Array2.unsafe_get(i)->Js.Array2.unsafe_get(j))
Js.Array2.unsafe_get(x, i)->Js.Array2.unsafe_set(j, val)
})
})
}
let vvf2vInPlace = (. x, y, f) => {
x->Belt.Array.forEachWithIndexU((. i, _) => {
let val = f(. x->Js.Array2.unsafe_get(i),
y->Js.Array2.unsafe_get(i))
x->Js.Array2.unsafe_set(i, val)
})
}
以上代码实现的向量运算和矩阵运算功能已经够我们用了,矩阵模块的测试代码位于 TestM.res 中。
好了,现在我们已经有了自己的简单矩阵运算模块 M ,可以开始编写神经网络相关的数据结构了,现在我们在 M.res 相同目录下创建 S.res ,添加一些数据结构和辅助函数。
首先,我们需要为权值矩阵和偏移向量定义一个专门的数据结构和对应的辅助函数,在编写前向传播和反向传播时使用这些结构和函数会更方便。在上文中我提到了每一层是可以使用不同的激活函数的,虽然这种情况非常少见。这里我还是选择把函数也放到结构里,这是个向量函数,接受一个向量,然后返回一个向量,返回的向量的每一项是原项的激活函数输出结果。再次借用上面数学推导用的图,这个结构中应该包含图中红圈中的内容:

在前向传播中我们要使用激活函数,在反向传播中我们要使用激活函数的导数,所以我们也应该包含激活函数的导数。在上一节中我们看到有些激活函数求导时可以使用先前求得的激活函数值,所以我们可以让导函数接受参数和函数值,以提高求导速度:
type xy = {
x: array<float>,
y: array<float>
}
type d_fn = (xy) => array<float>如果我们已经有了标量激活函数,我们可以使用以下函数将其转换为向量函数,这里也顺带加上矩阵版本:
let v = (f) => (vec) => vec->Belt.Array.mapU(f)
let m = (f) => (mat) => mat->Belt.Array.mapU((. v) => v->Belt.Array.mapU(f))我们可以用 ReScript 的 Record 来实现这样的结构体,就像这样:
type wbfn = {
w: array<array<float>>,
b: array<float>,
f: (. array<float>) => array<float>,
df: (. xy) => array<float>,
na: float,
nb: float
}
type net = array<wbfn>
其中, w 是某一层的权值矩阵, b 是该层的偏移向量, f 和 df 是对应的激活函数和激活导函数, na 和 nb 是 BN 的仿射变换参数(由于我最后没有实现 BN,所以它们取常值 1.0 和 0.0,表示不进行仿射变换)。通过一个该类型的数组我们可以确定某个神经网络的一些基本参数。我们可以考虑定义一个 create 函数,它接受一些参数来创建 net 类型值:
let create = (~netarr, ~farr, ~narr: array<(float, float)>, ~initfun: () => float) => {
let check = (arr) => {
arr->Belt.Array.length >= 3 &&
arr->Belt.Array.everyU((. x) => x > 0)
}
if !check(netarr) {
Error("S.create: check failed, length not enough or netarr[?] is 0")
} else {
Ok(netarr->Belt.Array.sliceToEnd(1)->Belt.Array.mapWithIndex((i, _) => {
let w = Belt.Array.makeBy(netarr[i+1], (i) => {
Belt.Array.makeBy(netarr[i], (_) => initfun())
})
let b = Belt.Array.makeBy(netarr[i+1], (_) => initfun())
let (f, df) = farr[i]
let (na, nb) = narr[i]
{w: w, b: b,
f: f, df: df,
na: na, nb: nb}
}))
}
}
通过将神经元个数数组,激活函数和导函数元组数组、 仿射变换参数元组数组 ,和 JS 的 Math.random 函数传给上面的 create 函数,我们就创建了一个随机参数的神经网络。
在反向传播过程中我们会获得权值矩阵和偏移向量对应的梯度矩阵和向量,我们当然可以使用 wbfn 结构来存储这些梯度值,但既然梯度不需要函数之类的成员,这里我还是专门为它定义一个类型 wb :
type wb = {
dw: array<array<float>>,
db: array<float>
}
type grad = array<wb>
现在让我们定义一些对于 net 和 grad 数据结构的辅助函数,可以实现一些训练中用得到的操作:
let wbfn2wb = (ne: net, fn) => {
ne->Belt.Array.mapU((. s) => {
{
dw: s.w->M.sf2mf(. _, fn),
db: s.b->M.sf2vf(. _, fn)
}})
}
let wbmap = (ww: grad, fn) => {
ww->Belt.Array.mapU((. s) => {
{
dw: s.dw->M.sf2mf(. _, fn),
db: s.db->M.sf2vf(. _, fn)
}
})
}
let wbOpInPlace = (. g1: grad, g2: grad, fun) => {
g1->Belt.Array.forEachWithIndexU((. i, _) => {
M.mmf2mInPlace(. g1[i].dw, g2[i].dw, fun)
M.vvf2vInPlace(. g1[i].db, g2[i].db, fun)
})
}
let wbfnOpInPlace = (. ne: net, gr: grad, fun) => {
ne->Belt.Array.forEachWithIndexU((. i, _) => {
M.mmf2mInPlace(. ne[i].w, gr[i].dw, fun)
M.vvf2vInPlace(. ne[i].b, gr[i].db, fun)
})
}
let wbAddInPlace = (. g1: grad, g2: grad) => {
wbOpInPlace(. g1, g2, (. x, y)=>x+.y)
}
let wbfnUpdateInPlace = (. ne: net, gr: grad, eta) => {
wbfnOpInPlace(. ne, gr, (. x, y) => x -. eta *. y)
}
wbfn2wb 函数将 net 转化为 grad 结构,相当于是复制了整个 net 的形状。 wbmap 函数可以用来复制 grad 结构。 wbAddInPlace 和 wbfnUpdateInPlace 主要用在训练过程中,分别用来对梯度求和以及对权值和偏移进行修改。
S.res 模块的测试代码位于 TestS.res 中。
接着我们就可以开始真正的神经网络实现过程了,还是在同一目录下创建 Bp.res 文件,然后编写一些激活函数及其导数:
// Bp.res
let sigmoid = (.x) => 1.0 /. (1.0 +. Js.Math.exp(-.x))
let vsigmoid = S.v(sigmoid)
let vsigmoid_d = (. st: S.xy) => {
let yarr = st.y
yarr->Belt.Array.mapWithIndexU((. i, _) => {
let y = Js.Array2.unsafe_get(yarr, i)
y *. (1.0 -. y)
})
}
let tanh = (.x) => {
let pos = Js.Math.exp(x)
let neg = 1.0 /. pos
(pos -. neg) /. (pos +. neg)
}
let vtanh = S.v(tanh)
let vtanh_d = (. st: S.xy) => {
let yarr = st.y
yarr->Belt.Array.mapWithIndexU((. i, _) => {
let y = Js.Array2.unsafe_get(yarr, i)
1.0 -. y *. y
})
}
接着我们就可以开始实现前向传播过程了。(忽略掉包含 na 和 nb 的代码,它们不重要)
\[\left\{\begin{array}{l}\vec{X_p} = W_p \vec{Y_{p-1}} + \vec{B_p} \\\vec{Y_p} = f(\vec{X_p})\end{array}\right.\ p = 1, 2, 3, ... N+1 \]
let forward = (ix: array<float>, ne: S.net) => {
let len = Belt.Array.length(ne)
let x = ref(ix)
Belt.Array.makeBy(len, (i) => {
let t = x.contents
->M.matxvec(. ne[i].w, _)
->M.vvadd(. _, ne[i].b)
->Belt.Array.mapU((. a) => a *. ne[i].na +. ne[i].nb)
let y = t->ne[i].f(._)
let xodd = x.contents
x := y
(xodd, y)
})
}接着我们可以实现后向传播过程中要用到的损失函数,我们没有必要专门定义一个代价函数,可以直接由对多个样本的损失函数求平均得到代价函数值:
\[e = \frac12|| \vec{Y} - \vec{Y_{t}}||^2 = \frac{1}{2}\sum_{i=1}^{N}(y_i - y_i^t)^{2} \]
let loss2 = (y: array<float>, yt: array<float>) => {
y->Belt.Array.reduceWithIndexU(0.0, (. sum, _, i) => {
let a = Js.Array2.unsafe_get(y, i)
let b = Js.Array2.unsafe_get(yt, i)
let sub = a - b
sum +. sub *. sub *. 0.5
})
}
let dloss2 = (y: array<float>, yt: array<float>) => {
y->Belt.Array.mapWithIndexU((. i, _) => {
let a = Js.Array2.unsafe_get(y, i)
let b = Js.Array2.unsafe_get(yt, i)
a - b
})
}
有了前向传播函数和损失函数,我们可以开始定义反向传播函数了,它作用于一个样本,返回样本的梯度矩阵和向量结构 wb ,(这里同样请忽略掉 na 和 nb ),该函数的最后一个参数是网络中的最后一个误差项向量(即上面推导过程中的 \(\vec{\delta_{N+1}}\)),根据它我们可以推出其他所有误差项向量。
\[\left\{\begin{align*}\vec{\delta{p}} &= \frac{\partial E}{\partial \vec{X_{p}}} = [\frac{\partial E}{\partial {x_1^{p}}}, \frac{\partial E}{\partial {x_2^{p}}}, ..., \frac{\partial E}{\partial x_{m_{p}}^{p}}]^T \\\frac{\partial E}{\partial W_{p}} &= \vec{\delta_{p}} \cdot \vec{Y_{p-1}}^T \\ \frac{\partial E}{\partial \vec{B_p}} &= \vec{\delta_p}\end{align*}\right. \quad p=1, 2, 3, ..., N+1\]
\[\vec{\delta_{p}} = \frac{\partial E}{\partial \vec{X_{p}}} = D_pW_{p+1}^{^T}\vec{\delta_{p+1}} \quad D_p = \left(\begin{matrix}f^{'}(x_1^{p})&0&\cdots&0\\0&f^{'}(x_2^{p})&\cdots&0\\\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&f^{'}(x_{m_{p}}^p)\end{matrix}\right)\quad p=1, 2, 3, ..., N\]
let backward = (ne: S.net, xyarr: array<S.xy>, inputx, delta0) => {
let len = Js.Array2.length(ne)
let ne1 = ne->Belt.Array.slice(~offset=1, ~len=len-1)
let xyarr1 = xyarr->Belt.Array.slice(~offset=0, ~len=len-1)
let deltana = delta0->M.sf2vf(. _, (.x) => x*.ne[len-1].na)
let delarr = Belt.Array.reduceReverse2U(ne1, xyarr1, [deltana], (. c, a, b) => {
let tm_delta = M.tmatxvec(. a.w, c[0])
let dfvec = b->a.df(._)->M.sf2vf(. _, (.x) => x*.a.na)
[dfvec->M.vvmul(. _, tm_delta)]->Belt.Array.concat(c)
})
delarr->Belt.Array.mapWithIndexU((. i, _) => {
if i != 0 {
let (_, yv) = xyarr[i-1]
{S.dw: delarr[i]->M.vxv2m(. _, yv),
db: delarr[i]}
} else {
{S.dw: delarr[i]->M.vxv2m(. _, inputx),
db: delarr[i]}
}
})
}
有了前向传播与后向传播,现在可以定义出训练函数了,为了方便创建训练用到的参数,我这里定义了 super 结构及其模板,使用模板可以方便地创建自己的 super 结构:
type super = {
neta: array<int>,
farr: array<((. array<float>)=>array<float>, (. S.xy)=>array<float>)>,
narr: array<(float, float)>,
initf: () => float,
inputVs: array<array<float>>,
outputVs: array<array<float>>,
epoch: int,
etainit: float,
etafun: (. float, int) => float,
floss: (array<float>, array<float>) => float,
dlossdx: (S.xy, array<float>) => array<float>,
}
let sup1_template = {
neta: [2, 4, 3],
farr: [(vsigmoid, vsigmoid_d), (vsigmoid, vsigmoid_d)],
narr: [(1.0, 0.0), (1.0, 0.0)],
initf: Js.Math.random,
inputVs: [[1.0, 2.0], [3.0, 4.0]],
outputVs: [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]],
epoch: 1000,
etainit: 0.01,
etafun: (. eta, _) => eta,
floss: loss2,
dlossdx: dloss2dx
}
这里解释一下最后一个成员 dlossdx ,该函数接受两个参数,分别是输出层的输入输出 xy 结构和目标输出向量,它返回最后一个误差项向量。它的返回值用于后向传播函数 backward 。对于上面的 loss2 函数,它的 dlossdx 是:
let dloss2dx = (xy: S.xy, yt: array<float>) => {
let (_, yarr) = xy
let dfv = xy->vsigmoid_d(._)
M.vvmul(. dfv, dloss2(yarr, yt))
}
现在我们可以实现训练函数了,它接受 super 结构作为参数,并返回训练好的 wbfn 结构体:
let train_bgd = (su: super, ~logfn=?, ()) => {
let net = S.create(~netarr=su.neta,
~farr=su.farr,
~narr=su.narr,
~initfun=su.initf)->Belt.Result.getExn
let len = net->Js.Array2.length
let batchSize = su.inputVs->Js.Array2.length
for i in 0 to su.epoch - 1 {
let gr = net->S.wbfn2wb((. _) => 0.0)
let forwards = []
for j in 0 to batchSize - 1{
let forwardCache = forward(su.inputVs[j], net)
ignore(forwards->Js.Array2.push(forwardCache))
let delta = su.dlossdx(forwardCache[len - 1], su.outputVs[j])
let gd = backward(net, forwardCache, su.inputVs[j], delta)
S.wbAddInPlace(. gr, gd)
}
let costgr = gr->S.wbmap((. x) => x /. Belt.Int.toFloat(batchSize))
S.wbfnUpdateInPlace(. net, costgr, su.etainit->su.etafun(. _, i))
switch logfn {
| None => ()
| Some(fn) => {
{i: i,
forwards: forwards,
inputs: su.inputVs,
outputs: su.outputVs,
lossfn: su.floss}->fn
}
}
}
net
}
方便起见,我加了一个 logfn 参数观察当前迭代情况,它是接受 loginfo 结构的函数,作用是打印一些中间值。
type loginfo = {
i: int,
forwards: array<array<S.xy>>,
inputs: array<array<float>>,
outputs: array<array<float>>,
lossfn: (array<float>, array<float>) => float
}
let log_example = (info: loginfo) => {
Js.log(info.i)
info.inputs->Belt.Array.reduceWithIndex(0.0, (sum, _, i) => {
let r = info.forwards[i]
let (_, y) = r[r->Js.Array2.length-1]
sum +. info.lossfn(y, info.outputs[i]) /.
Belt.Int.toFloat(info.inputs->Js.Array2.length)
})->Js.log
}
对于 SGD 和 MBGD,我们需要 shuffle 操作:
let shuffle = (x, y) => {
Belt.Array.zip(x, y)->Belt.Array.shuffle->Belt.Array.unzip
}
let train_sgd = (su: super, bsize, ~logfn=?, ()) => {
let net = S.create(~netarr=su.neta,
~farr=su.farr,
~narr=su.narr,
~initfun=su.initf)->Belt.Result.getExn
let len = net->Js.Array2.length
let btimes = su.inputVs->Js.Array2.length / bsize
let j = ref(0)
let inV = ref(su.inputVs)
let ouV = ref(su.outputVs)
for i in 0 to su.epoch - 1 {
if (j.contents == btimes) {
let (tinV, touV) = shuffle(su.inputVs, su.outputVs)
inV := tinV
ouV := touV
j := 0
}
let gr = net->S.wbfn2wb((. _) => 0.0)
let forwards = []
for k in j.contents * bsize to (j.contents + 1) * bsize - 1 {
let forwardCache = forward(inV.contents[k], net)
ignore(forwards->Js.Array2.push(forwardCache))
let delta = su.dlossdx(forwardCache[len-1], ouV.contents[k])
let gd = backward(net, forwardCache, inV.contents[k], delta)
S.wbAddInPlace(. gr, gd)
}
let costgr = gr->S.wbmap((. x) => x /. Belt.Int.toFloat(bsize))
S.wbfnUpdateInPlace(. net, costgr, su.etainit->su.etafun(. _, i))
switch logfn {
| None => ()
| Some(fn) => {
{i: i,
forwards: forwards,
inputs: inV.contents
->Belt.Array.slice(~offset=j.contents * bsize, ~len=bsize),
outputs: ouV.contents
->Belt.Array.slice(~offset=j.contents * bsize, ~len=bsize),
lossfn: su.floss}->fn
}
}
j := j.contents + 1
}
net
}
至此,我们就完成了一个简单神经网络的实现。 Bp.res 的测试代码位于 TestBp.res 中。
既然我们已经实现了一个神经网络,现在可以用一些简单的例子来测试一下它能不能正常工作。我们首先拿 xor 函数做个实验:
let net = {
Bp.neta: [2, 3, 4, 1],
farr: [(Bp.vsigmoid, Bp.vsigmoid_d),
(Bp.vsigmoid, Bp.vsigmoid_d),
(Bp.vsigmoid, Bp.vsigmoid_d)],
narr: [(1.0, 0.0), (1.0, 0.0), (1.0, 0.0)],
initf: Js.Math.random,
inputVs: [[1.0, 0.0], [1.0, 1.0], [0.0, 1.0], [0.0, 0.0]],
outputVs: [[1.0], [0.0], [1.0], [0.0]],
epoch: 10000,
etainit: 1.0,
etafun: (. eta, _) => eta,
floss: Bp.loss2,
dlossdx: Bp.dloss2dx}
let res1 = Bp.train_bgd(net, ~logfn=Bp.log_example, ())
[1.0, 0.0]->Bp.forward(res1)->((x) => x[x->Js.Array2.length-1])->Js.log
[1.0, 1.0]->Bp.forward(res1)->((x) => x[x->Js.Array2.length-1])->Js.log
[0.0, 1.0]->Bp.forward(res1)->((x) => x[x->Js.Array2.length-1])->Js.log
[0.0, 0.0]->Bp.forward(res1)->((x) => x[x->Js.Array2.length-1])->Js.log会得到类似这样的输出:
......
9997
0.00018323158529745724
9998
0.00018318409755041073
9999
0.00018313663294730462
[ [ 3.9918565707694778 ], [ 0.9818693890284741 ] ]
[ [ -3.875340462780331 ], [ 0.02032557278937673 ] ]
[ [ 3.9990788399982446 ], [ 0.981997512633213 ] ]
[ [ -3.8933838700171854 ], [ 0.019969376979891356 ] ]可见已经与准确值很接近了。
接着我们可以试试十以内的加法,输入长度为 20 的数组,例如 [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] 表示 2,2 + 2 就是两个这样的数组连接起来,以此类推。输出是长度为 19 的向量,表示 0~18。我们用神经网络拟合一下这个函数:
let a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
let num2vec = (a, n) => {
Belt.Array.makeBy(n, (i) => {
a == i ? 1.0 : 0.0
})
}
let allin = a->Js.Array2.mapi((_, i) => {
a->Js.Array2.mapi((_, j) => {
Js.Array2.concat(i->num2vec(10), j->num2vec(10))
})
})->Belt.Array.concatMany
let allout = a->Js.Array2.mapi((_, i) => {
a->Js.Array2.mapi((_, j) => {
(i+j)->num2vec(19)
})
})->Belt.Array.concatMany
let net2 = {
...net, // xor 例子中的 net
neta: [20, 5, 8, 19],
inputVs: allin,
outputVs: allout,
epoch: 100000,
etainit: 0.5
}
let res2 = Bp.train_bgd(net2, ())
let inference = (input, ne) => {
let res = Bp.forward(input, ne)
let (_, output) = res[res->Js.Array.length - 1]
let r2 = output->Belt.Array.reduceWithIndexU((0, output[0]), (. r, a, i) => {
let (_, v) = r
if (v < a) {
(i, a)
} else {
r
}
})
let (ret, _) = r2
ret
}
let succ = ref(0)
for i in 0 to 9 {
for j in 0 to 9 {
let a = allin[i * 10 + j]->inference(res2)
if a == i + j {
succ := succ.contents + 1
}
}
}
succ->Js.log
上面的代码在我的电脑上运行需要几分钟,毕竟有十万轮,我最后得到的结果是 { contents: 96 } ,也就是说对训练数据的预测成功率为 96%。(这么点训练数据都拟合不全对的屑)
上面的示例代码位于 Test.res 文件中。
上面的两个例子都使用了较简单的数学函数,而且将函数的全部作用域和对应的值都喂给了神经网络,可能并不是很能体现出神经网络对未知数据的推理能力。下面我们使用 MNIST 上的数据集来训练网络识别手写数字。MNIST 的官方网站在这,上面共有 60000 张训练图片和标签,以及 10000 张测试图片与标签。图片和标签以二进制形式分别存储在单个文件中。
在开始之前我们先学一些和训练测试数据相关的概念,即训练集(train)、验证集(validation)和测试集(test)。训练集很好理解,就是在训练过程中使用的数据的集合,比如上面例子中的输入向量。测试集就是对已经训练好的神经网络做测试的数据集合。那么什么是验证集呢?验证集不参与训练过程,它用于选择网络的超参数,比如网络层数、网络节点数、迭代次数、学习率等参数。
网上的教程一般都是使用 CNN(卷积神经网络)来对 MNIST 进行分类识别,我这个神经网络简单了些,不过效果勉强还行,在测试集上最高能有 80% 左右的正确率。
在官方网站上下载文件并解压后,我们可以得到这样的 4 个文件:
- train-images.idx3-ubyte,包含用于训练的 60000 张 28 * 28 图片
- train-labels.idx3-ubyte,包含用于训练的 60000 张图片的标签,标签值从 0 到 9
- t10k-images.idx3-ubyte,用于测试的 10000 张 28 * 28 图片
- t10k-labels.idx3-ubyte,用于测试的 10000 张图片的标签
下载并解压后,请将这四个文件放到 github 项目的 src 目录下。参考这篇文章,我们可以使用以下代码进行提取。
const fs = require('fs')
const bu = require('buffer')
let readbin = (fname) => {
return fs.readFileSync(fname)
}
let test_data_fname = './t10k-images.idx3-ubyte'
let test_label_fname = './t10k-labels.idx1-ubyte'
let train_data_fname = './train-images.idx3-ubyte'
let train_label_fname = './train-labels.idx1-ubyte'
let get_train_arr = () => {
let arr1 = new Array(60000)
let arr2 = new Array(60000)
let f1 = fs.readFileSync(train_data_fname)
let f2 = fs.readFileSync(train_label_fname)
let i = 0
let item_len = 28 * 28
for (i = 0; i < 60000; i++) {
arr1[i] = new Array(item_len)
arr2[i] = f2.readUInt8(8 + i)
for (j = 0; j < item_len; j++) {
arr1[i][j] = f1.readUInt8(16 + item_len * i + j)
}
}
return [arr1, arr2]
}
let get_test_arr = () => {
let arr1 = new Array(10000)
let arr2 = new Array(10000)
let f1 = fs.readFileSync(test_data_fname)
let f2 = fs.readFileSync(test_label_fname)
let i = 0
let item_len = 28 * 28
for (i = 0; i < 10000; i++) {
arr1[i] = new Array(item_len)
arr2[i] = f2.readUInt8(8 + i)
for (j = 0; j < item_len; j++) {
arr1[i][j] = f1.readUInt8(16 + item_len * i + j)
}
}
return [arr1, arr2]
}
exports.getTrain = get_train_arr
exports.getTest = get_test_arr
通过调用 get_train_arr 和 get_test_arr ,我们就可以获得训练集数据和测试集数据。使用以下代码,我们便可以在 ReScript 中使用这两个函数了:
@module("./Rm.js")
external getTrain: () => (array<array<float>>, array<int>) = "getTrain"
@module("./Rm.js")
external getTest: () => (array<array<float>>, array<int>) = "getTest"MNIST 上的图片是 28 * 28 的图片,也就是说我们的神经网络要接受长度为 784 的输入向量。图片上的数字可以是 0~9,那么网络的输出应该是长度为 10 的向量,输出的数字对应位置的元素值为 1,其余位置元素为 0。
老实说,写到这里我还没想过啥是回归问题和分类问题,不过在上一节的个位数加法例子中我还是隐隐约约有些感觉,我还没有蠢到在输出层用一个 sigmoid 神经元的输出来表示两个数相加的结果,毕竟 sigmoid 的值域是 0 到 1(不过输出神经元取 y=x 作为激活函数也许可行)。难道神经网络只能用来处理那些输出一个或多个 0 或 1 的问题吗?还是先看看什么是回归,什么是分类吧家人们。
上面的两个回答是我认为看起来比较有道理的,这两个问题下也有其他的观点,随便看看就行了,我们以下面的定义为主:
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
上面的个位数字加法之所以需要如此之多的迭代次数,而且最后结果还不是全对的原因可能是我们把一个回归问题强行当作分类问题处理了,而且还没有用分配问题中常用的交叉熵损失函数和 softmax 激活函数,而是用了上面自己写的四不像损失函数和 sigmoid 函数。真要实现个位加法的话一个神经元足矣, W = id(a + b + 0) 嘛(笑)。
回到我们现在的问题,我们要根据一个 784 长度的向量得到长度为 10 的 one-hot(指向量中只有一项为 1,其余项为 0,和独热码挺像的)向量,这就是典型的分类问题,如果还是使用上面定义的损失函数和 sigmoid 效果非常不好,我已经帮你试过了。那么现在我们来看看为什么 softmax 和交叉熵能比较好的处理分类问题(这里就是多分类问题)。
我本打算简单写一下,不过我发现这一篇写的非常好:直观理解为什么分类问题用交叉熵损失而不用均方误差损失? – 日拱一卒,作者从损失函数和激活函数两方面分析了使用交叉熵和 softmax 的原因。然后我发现数学公式似乎也不用我写了(笑),其他的文档也很不错,不过我就不一一列出了。
总之,我们只需要在最后一层使用 softmax,然后使用 δ = dE/dx 求出 \(\vec{\delta_{N+1}}\) 即可,它的公式非常简单,即:
\[\vec{\delta_{N+1}} = \vec{Y_{N+1}} - \vec{Y_{N+1}^t}\]
\(\vec{Y_{N+1}^t}\) 表示目标输出向量。
首先,我们使用 getTrain 和 getTest 函数获取训练集和测试集数据:
let (tr_ivs, tr_ios) = getTrain()
let (te_ivs, te_ios) = getTest()由于输入数组中的各项是 0~255 的灰度值,我们需要先将其归一化到 0~1 的范围:
let tr_ipt = tr_ivs->Belt.Array.mapU((. a) => {
a->Belt.Array.mapU((. b) => {
b /. (255.0)
})
})
let tr_opt = tr_ios->Belt.Array.mapU((. a) => {
Belt.Array.makeBy(10, (i) => {
i == a ? 1.0 : 0.0
})
})
let te_ipt = te_ivs->Belt.Array.mapU((. a) => {
a->Belt.Array.mapU((. b) => {
b /. (255.0)
})
})
接着可以定义 softmax 和交叉熵损失函数,以及损失函数对最后一层 x 向量的导数:
let softmax = (. v) => {
let maxval = v->Belt.Array.reduceU(v[0], (. m, x) => {
m > x ? m : x
})
let expres = v->Belt.Array.mapU((. x) => {
Js.Math.exp(x -. maxval)
})
let sum = expres->Belt.Array.reduceU(0.0, (. sum, x) => sum +. x)
M.sf2vf(. expres, (. x) => x /. sum)
}
let crossloss = (y, yt) => {
y->Belt.Array.reduceWithIndexU(0.0, (. sum, _, i) => {
sum -. yt[i] *. Js.Math.log(y[i])
})
}
let dcrosslossdx = (xy: S.xy, yt: array<float>) => {
let (_, y) = xy
M.vvsub(. y, yt)
}
接着利用 super 模板创建训练参数结构:
let tin = tr_ipt->Belt.Array.slice(~offset=0, ~len=60000)
let tou = tr_opt->Belt.Array.slice(~offset=0, ~len=60000)
let su = {
...Bp.sup1_template,
neta: [784, 20, 10],
inputVs: tin,
outputVs: tou,
epoch: 2400,
etainit: 1.0,
etafun: (. eta, i) => eta *. (0.999 ** Belt.Int.toFloat(i)),
floss: crossloss,
dlossdx: dcrosslossdx,
farr: [(Bp.vsigmoid, Bp.vsigmoid_d), (softmax, (.x) => {let (_, y) = x; y})]
}
可以看到这里最后一层使用了 softmax 函数,因为最后一层的导数实际不参与计算,这里就写了个空函数 (.x) => {let (_, y) = x; y} 。
最后是训练过程和推理过程,由于有 60000 个训练样本,此时使用 BGD 运行一轮都够我电脑 CPU 喝一壶的,这里我们采用 MBGD 方法,取 mini-batch 为 100,训练次数为 2400:
Js.Console.timeStart("fin")
let r1 = Bp.train_sgd(su, 100, ~logfn=Bp.log_example, ())
let inference = (input, ne) => {
let res = Bp.forward(input, ne)
let (_, output) = res[res->Js.Array.length - 1]
let r2 = output->Belt.Array.reduceWithIndexU((0, output[0]), (. r, a, i) => {
let (_, v) = r
if (v < a) {
(i, a)
} else {
r
}
})
let (ret, _) = r2
ret
}
let succ = ref(0)
for i in 0 to 10000 - 1 {
let inff = inference(te_ipt[i], r1)
if (inff == te_ios[i]) {
succ := succ.contents + 1
}
}
succ->Js.log
Js.Console.timeEnd("fin")最后的结果是:
2398
0.4890885936389829
2399
0.6096737216766385
{ contents: 8172 }
fin: 1:30.293 (m:ss.mmm)
如果不使用 log 函数,速度还会更快。最后我得到的正确率在 80% 上下浮动。再调大轮数似乎没有什么效果了。
MNIST 识别代码位于 Mnist.res 文件中。
严格来说这篇文章我至少“写”了两三遍(笑),在具体使用自己写的神经网络时会不断发现缺少的东西,然后回溯到代码实现部分或数学推导部分修改或加上新东西,再回到具体的问题处。相比于最开始的文章,现在的文章已经千疮百孔了,但在这个过程中我也(不得不)去学了许多新鲜玩意,比如 SGD,BGD,MBGD,交叉熵,relu,softmax,超参数,MNIST,等等。从一开始神经网络都不会推到现在实现了个神经网络的 Hello world,在这个过程中我也确实是有所收获。
神经网络也确实给我带来了一种新的视角。看到异或训练过程中误差函数值逐渐降到接近 0 的时候我还感觉蛮惊奇的,通过一堆神经元加上加权求和和非线性映射居然就能拟合一个简单的逻辑函数了。我们能口算异或不是因为我们有 CPU 能直接执行异或操作,而可能是我们脑中的神经元拟合出来的一个逻辑函数。不知道我们人的思维过程能不能看作一些神经网络的加权求和与非线性映射,再加上一些随机扰动呢?我不是太清楚人脑的思维过程与计算机中的神经网络运算有多大的相似性,不过这个想法对我来说还是挺好玩的(笑)。
要说我真正实操过的神经网络相关的东西,除了本文中我手写的简易网络,那就是我在一次课上用神经网络训练倒立摆控制器了。首先使用 PID 或其他控制算法控制倒立摆,并获取控制器的输入输出数据,然后丢到 Matlab 的神经网络工具箱中训练一通,再在 simulink 中用训练得到的网络模块替换掉原来的控制器就可以了。效果好不好另说,不过通过一些输入输出训练出的一个模块就可以起控制作用了,而作为执行者的我只是点了几下鼠标而已。
机器学习或者说人工智能早就已经开始对我们的生活产生影响了。就我们日常生活来说,一些视频平台的推送功能就使用了机器学习的算法,根据用户的点击来分析喜好以推送信息;人工智能也用在了搜索引擎上来帮助提高用户体验;现在的自动驾驶技术已经可以用了(好像是叫什么 L3,L4 之类的),虽然还时不时有失误的新闻;如果你比较关注游戏或显卡的话,NVIDIA 的 4090 使用的 DLSS3 技术也足够亮眼;人工智能亦可用在科学研究中,AlphaFold 在预测蛋白质结构上很成功;deepl 在翻译上让我感觉机翻比人翻的还要好。这些是我听的比较多的相关消息,可能生活中一些很不起眼的东西背后都用到了这方面的技术,只是我没有关注罢了。
最近看到的比较火的东西可能就是 stable diffusion 了,可以根据标签生成二次元美少女图片,让不会画画的凡人也能通过施咒来进行创作了(笑)。
你要问我人工智能能不能完全取代人类啥的,我感觉不会,但是部分取代我认为只是时间问题了,不过到时候我们肯定又有另外的事干了。我现在不是很清楚从几年前的人工智能热潮开始,到现在人工智能是不是还在流行(或者说火爆)。我在写这篇文章的过程中参考的一些基础教程或博文的最初发布时间集中在 2016~2020 之间,这也许可以说明在当时神经网络或深度学习确实很火。
好了,关于神经网络或深度学习的闲扯到此结束。我还挺庆幸这次使用了 ReScript(间接使用了 node)而不是 elisp 来编写神经网络,不然在速度上可能会慢上十几倍到几十倍不等。在编写 ReScript 代码的过程中我体会到了被编译器鞭挞的快乐,只要在强而有力的类型约束下写让编译器通过的代码,出错的可能性会小很多,一些本该在运行时出现的错误在编译时就发现了。如果没有这些友好的编译错误提示,JS 的各种坑够我喝一壶的。有类型的好处是在修改代码时不会忘掉哪里没有进行更新,因为编译器会用类型错误提醒你,我的数据结构至少变了三次,但每次都能在使用类型的地方做出对应的修改。
在写这篇文章之前我没有看过系统介绍深度学习方法的书,编写过程中我也是东拼西凑地找齐了需要的知识。写到这里,我所具备的相关知识也就是到能够勉强完成本文中内容的程度。这和我写 latex 很像,每次都是用到的时候去网上找各种杂七杂八的 latex 教程来糊一堆公式出来,用完就直接丢掉了。如果没有网络以及搜索引擎的话,我想写这样一篇文章就得向别人请教或者直接阅读相关书籍。通过搜索引擎的伟力(指真正好用的搜索引擎),这些碎片知识被更方便地端到了我的面前,就完成一个任务来说我也就没有必要专门找本书来翻了。
学习一方面是要能够解析文本中的知识,另外也要将解析后的知识存储起来,以后再用。这就像把训练好的神经网络参数输出到文本中,需要时直接读取一样。我们学习要记笔记也是这个道理,不是所有学到的东西都要直接记到脑子里的,一些不经常用的知识先记起来,供以后使用。记笔记这个过程就像是将知识以自己容易解析的方式输出到媒介中,之后可以很轻松地进行解析。这也是我写博客的一个原因,我很清楚自己的博文都写了什么,所以翻起来也很快。有没有必要基于博客来学着弄个知识系统呢?想想看再说。希望未来我们在知识的获取和学习上能做到更加高效和便捷。
在深度学习第一次出现在我的视线中的时候,我因为瞧不起 Python 而选择了不学,什么叫 “弱小和无知不是生存的障碍,傲慢才是” 啊。整个大学期间我就和深度学习没啥关联了,当然现在能学到一点皮毛当然也是好的,这里不得不感谢杨元超的深度学习课程,如果不是因为对 ReScript 感兴趣我这深度学习还真就懒得起步。
那我这一趟学习深度学习是偶然呢,还是必然呢?要我说就是必然,毕竟 世界上没有偶然,只有必然 。正是通过深度学习前几年的热潮,我才了解到了它,顺带知道了 arxiv,论文等新鲜东西。我不自觉地就随着潮流而移动了。某些东西在过去看起来没啥用,到了现在突然有用了,而某些东西过去很有用,现在却没啥用了。作为个体也没必要管那么多,顺着走就行了。
不知道你有没有过这样的疑惑:从古到今知识是积累的越来越多的,未来会不会出现还没有学到最新的知识人就死了的情况?好像有个名词来描述这种东西,叫做“知识膨胀”,我比较认同这个回答:
希望未来的人工智能能起到“知识收缩”的效果。
写这篇文章的过程中有两种思路不断地撕扯着我,首先我想要把活干完,我不想要学一些和干活关系不是很大的东西;另一方面我又想要把活干好,这就不得不让我放下手头的东西去学一学再回来做事。有时候就感觉写不下去了,有时候又一股脑写了很多。这就叫矛盾是推进事情发展的动力吗?(笑)
感谢阅读。