brainfuck 是一种 esolang,esolang 的全称是 esoteric programming language。esolang 指这样一类编程语言:被设计用于测试计算机语言表达的极限,或者仅仅是一个玩笑。esolang 的设计者几乎不会以提高易用性为目标,但会保证逻辑上的可用性。设计者通常会移除或取代传统语言的常见功能,但仍会强调并保持图灵完备。这里有个 esolang wiki,里面列举了一大堆的 esolang。
在成堆的 esolang 中 brainfuck 可能是最出名的那个,至少它是我第一个了解到的 esolang。就像我在文章开头提到的,brainfuck 仅由 8 条指令,一个数据指针和一个指令指针组成。brainfuck 由 Urban Müller 在 1993 年的 9 月发布,他受到了 FALSE 语言和 P'' 语言的影响。如果要给 brainfuck 一个中文翻译的话, 艹脑 也许不错,不过我觉得 *交 更好(笑)。
brainfuck 在内存数组上进行操作,它的数据指针初始位置为 0,数组的长度至少是 30000(最初的 brainfuck 实现使用了这个长度,不过也不一定要遵守),单个数组元素的大小似乎没有标准,这就由实现者决定是几个字节了。
下面是对 brainfuck 八指令的描述,在代码中出现的任意其他字符都被视作注释。不做说明的话下表的指针都指数据指针:
| Command | Description |
> |
向右移动指针 |
< |
向左移动指针 |
+ |
指针位置数据自增 1 |
- |
指针位置数据自减 1 |
. |
输出指针位置数据对应字符 |
, |
读入字符并存储到指针位置 |
[ |
若数据指针位置内容为 0,指令指针跳转到下一个 ] |
] |
若数据指针位置内容不为 0,指令指针跳转到上一个 [ |
以上就是 brainfuck 的全部内容了,更多内容可参考 esolang wiki brainfuck。下面是一个 hello world:
++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.你可以在一些在线网站上运行它,比如这里。
下面咱们就开始学着自己实现一个 brainfuck 解释器吧,不过我们还是先从一些基本概念开始,比如什么是解释器。由于我基本上算是从零开始,所以下面可能有点抓瞎。
说到解释器的话,一般的文章都会把它和编译器进行对比来体现两者的不同之处。不过现在我并不是太清楚编译器是什么,这里我只能凭感觉做一些直觉上的说明。解释器的英文是 interpreter ,当它作为“翻译”的意思使用时与 translator 相对,前者表示口译而后者表示笔译。口译过程中翻译需要将发言翻译为目标语言并让听者明白,笔译的话译者只需要要完成翻译并提交成稿即可,读者不一定(应该不会有这样的读者吧)要在翻译现场读译文。口译与笔译相比也许会更强调实时性一些。
如果我们抛开事实不谈,只关注“接收指令解释执行”的话,很多东西都可以和解释器沾上边,比如 CPU 执行机器码,操作系统接收鼠标和键盘输入并在桌面做出响应,汽车随方向盘和油门变化改变方向或车速,计算器接收按键输入并给出结果,等等。维基百科中这样说到:在计算机科学中,解释器是指这样一种 计算机程序 ,它能够 直接执行 由程序语言或脚本语言编写的 指令 ,而无需将它们编译为 机器语言程序 。不知你从这句话中能看出什么来,我认为它的重点还是在 执行 上,解释器是 执行者 。
了解过一点编译原理知识的同学应该知道编译器里面也有前端和后端的区分,就像现在的 Web 前后端一样。前端(front end)会读取程序文本(源代码)并将其转化为抽象语法树(abstrat syntax tree),完成这个任务的程序被叫做 Parser。Parser 的工作可以分为 scanning 和 parsing 两阶段。Scanning 过程会将源代码字符串序列分割为一个个 token,比如单词,数字等,并将结果交给下一过程。Parsing 过程会将 token 序列组织为层级语法结构(hierarchical syntactic structure),也就是生成语法树(可能更正规的说法是前端包括 tokenizer 和 parser ,这里我把前端的工作都放到了 parser 里)。
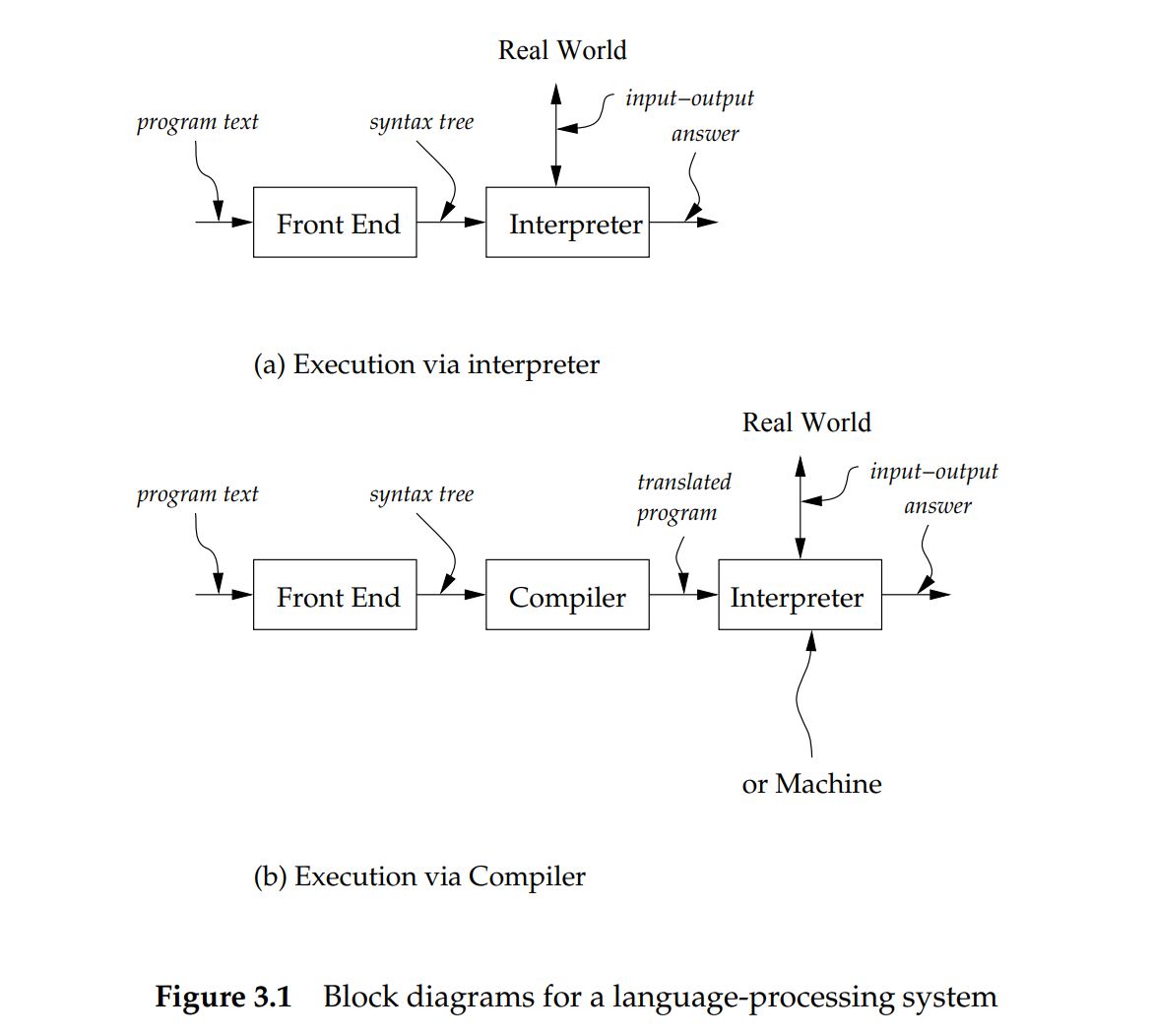
如果是编译器的话,语法树随后会传递给编译器生成目标代码,如果是解释器的话,语法树会传递给解释器执行。编译器(Compiler)一般分为两部分,用于分析程序中有用信息的分析器 analyzer ,和执行转换的翻译器 translator ,它可能会使用由分析器得到的信息。
在很久很久之前,也就是王垠还没有变成现在这样的时候,他写过这样一篇文章:对 parser 的误解。这里摘几段过来应该有助于读者了解什么是 Parser:
首先来科普一下。所谓 parser,一般是指把某种格式的文本(字符串)转换成某种数据结构的过程。最常见的 parser,是把程序文本转换成编译器内部的一种叫做“抽象语法树”(AST)的数据结构。
之所以需要做这种从字符串到数据结构的转换,是因为编译器是无法直接操作“1+2”这样的字符串的。实际上,代码的本质根本就不是字符串,它本来就是一个具有复杂拓扑的数据结构,就像电路一样。“1+2”这个字符串只是对这种数据结构的一种“编码”,就像 ZIP 或者 JPEG 只是对它们压缩的数据的编码一样。这种编码可以方便你把代码存到磁盘上,方便你用文本编辑器来修改它们,然而你必须知道,文本并不是代码本身。所以从磁盘读取了文本之后,你必须先“解码”,才能方便地操作代码的数据结构。
我喜欢把 parser 称为“万里长征的第0步”,因为等你 parse 完毕得到了 AST,真正的编译技术才算开始。一个编译器包含许多的步骤:语义分析,类型检查/推导,代码优化,机器代码生成,…… 这每个步骤都是在对某种中间数据结构(比如 AST)进行分析或者转化,它们完全不需要知道代码的字符串形式。也就是说,一旦代码通过了 parser,在后面的编译过程里,你就可以完全忘记 parser 的存在。所以 parser 对于编译器的地位,就像 ZIP 之于 JVM,就像 JPEG 之于PhotoShop。Parser 虽然必不可少,然而它比起编译器里面最重要的过程,是处于一种辅助性的地位。
在 Kent Dybvig 这样编译器大师的课程上,学生直接跳过 parser 的构造,开始学习最精华的语义转换和优化技术。实际上,Kent Dybvig 根本不认为 parser 算是编译器的一部分。因为 AST 数据结构才是程序本身,而程序的文本只是这种数据结构的一种编码形式。
你应该也注意到了在我上面的配图中前端和解释器/编译器是分开的,这张图来自 EOPL 3rd(Essentials of Programming Language),也许作者的观点和王垠提到的 Kent Dybvig 一样。不过也有另一种(也许是主流)观点认为前端只是解释器/编译器的一部分,至于哪种更好就随你喜欢了。
上面我们简单提了几嘴编译器的构成(分析器加翻译器),那么解释器的组成是什么样子的呢?最简单的可能是直接解释 AST,更高级一点的可能是将 AST 编译成字节码并执行。解释器的执行过程中也可能会存在编译过程,这么一看解释器和编译器之前的界限就比较模糊了。不过我们把握好两条规则就好:解释器 执行 代码,编译器 生成 代码,就算解释器中包含了编译功能,只要它最终还是在执行代码,那么它就是解释器。
编程语言似乎也不需要区分为解释型语言和编译型语言,我们当然可以为 C 写一个解释器。当我们将某种语言称为解释型语言或编译型语言时,我们指的应该是该语言的主流实现。
我们用一些链接来结束这一小节吧:
下面让我们写一个简单的 brainfuck 实现,网上已经有一些实现了,所以借鉴起来非常方便,比如下面列出的这些:
- emacs-brainfuck ,作者是 xuchunyang
- ebf,作者是 rexim
- bf.el,作者是 Mario Lang
如果你对我在上一节中介绍的 brainfuck 语言仍抱有疑惑,可以看看这一篇 racket 的 brainfuck 教程,非常不错。
为了与其他代码区分以及增强代码的趣味性,我使用了☉(SUN)字符作为这一系列函数的前缀(笑)。使用下面的代码可以把它绑定到你喜欢的按键上。
(global-set-key (kbd "C-\\") (lambda () (interactive) (self-insert-command 1 ?☉)))闲话少说,让我们开始吧。
参考上一节的解释器结构示意图,我们首先需要对源代码进行解析以得到抽象语法树,不过对于 brainfuck 这种几乎没有语法的语言这一部分代码非常简单,为它设一个二级标题我都觉得好笑。我们完全可以直接根据字符串执行,但这里我们还是做一些简单工作吧。
下面是 brainfuck 的 BNF 描述:
<brainfuck-program> := <brainfuck-command>*
<brainfuck-command> := '+' | '-' | ',' | '.' | '[' | ']' | '<' | '>'首先我们需要一个判断字符是否为八种基本指令之一的函数,在处理源代码时可以用它来去掉非指令的注释字符:
(defun ☉-charp (x)
(and (char-or-string-p x)
(memq x '(?> ?< ?+ ?- ?. ?, ?\[ ?\]))
t))使用下面的代码我们就可以得到 token 序列:
(defun ☉-tokenize (str)
(cl-loop for i across str
if (☉-charp i)
collect i))所谓 parsing 是要得到一种抽象的语法树结构(abstract syntax tree),这里的抽象是相对于具体的语法树的(也就是源代码),它去掉了一些不必要的细节,比如分隔符。但是对 brainfuck 这样简单的语言这一步是否是必须的呢?我们在 scanning 阶段就去掉了多余的注释字符,而且 brainfuck 的代码中是没有分隔字符的,所以我们直接将 tokenize 后的 token 序列传给下一阶段也是没问题的。
不过我们还可以添加一些错误检测功能,对 brainfuck 来说就是 [ 和 ] 数量是否匹配:
(defun ☉-parse (tos)
(let ((round-count 0))
(cl-loop for c in tos
do (cond
((= c ?\[) (cl-incf round-count))
((= c ?\]) (if (zerop round-count)
(error "unbalanced round bracket")
(cl-decf round-count)))))
(unless (zerop round-count)
(error "unbalanced round brakcet at end"))
tos))在 tokenize 的时候添加一些位置信息,我们还可以让错误提示更易读一些,将上面的函数合并我们就得到了 Parser 函数:
(defun ☉-charp (x)
(and (char-or-string-p x)
(memq x '(?> ?< ?+ ?- ?. ?, ?\[ ?\]))))
(defun ☉-token (s)
(let ((current-char-idx 1)
(current-line-idx 1))
(cl-loop for c across s
do (cond
((= c ?\n)
(setq current-char-idx 1)
(cl-incf current-line-idx))
(t
(cl-incf current-char-idx)))
if (☉-charp c)
collect (list c current-line-idx current-char-idx)
end)))
(defun ☉-parse (tos)
(let* ((round-cnt 0)
(errmsg1 "too many ] at line %s, col %s")
(errmsg2 "too many [")
(pas
(cl-loop for c on tos
do
(let* ((c0 (car c))
(ch (car c0))
(row (cadr c0))
(col (caddr c0)))
(cond
((= ch ?\[) (cl-incf round-cnt))
((= ch ?\]) (if (not (zerop round-cnt))
(cl-decf round-cnt)
(user-error errmsg1 row col)))))
collect (caar c)
finally do
(if (not (zerop round-cnt))
(user-error errmsg2)))))
pas))
(defun ☉-parser (str)
(☉-parse (☉-token str)))参考我上面给出的一些已有的 brainfuck 实现,这一部分的难度不大。应该说,这三个实现或多或少地都把 brainfuck 代码编译到了 elisp 来加速执行,不过我们首先从实现一个纯 brainfuck 解释器开始,也就是不对 AST 进行任何翻译。
因为涉及到指令指针的左右移动,光是使用单链表来表示指令序列就不太方便了,我们首先将其转换为下面的形式,新表的第一个元素是当前指令,第二个元素是当前位置到表头的链表,第三个元素是当前位置到表尾的链表:
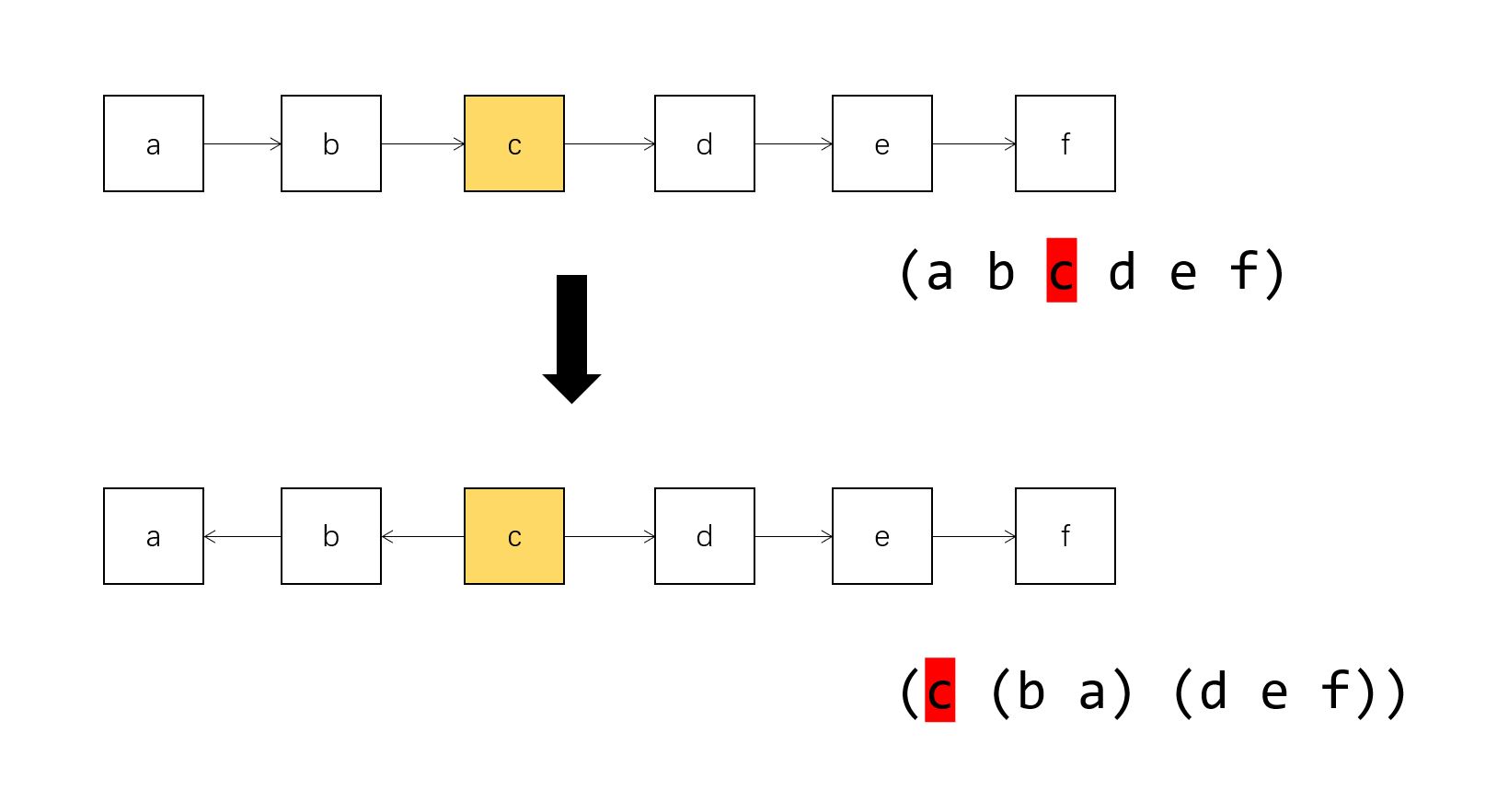
;; origin : a -> b -> c -> ... -> nil
;; ^ current place
;; new : nil <- a <- b -> c -> ... -> nil
;; ^ current place
(defun ☉-ast2link (ast)
(list (car ast) nil (cdr ast)))
(defun ☉-> (link)
(let ((a (car link))
(left (cadr link))
(right (caddr link)))
(cl-assert right)
(list (car right) (cons a left) (cdr right))))
(defun ☉-< (link)
(let ((a (car link))
(left (cadr link))
(right (caddr link)))
(cl-assert left)
(list (car left) (cdr left) (cons a right))))处理完了指令,现在可以为代码添加一个执行环境了。按 brainfuck 的要求,我们还需要一个数据数组,一个数据指针和一个指令指针。数据数组大小一般取 30000,数据指针就用变量记录偏移来实现,指令指针使用上面得到的双向表:
(defun ☉-interpreter (ast)
(let ((ir (☉-ast2link ast))
(ar 0)
(v (make-vector 30000 0)))
;;do something here
))
接下来就是对每个指令功能的实现了,左右移动数据指针 < 和 > 非常简单,只需要增加/减少 ar 的值,当然在执行这两个操作之前我们需要检查偏移值是否在数组下标范围内:
;; >
(cl-incf ar)
;; <
(cl-decf ar)
自增和自减 + - 的实现也类似,elisp 数组中单个元素作为数字使用的话可用范围有 -2^61 ~ 2^61-1,这个也需要进行检查:
;; +
(cl-incf (aref v ar))
;; -
(cl-decf (aref v ar))至于输入和输出,我们可以考虑使用 emacs 提供的 minibuffer 来进行,不过更方便的也许是给解释器一对 IO 函数,调用输入函数获取输入,调用输出函数进行输出:
(defun ☉-input ()
(read-char "brainfuck>"))
(defun ☉-output (c)
(write-char c))
;; .
(☉-output (aref v ar))
;; ,
(setf (aref v ar) (☉-input))
最后两个指令要稍微特殊一些,因为它们涉及到指令指针的跳转,要想让 ir 到达正确的地方需要处理好 [ 与 ] 的对应关系,在 parsing 阶段我们已经确保了 [] 是正确成对的,这里就不做过多检查了:
(defun ☉-next-br (link)
(cl-assert (= (car link) ?\[))
(let ((round-cnt 0)
(found nil)
(curr-link link))
(while (not found)
(cond
((and (= (car curr-link) ?\])
(= round-cnt 1))
(setq found t))
((= (car curr-link) ?\[)
(cl-incf round-cnt))
((= (car curr-link) ?\])
(cl-decf round-cnt)))
(unless found
(setq curr-link (☉-> curr-link))))
curr-link))
(defun ☉-prev-br (link)
(cl-assert (= (car link) ?\]))
(let ((round-cnt 0)
(found nil)
(curr-link link))
(while (not found)
(cond
((and (= (car curr-link) ?\[)
(= round-cnt 1))
(setq found t))
((= (car curr-link) ?\])
(cl-incf round-cnt))
((= (car curr-link) ?\[)
(cl-decf round-cnt)))
(unless found
(setq curr-link (☉-< curr-link))))
curr-link))
有了这些指令的实现,我们可以对 ☉-interprete 进行补完:
(defun ☉-interpreter (ast &optional i-fn o-fn len)
(setq i-fn (or i-fn '☉-input))
(setq o-fn (or o-fn '☉-output))
(setq len (or len 30000))
(let* ((ir (☉-ast2link ast))
(ar 0)
(v (make-vector len 0))
(vl (length v))
(exit (null ast)))
(while (not exit)
(cl-case (car ir)
((?+) (if (< (aref v ar) most-positive-fixnum)
(cl-incf (aref v ar))
(error "overflow most positive fixnum")))
((?-) (if (> (aref v ar) most-negative-fixnum)
(cl-decf (aref v ar))
(error "underflow most negative fixnum")))
((?>) (if (< ar vl) (cl-incf ar)
(error "overflow array index")))
((?<) (if (> ar 0) (cl-decf ar)
(error "underflow array index")))
((?.) (funcall o-fn (aref v ar)))
((?,) (setf (aref v ar) (funcall i-fn))))
(cl-case (car ir)
((?\[) (if (zerop (aref v ar))
(setq ir (☉-next-br ir))
(setq ir (☉-> ir))))
((?\]) (if (not (zerop (aref v ar)))
(setq ir (☉-prev-br ir))
(if (null (caddr ir))
(setq exit t)
(setq ir (☉-> ir)))))
(t
(if (null (caddr ir))
(setq exit t)
(setq ir (☉-> ir))))))
v))
(defun ☉-execute (str &optional ifn ofn len)
(☉-interpreter (☉-parser str) ifn ofn len))至此,我们就实现了一个最基本的 brainfuck 解释器,接下来我们用上面的 hello world 例子来测试一下:
(☉-execute "++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.")
=> Hello World!\n成功。完整的代码我放在了这里,想自己试试的同学可以直接下载。
上面实现的 brainfuck 解释器虽然能跑但是实现的很蠢。抛开其他不谈,最大的问题在对 [] 指令的处理上,当解释器遇到 [ 且需要进行跳转时,它会一个一个向后寻找 ] 而不是直接跳转过去,对 ] 也是一样。如果我们对代码中出现的每一个 [ 和 ] 都给出它对应 ] 或 [ 的位置,我们就可以直接跳转过去了。在本节开头列出的 bf.el 和 emacs-brainfuck 实现中, [] 结构都被转换成了 elisp 的 while 循环。
另一个比较小的优化是将多个连续的 + - 合并为一条数字运算指令,这样可以减少执行时间,对于连续的 < > 指令也是如此。
我会在讲到编译器部分时重新实现一个带编译的 brainfuck 解释器,它会将 brainfuck AST 编译为效率更高的 elisp 代码,而且生成的 elisp 代码可以利用 emacs 的 byte-compile 和 native-comp 功能来得到更快的执行速度。
既然现在已经有了 brainfuck 解释器,而且调用起来也比较简单( ☉-execute ),我们可以使用它来编写并测试一些简单的 brainfuck 代码,一来可以熟悉 brainfuck,二来可以测试解释器的正确性。brainfuck 难读难写,但这并不意味着它的代码就完全是无章可循。下面我参考网上的例子做一些总结,并给出一些常用的代码段。
这是一些与 brainfuck 相关的教程,感兴趣的同学可以看看:
前两个可以作为入门级教程,最后一个链接的内容最有价值,我下面的许多代码都参考了它的内容。
为了简单起见,下面出现的数字都是非负整数。
这一节也可以叫做基本操作,毕竟 brainfuck 中可以操作的也就只有内存了。
使用 [-] 我们可以清空某一内存块:
;; [-]
(☉-execute "+++[-]")
=> [0 0 0 ...]如果我们要将某一内存中的内容移动到另一内存,我们需要使用循环不断地自增自减两块内存:
;; [->+<] or [-<+>]
(☉-execute "+++[->+<]")
=> [0 3 0 0 0 ...]
(☉-execute ">+++[-<+>]")
=> [3 0 0 0 ...]
(☉-execute "+++[->+<]>[->+<]>[->+<]")
=> [0 0 0 3 0 0 ...]复制比移动稍微复杂一点,它还需要另外一块内存来保存原值,也就是一次性移动当前值到两块内存,随后将一块内存的值重新移回最初的位置:
;; [->+>+<<]>>[-<<+>>]
(☉-execute "++[->+>+<<]>>[-<<+>>]<<")
=> [2 2 0 0 ...]类似于 C 语言,如果要为 brainfuck 确定真假值的话,那么只有 0 是假值,其他的都是真值,想要对某一真值取反只能一步一步自减到 0。下面我们首先介绍一些分支运算。
最简单的分支是类似于 elisp 中的 when ,这只需要我们在使用 [] 执行完一些指令后,回到最初的内存块并将它清空:
;; [{do something}[-]]
(☉-execute "[++[-]]>+[>++<[-]]")
=> [0 0 2 0 ...]
稍微复杂一点的是 unless ,或者说是如何对当前值求逻辑反。首先我们可以使用 [>+<[-]] 将其标准化为 0 或 1,随后使用 1 减去它即可,该运算需要使用两个内存块:
;; NOT operation
;; [>+<[-]]+>[-<->]<
(☉-execute "[>+<[-]]+>[-<->]<")
=> [1 0 0 ...]
(☉-execute "+[>+<[-]]+>[-<->]<")
=> [0 0 0 ...]
;; unless operation
;; [>+<[-]]+>[-<->]<[{do something}[-]]
(☉-execute "[>+<[-]]+>[-<->]<[>++<[-]]")
=> [0 2 0 ...]
有了取反操作,我们就可以编写 if then else 了:
;; [>>+<<[-]]>+>[-<-<+>>]<<
;; require 3 memory unit
;; [0] -> [0][not 0]
(☉-execute "[>>+<<[-]]>+>[-<-<+>>]<<")
=> [0 1 0 ...]
;; [1] -> [1][not 1]
(☉-execute "+[>>+<<[-]]>+>[-<-<+>>]<<")
=> [1 0 0 ...]
;; [4] -> [1][not 4]
(☉-execute "++++[>>+<<[-]]>+>[-<-<+>>]<<")
=> [1 0 0 ...]
;; if then else
;; require 3 memory unit
;; [>>+<<[-]]>+>[-<-<+>>]<<[{then}[-]]>[{else}[-]]
;; if 1 then 2 else 3
(☉-execute "+[>>+<<[-]]>+>[-<-<+>>]<<[>>++<<[-]]>[>+++<[-]]")
=> [0 0 2 0 0 ...]
;; if 0 then 2 else 3
(☉-execute "[>>+<<[-]]>+>[-<-<+>>]<<[>>++<<[-]]>[>+++<[-]]")
=> [0 0 3 0 0 ...]
不过从这里我学到了另一种更简单的方法,上面我首先对逻辑值标准化和取反并放到了两个单元中,比如由 [2 ..] 得到 [1 0 ...] ,另一种做法是根据 then 是否执行来判断是否执行 else 语句。相比于我上面需要三个单元,这种方法只需要两个:
;; >+<[{then}[-]>-<]>[{else}-]<
;; if 1 then 2 else 3
(☉-execute "+>+<[>>++<<[-]>-<]>[>+++<-]<")
=> [0 0 2 ...]
;; if 0 then 2 else 3
(☉-execute ">+<[>>++<<[-]>-<]>[>+++<-]<")
=> [0 0 3 ...]接下来我们介绍一下常见的逻辑运算,比如 AND OR XOR。有了分支语句表达这些逻辑运算比较容易。
下面的与运算需要 5 个内存单元,使用了两层嵌套 if:
;; AND [A][B]
;; require 5 unit [A][B][][][] -> [res][0][0][0][0]
;; (move 2 to 3)>[->+<]<
;; (if 1) >+<[
;; (then 1)>> (if 2) >+<[
;; (then 2) >>+<< [-]>-<]>[
;; (else 2) -]<
;; << [-]>-<]>[
;; (else 1) >[-]< -]<
;; (move 5 to 1) >>>>[-<<<<+>>>>]<<<<
;; >[->+<]<>+<[>>>+<[>>+<<[-]>-<]>[-]<<<[-]>-<]>[>[-]<-]<>>>>[-<<<<+>>>>]<<<<
;; optimized:
;; >[->+<]+<[>>>+<[>>+<<[-]>-<]>[-]<<<[-]>-<]>[>[-]<-]>>>[-<<<<+>>>>]<<<<
(mapcar (lambda (x) (☉-execute (concat x ">[->+<]+<[>>>+<[>>+<<[-]>-<]>[-]<<<[-]>-<]>[>[-]<-]>>>[-<<<<+>>>>]<<<<")))
'("+>+<" "+" ">+<" ""))
=> ([1 0 0 ...]
[0 0 0 ...]
[0 0 0 ...]
[0 0 0 ...])与 AND 相似,OR 也使用二重嵌套 if ,但是它的顺序稍有不同:
;; OR [A][B]
;; require 5 unit [A][B][][][] -> [res][0][0][0][0]
;; (move 2 to 3)>[->+<]<
;; (if 1) >+<[
;; (then 1) >>>>+<<<< >>[-]<< [-]>-<]>[
;; (else 1) > (if 2) >+<[
;; (then 2) >>+<< [-]>-<]>[
;; (else 2) -]< < -]<
;; (move 5 to 1) >>>>[-<<<<+>>>>]<<<<
;; >[->+<]<>+<[>>>>+<<<<>>[-]<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]<>>>>[-<<<<+>>>>]<<<<
;; optimized
;; >[->+<]+<[>>>>+<<[-]<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]>>>[-<<<<+>>>>]<<<<
(mapcar (lambda (x) (☉-execute (concat x ">[->+<]+<[>>>>+<<[-]<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]>>>[-<<<<+>>>>]<<<<")))
'("" "+" ">+<" "+>+<"))
=> ([0 0 0 ...]
[1 0 0 ...]
[1 0 0 ...]
[1 0 0 ...])XOR 的实现如下,细节上的东西没必要做过多的描述了:
;; XOR [A][B]
;; require 5 unit [A][B][][][] -> [res][0][0][0][0]
;; (move 2 to 3)>[->+<]<
;; (if 1) >+<[
;; (then 1)>> (if 2) >+<[
;; (then 2) [-]>-<]>[
;; (else 2) >+< -]<
;; << [-]>-<]>[
;; (else 1) > (if 2) >+<[
;; (then 2) >>+<< [-]>-<]>[
;; (else 2) -]< <
;; -]<
;; (move 5 to 1) >>>>[-<<<<+>>>>]<<<<
;; >[->+<]<>+<[>>>+<[[-]>-<]>[>+<-]<<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]<>>>>[-<<<<+>>>>]<<<<
;; optimized
;; >[->+<]+<[>>>+<[[-]>-<]>[>+<-]<<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]>>>[-<<<<+>>>>]<<<<
(mapcar (lambda (x) (☉-execute (concat x ">[->+<]+<[>>>+<[[-]>-<]>[>+<-]<<<[-]>-<]>[>>+<[>>+<<[-]>-<]>[-]<<-]>>>[-<<<<+>>>>]<<<<")))
'("" "+" ">+<" "+>+<"))
=> ([0 0 0 ...]
[1 0 0 ...]
[1 0 0 ...]
[0 0 0 ...])这一节我们介绍一下一些基本的加减乘除,由于 brainfuck 中只有自增和自减,所以这些操作都会修改内存,除非我们复制原内容,否则它们都会被修改。
现在有紧挨在一起的两个数 A B,假设我们想要把 B(右边的)加到 A 上(左边的),我们可以这样做:
;; >[-<+>]<
(☉-execute "+++++>++++<>[-<+>]<") ;;5+4
=> [9 0 0 0 ...]上面那段代码的用处就是不断地自减右边元素并自增左边元素,直到右边变为 0 为止,与之相似,我们可以使用下面的代码实现减法:
;; >[-<->]<
(☉-execute "++++>+++<>[-<->]<") ;;4-3
=> [1 0 0 ...]
我们可以使用循环来用乘法表示某些数字,相比于直接写一长串的 + 可以节约些字数:
;; 20 = 4 * 5
;; >++++[-<+++++>]
(☉-execute ">++++[-<+++++>]")
=> [20 0 0 0 ...]
(☉-execute "++++++++++++++++++++")
=> [20 0 0 0 ...]
;; 64 = 4 * 4 * 4
;; >>++++[-<++++>]<[-<++++>]<
(☉-execute ">>++++[-<++++>]<[-<++++>]<")
=> [64 0 0 0 ...]
;; 114514 = 2 * 31 * 1847
;; 2 = ++; 31 = 32 - 1 = >>++++[-<++++>]<[-<++>]<-
;; 1847 = 1848 - 1 = 3 * 7 * 8 * 11 - 1
;; 1847 = >>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<-
(☉-execute "++>>>++++[-<++++>]<[-<++>]<->>>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<-")
=> [2 31 1847 ...]乘法相比于加减法要稍微复杂一点,因为它要进行多轮加法运算,运算过程中还要保留某一操作数的值,它执行时需要 4 个元素空间:
;;[a][b][0][0]
;;[->[->+>+<<]>[-<+>]<<]>[-]>>[-<<<+>>>]<<<
;; 2 * 3 = 6
(☉-execute "+++>++<[->[->+>+<<]>[-<+>]<<]>[-]>>[-<<<+>>>]<<<")
=> [6 0 0 ...]
;; 114514 = 2 * 31 * 1847
(defun ☉-114514 ()
(let ((t1 (float-time)))
(cons
(☉-execute "
++>>>++++[-<++++>]<[-<++>]<-< // {2 31}
[->[->+>+<<]>[-<+>]<<]>[-]>>[-<<<+>>>]<<< // {62}
>>>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<-< // {62 1847}
[->[->+>+<<]>[-<+>]<<]>[-]>>[-<<<+>>>]<<< // {114514}")
(- (float-time) t1))))
(☉-114514)
=> ([114514 0 0 0 0 0 0 0 0 0 0 0 ...] . 17.790914058685303)
;; byte compile the brainfuck interpreter
(☉-114514)
=> ([114514 0 0 0 0 0 0 0 0 0 0 0 ...] . 4.075918912887573)
;; native compile the brainfuck interpreter
;; native compile 对非 ascii 的支持好像有点小问题,所以做了点特殊处理
(defmacro nati-a (x)
(cons 'progn
(mapcar (lambda (x)
`(fset ',x (native-compile ',x)))
x)))
(nati-a (☉-charp ☉-token ☉-parse ☉-parser ☉-ast2link ☉-> ☉-< ☉-next-br ☉-prev-br ☉-interpreter ☉-execute))
(☉-114514)
=> ([114514 0 0 0 0 0 0 0 0 0 0 0 ...] . 3.5213661193847656)相比乘法,除法要更加复杂一些,它还需要考虑除不尽的情况,最终的结果应该是整除和余数值。这里已经有了一个现成的实现,不过我相信你没办法一眼看懂,所以我们还是先从高级语言开始实现。
现在,不允许用除法,我们使用 elisp 来实现一个整除函数:
(defun yydiv-1 (x y)
(let ((q 0)
(r 0))
(while (not (zerop x))
(if (>= x y)
(progn
(cl-incf q)
(cl-decf x y))
(cl-incf r x)
(cl-decf x x)))
(cons q r)))
(yydiv-1 4 2) => (2 . 0)
(yydiv-1 5 2) => (2 . 1)
(yydiv-1 114514 1847) => (62 . 0)接着,我们一次只允许加一或减一:
(defun yydiv-2 (x y)
(let ((q 0)
(r 0)
(tmp 0))
(while (not (zerop x))
(if (>= x y)
(progn
(cl-incf q)
(setq tmp y)
(while (not (zerop tmp))
(cl-decf x)
(cl-decf tmp)))
(while (> x 0)
(cl-decf x)
(cl-incf r))))
(cons q r)))
(yydiv-2 4 2) => (2 . 0)
(yydiv-2 5 2) => (2 . 1)
(yydiv-2 114514 1847) => (62 . 0)接着,我们不允许使用比较表达式(草),要实现的话又得加点新东西:
(defun yydiv-3 (x y)
(let ((q 0)
(r 0)
(tmp y)
(flag 0))
(while (not (zerop x))
(cl-decf x)
(cl-decf tmp)
(cl-incf r)
(cl-incf flag)
(unless (zerop tmp) (setq flag 0))
(when (not (zerop flag))
(setq tmp y)
(setq r 0)
(cl-incf q 1)
(setq flag 0)))
(cons q r)))
(yydiv-3 4 2) => (2 . 0)
(yydiv-3 5 2) => (2 . 1)
(yydiv-3 114514 1847) => (62 . 0)
最后,我们禁用掉复制赋值(也就是 (setq a b) 这种,赋常数还是允许的),写出我们的最后一版:
(defun yydiv-4 (x y)
(let ((q 0)
(r 0)
(flag 0))
(while (not (zerop x))
(cl-decf x)
(cl-decf y)
(cl-incf r)
(cl-incf flag)
(when (not (zerop y)) (cl-decf flag))
(when (not (zerop flag))
(while (not (zerop r))
(cl-decf r)
(cl-incf y))
(cl-incf q 1)
(cl-decf flag)))
(cons q r)))
(yydiv-4 4 2) => (2 . 0)
(yydiv-4 5 2) => (2 . 1)
(yydiv-4 114514 1847) => (62 . 0)
这样一来,我们使用 5 个内存单元实现了 brainfuck 整除法,上面的代码基本可以直接翻译为 brainfuck 代码了,但是我们还有一件事要做,那就是确定各变量在内存中的位置以尽量达到最短移动距离,尽量缩短代码的长度。上面链接给出的方法是将被除数放在第一个位置,将除数放在第五个位置,这里我选择的是类似的顺序,即 x, r, flag, y, q ,另外,由于不清楚 y 是否为 0 以及是否清除 flag,这里还需要一个多余的 0 来缓冲一下,所以最终的内存布局是 x, r, 0, flag, y, q :
;; (x r 0 flag y q)
;; [- (decf x)
;; >+ (incf r)
;; >>+ (incf flag)
;; >- (decf y)
;; [<-] (if y not zero decf flag)
;; <[ ;; 这一步很妙,如果此时在 y 上说明没有清除 flag,那么左移后 flag 非零进入括号
;; ;; 如果此时在 flag 上,那么左移后为 0 不进入循环
;; <<[->>>+<<<] (while (not zerop r) (decf r) (incf y))
;; >>>>+ (incf q)
;; <<- (decf flag)
;; <] ;; move to 0 the 3rd unit
;; <<] ;; go back to x
;; [->+>>+>-[<-]<[<<[->>>+<<<]>>>>+<<-<]<<]
;; optimized
;; [->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]
;; 添加初始位移代码,允许接收[x][y] 形式的输入,添加结束代码,将结果移动到开头
;; >[>>>+<<<-]< ;; 初始处理
;; >>>>[-]>[<<<<<+>>>>>-]<<<<< ;; 结尾处理
;; final
;; >[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<
(☉-execute "
+++>++<
>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<")
=> [1 1 0 0 ...]
(☉-execute "
++++++++++ ;;10
>++++< ;;4
>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<
")
=> [2 2 0 0 ...]
(☉-execute "
>>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<- ;;1847
>>>++++[-<++++>]<[-<++++>]<< ;;64
>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<")
=> [28 55 0 0 ...]最后的最后,我们要为我们的除法添加除零检查,否则会出现问题,我对除 0 的处理是当除数为 0 时直接返回原参数:
;; >[->+>+<<]>>[-<<+>>]<<>[[-]<< ;;判断除数是否为 0 ,正好利用一下单元中的 0
;;>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<< ;;除法运算
;; >>] ;; 结尾处理
;; >[->+>+<<]>>[-<<+>>]<<>[[-]<<>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<>>]
;; optimized
;; >[->+>+<<]>>[-<<+>>]<[[-]<[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<]
(☉-execute "
+++>++< ;; 3/2
>[->+>+<<]>>[-<<+>>]<[[-]<[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<]
")
=> [1 1 0 0 ...]
(☉-execute " 1847/64
>>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<- ;;1847
>>>++++[-<++++>]<[-<++++>]<< ;;64
>[->+>+<<]>>[-<<+>>]<[[-]<[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<]
")
=> [28 55 0 0 ...]
(☉-execute "
+++ ;; 3/0
>[->+>+<<]>>[-<<+>>]<[[-]<[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<]
")
=> [3 0 0 0 ...]关于输入和输出我不想花费过多的精力,这里咱们就介绍两个操作,读取数字和输出内存中的数字。首先我们从输出开始。
如果我们使用 Unicode 而不是 ASCII 输出函数的话输出数字就变得非常简单了,我们只需要输出 UNICODE 字符,然后交给宿主语言输出字符码字符串即可,不过这样做有点犯规,我们还是研究一下如何直接输出单元中的数字。
在上一节中我们已经知道了如何使用带余除法,这里我们可以使用它不断地对原数字除 10,直到得到的除数为 0 为止,随后我们反向逐个输出余数即可。既然使用的是 ASCII 码,在余数上加上 48(0 的 ASCII 码)即可。
这样来看,对于位数为 N 的数字,我们就需要 N + 5 个单元的内存,举个例子来说,我们计划输出 5 ,那么我们就需要布局为 5 0 0 0 10 0 (方便使用上面的除法操作的布局),结果得到 0 5 0 0 5 0 。现在我们可以将余数(左边的那个)5 左移到最左并清空其他。但是这样做有个后果,就是当数字不止一位时,我们不知道在哪里终止,所以最左的 0 我们需要保留,这样一来对于 N(N>1) 位数字我们就需要 N + 6 个内存单元。我们不考虑 N=1 的特殊情况专门为它编写代码,下面的代码使用的空间是 N+6(N>=1)。
最后,如果余数为 0 的话就与我们最左的终止 0 冲突了,所以计算完余数后我们给他加上 1,在输出时再加上 47 即可。
;; (A 0 0 0 ...)
;; [->+<] ;; 将数字右移一位
;; > [ ;; 当被除数不为 0
;; >>>>++++++++++<<<< ;; 除数 10
;; [->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<] ;; 算除法
;; >+[-<+>] ;; 余数加一后左移
;; >>>[-] 清空残余除数
;; >[-<<<<+>>>>]<<<< ;; 移动商到余数右
;; ] ;; 除法结束,现在得到的是 0 r1' r2' ,,,, rn' 0,数据指针位于最右的 0
;; <[>++++++[<++++++++>-]<-. 加上 47 并输出
;; [-]<] ;; 清空,并左移
;; [->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]
(☉-execute "
>>>+++++++++++[-<++++++++>]<[-<+++++++>]<[-<+++>]<- ;;1847
[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]
")
=> 输出 1847
=> [0 0 0 ...]
(☉-execute "
[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]")
=> 无输出
=> [0 0 0 ...]对于一般的数字上面的代码已经能够正常工作了,但是对 0 它会直接不执行第一个循环,所以就没有输出。我们还需要进行一些改进。比如加上 if else
;; [->+<] ;; 先右移被除数
;; + > ;; 首位先加 1,表示 else
;; [<-> ;; 被除数不为 0,去掉最左的 1
;; [->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<] ;; 正常运算
;; ] < ;;回到最左
;; [>++++++[<++++++++>-]<-.[-]] ;; 若最左不为 0,输出 0
;; [->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
(☉-execute "
+++
[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
")
=> 输出 3
=> [0 0 0 ...]
(☉-execute "
>>++++[-<++++>]<[-<++++>]<
[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
")
=> 输出 64
=> [0 0 0 ...]
(☉-execute "
[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
")
=> 输出 0
=> [0 0 0 ...]通过上面的一些代码相信你已经能够熟练地输出数字了,与输出的数字拆分相反,输入是个合并数字的过程,我们读入一串数字字符后,我们需要使用乘法将他们串起来。
既然涉及到读取,那我们要么指定读取字符个数,要么使用某个字符来表明输入终止。简单起见这里我使用数值 0 来表示输入终止,不过这样一来我们的输入函数得换,毕竟 read-char 没法在 minibuffer 中比较容易地读入 0(当然你也可以 C-q C-@ ,有点难按)。
;; require lexical-binding
(defun ☉-reader-gen (str)
(let ((idx 0)
(len (length str)))
(lambda ()
(if (>= idx len)
0
(prog1
(aref str idx)
(cl-incf idx))))))
(setq a (☉-reader-gen "123"))
(funcall a) => 49
(funcall a) => 50
(funcall a) => 51
(funcall a) => 0
(funcall a) => 0
...当我们读入一个数后,我们使用它减去 48 即得真实数值,在读入下一数后,我们将先前的数乘以 10 在加上后一数即可,这样循环直到读入数值 0。
;; (0 0 0 0)
;; 第一单元存储结果,第二单元读入,第三单元暂存中间操作数,第四单元暂存第一单元结果
;; >,[ ;; 初始读入,开始读取循环
;; >++++++[-<-------->] ;; 减去 48
;; +++++++++ ;; 第三单元设为 9,将第一单元的值加 9 次到第二单元
;; [-<<[->+>>+<<<] ;; 自减第一单元且自增第二第四单元
;; >>>[-<<<+>>>] ;; 将第四单元的数移回到第一单元
;; <] ;;回到第三单元,继续循环
;; <[-<+>] ;;来到第二单元,将它加到第一单元上,这就实现了 10*{1} 加 {2}
;; ,]< 继续读取,直到读到 0
;; >,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<
(☉-execute ">,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<"
(☉-reader-gen "1233"))
=> [1233 0 0 ...]
(☉-execute ">,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<"
(☉-reader-gen "114514"))
=> [114514 0 0 ...]
(☉-execute ">,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<"
(☉-reader-gen "0"))
=> [0 0 0 ...]写了这么多,我们可以简单地将上面的代码总结一下了。总结的格式大致如下:
- 名称,作用描述
- 代码
- 内存占用与执行前后内存状态描述
- 执行前后数据指针位置(如果有变动的话)
上面的一些 brainfuck 代码可能没有进行指针复位,这里正好做一个修正,同时我也会试着再做一些小优化,所以这里的代码不一定和上面的一致。
- RESET,将当前位置的内存块设为 0
[-]- [A] -> [0]
- MOV,将当前位置内存值移动当另一内存,要求另一内存块值为 0
[->+<]- [A][0] -> [0][A]
- COPY,将当前位置内存值复制到另一内存,要求其他内存块值为 0
[->+>+<<]>>[-<<+>>]<<- [A][0][0] -> [A][A][0]
- NOT,对当前内存值取反,得到标准逻辑值 0 或 1
[>+<[-]]+>[-<->]<- [A][0] -> [notA][0]
- WHEN,当前值为非零则执行指令
[{do}[-]]- [A] -> [0]
- 当内存值为标准逻辑值 0 或 1 时可简化为
[-{do}]
- UNLESS,当前值为零时执行指令
[>+<[-]]+>[-<->]<[-{do}]- [A][0] -> [0][?]
- IF,当前值为 0 执行 then,否则执行 else
>+<[{then}[-]>-<]>[-{else}]<- [A][0] -> [0][0]
- 若内存值为标准逻辑值,可简化为
>+<[->-<{then}]>[-{else}]<
- AND,两个内存块均为非零则得到 1,否则得到 0
[[-]>>+<<]+>[[-]>+<]++>[-<->]<[[-]<->]<- [A][B][0] -> [AandB][0][0]
- 相对之前的实现做了一些优化,短了一半
- OR,若两内存块中存在非零值则得到 1,否则得到 0
[[-]>>+<<]>[[-]>+<]>[[-]<<+>>]<<- [A][B][0] -> [AorB][0][0]
- 同样做了些优化,短了一半
- XOR,若两内存块中某一块为 0 且另一块为 1 则得到 1,否则得到 0
[[-]>>+<<]>[[-]<+>]<[>>[-<<->>]<<[->>+<<]]>>[-<<+>>]<<- [A][B][0] -> [AxorB][0][0]
- 优化,短了一小半
- ADD,将两内存块内容相加
>[-<+>]<- [A][B] -> [A+B][0]
- SUB,将两内存块相减
>[-<->]<- [A][B] -> [A-B][0]
- MUL,将两内存块相乘
[->[->+>+<<]>[-<+>]<<]>[-]>>[-<<<+>>>]<<<- [A][B][0][0] -> [A*B][0][0][0]
- DIV,将两内存块相除,得到商和余数
[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]- [A][0][0][0][B][0] -> [0][R][0][0][B'][Q]
- 添加位移处理
>[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<<<- [A][B][0][0][0][0] -> [Q][R][0][0][0][0]
- 添加判断除数是否为零
>[->+>+<<]>>[-<<+>>]<[[-]<[>>>+<<<-]<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>>>>[-]>[<<<<<+>>>>>-]<<<]<<- [A][B][0][0][0][0] -> [Q][R][0][0][0][0]
- [A][0][0][0][0][0] -> [A][0][0][0][0][0]
- READINT,读取整数
>,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<- [0][0][0][0] -> [A][0][0][0]
- WRITEINT,输出整数
[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]- [A][0][0][0][0][0][0]…. -> [0][0][0]…
- 共 N+6(N位整数)个内存单元
- 正确地处理 0 的输出
[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]- [A][0][0][0][0][0][0]…. -> [0][0][0] …
- 共 N+6(N位整数)个内存单元
我对上面的 brainfuck 代码都进行了测试,测试文件在 gist 上,测试结果如下(如果不使用 byte compile 的话可能有些慢,解释器实现的太垃圾了):
最后,让我们用 Fib(12) 结束 brainfuck 的学习吧:
;; n, b, a -> n-1, a+b, b
;; [0][0][0][0][0] -> [IN][1][0][0][0] -> [OUT][0][0][0][0] -> [0][0][0][0][0]... with output OUT
(☉-execute "
;; read n
>,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<
>+< ;; b = 1 a = 0 {0}
[- ;; if n gt 0 {0}
>[->>+>+<<<] ;; move b to 3rd and 4th cell {1}
>>>[-<<<+>>>]<<< ;; move 4th to b {1}
>[-<+>]< ;; b1 = a add b0 and a = 0 {1}
>>[-<+>]<< ;; a = b0 {1}
<] {0}
>[-]>[-<<+>>]<< ;;move a to cell 0 and clear b {0}
[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
;; output
" (☉-reader-gen "12"))
;;>,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]<>+<[->[->>+>+<<<]>>>[-<<<+>>>]<<<>[-<+>]<>>[-<+>]<<<]>[-]>[-<<+>>]<<[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
;; optimized
;; >,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]+<[->[->>+>+<<<]>>>[-<<<+>>>]<<[-<+>]>[-<+>]<<<]>[-]>[-<<+>>]<<[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]
(☉-execute "
>,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]+<[->[->>+>+<<<]>>>[-<<<+>>>]<<[-<+>]>[-<+>]<<<]>[-]>[-<<+>>]<<[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]" (☉-reader-gen "14"))
=> output 144
=> [0 0 0 ...]
(let ((ti (float-time)))
(☉-execute "
>,[>++++++[-<-------->]+++++++++[-<<[->+>>+<<<]>>>[-<<<+>>>]<]<[-<+>],]+<[->[->>+>+<<<]>>>[-<<<+>>>]<<[-<+>]>[-<+>]<<<]>[-]>[-<<+>>]<<[->+<]+>[<->[->+<]>[>>>>++++++++++<<<<[->+>>+>-[<-]<[->>+<<<<[->>>+<<<]>]<<]>+[-<+>]>>>[-]>[-<<<<+>>>>]<<<<]<[>++++++[<++++++++>-]<-.[-]<]]<[>++++++[<++++++++>-]<-.[-]]" (☉-reader-gen "20"))
(- (float-time) ti))
=> 6765
=> time 7.623257875442505现在,我们已经完成了这一系列的前一半,即实现并测试一个 brainfuck 解释器。这篇文章并没有完成,还有一半来介绍如何实现一个 brainfuck 编译器,并考虑将简化版的 elisp 或其他更简单的语言编译到 brainfuck。我会在下一篇文章中更加详细地介绍一些编译器和编译原理相关的知识,这篇文章算作对 brainfuck 的一个入门吧。
如你所见,上面的解释器可以正常工作但是慢的发指,下一篇文章中我们不会直接解释语法树,而是编译到更加高效的表达后再执行。
以下是暂时拟定的下一篇的各节标题:
- 什么是编译器
- 一个简单的 brainfuck 的编译器
- 将其他语言编译到 brainfuck
- 什么是 JSFuck
最后再对我上面的 brainfuck 解释器实现做一些说明,对 + 和 - 指令我没有实现环形计算,也就是说超过了最大整数或小于最小整数不会像补码运算那样变为最小负数和变为最大正数,而是直接报错。所以我在上面的 brainfuck 例子中没有实现整数相等判定,因为在这种实现下使用 [-] 可能不会回到 0,在之后的(编译)实现中我会注意这一点。
再推荐一个在线解释器,它是我在众多解释器中使用体验最好的:
本来我准备直接在本文中写完编译器的部分,不过一来现在我还没学过相关知识,二来现在以 UTF-8 计的文本大小已经快 50 KB 了,剩下的内容还是留到下一篇吧。
写完了这些 brainfuck 代码,我真的感觉自己的 brain 被 fuck 了一遍,我现在的体验估计就和三体中杨冬墓前的蚂蚁一样,这里再来段三体(笑),帮助读者们回忆一下:
下端的细槽与主槽垂直,上端的细槽则与主槽成一个角度相交。当褐蚁重新踏上蛸壁光滑的黑色表面后,它对槽的整体形状有了一个印象:“1”。
它不惜向下走回头路,沿着槽爬了一趟。这道槽的形状要复杂些,很弯曲,转了一个完整的圈后再向下延伸一段,让它想起在对气味信息的搜寻后终于找到了回家的路的过程,它在自己的神经网络中建立起了它的形状:“9”。
褐蚁继续沿着与地面平行的方向爬,进入了第三道沟槽,它是一个近似于直角的转弯,是这样的:“7”。它不喜欢这形状,平时,这种不平滑的、突然的转向,往往意味着危险和战斗。
孤峰上的褐蚁本来想转向向上攀登,但发现前面还有一道凹槽,同在“7”。之前爬过的那个它喜欢的形状“9”一模一样,它就再横行过去,爬了一遍这个“9”。它觉得这个形状比“7”和“1”好,好在哪里当然说不清,这是美感的原始单细胞态;刚才爬过“9”时的那种模糊的愉悦感再次加强了,这是幸福的原始单细胞态。但这两种精神的单细胞没有进化的机会,现在同一亿年前一样,同一亿年后也一样。
抱着再遇到一个“9”的愿望,褐蚁继续横行,但前面遇到的却是一道直直的与地面平行的横槽,好像是第一道槽横放了,但它比“1”长,两端没有小细槽,呈“一”状。孤峰上的褐蚁继续横向爬了不远,期望在爬过形状为“一”的凹槽后再找到一个它喜欢的“9”,但它遇到的是“2”。这条路线前面部分很舒适,但后面的急转弯像前面的“7”一样恐怖,似乎是个不祥之兆。褐蚁继续横爬,下一道凹槽是一个封闭的形状:“0”。这种路程是“9”的一部分,但却是一个陷阱:生活需要平滑,但也需要一个方向,不能总是回副起点,褐蚁是懂这个的。虽然前面还有两道凹槽,但它已失去了兴趣,转身向上攀登。
褐蚁向上爬了不远,才知道上方也有凹槽,而且是一堆凹槽的组合,结构像迷宫般复杂。褐蚁对形状是敏感的,它自信能够搞清这个形状,但为此要把前面爬过的那些形状都忘掉,因为它那小小的神经网络存贮量是有限的。它忘掉“9”。没有感到遗憾,不断地忘却是它生活的一部分,必须终身记住的东西不多,都被基因刻在被称做本能的那部分存贮区了。
清空记忆后,它进入迷宫,经过一阵曲折的爬行,它在自己简陋的意识中把这个形状建立起来:“墓”。再向上,又是一个凹槽的组合,但比前一个简单多了,不过为了探索它,褐蚁仍不得不清空记忆,忘掉“墓”。它首先爬进一道线条优美的槽,这形态让它想起了不久前发现的一只刚死的蝈蝈的肚子。它很快搞清了这个结构:“之”。以后向上的攀登路程中,又遇到两个凹槽组合。前一个中包括两个水滴状的坑和一个蝈蝈肚子——“冬”;最上面的一个分成两部分,组合起来是“杨”。这是褐蚁最后记住的一个形状,也是这段攀登旅程中唯一记住的一个,前面爬过的那些有趣的形状都忘掉了。
褐蚁继续攀登,进入了峭壁上的一个圆池,池内光滑的表面上有一个极其复杂的图像,它知道自己那小小的神经网络绝对无力存贮这样的东西,但了解了图像的大概形状后,它又有了对“9”的感觉,原细胞态的美感又萌动了一下。而且它还似乎认出了图像中的一部分,那是一双眼睛,它对眼睛多少有一些敏感,因为被眼睛注视就意味着危险。不过此时它没有什么忧虑,因为它知道这双眼睛没有生命。它已经忘记了那个叫罗辑的巨大的存在在第一次发出声音前蹲下来凝视孤峰上端的情形,当时他凝视的就是这双眼睛。接着,它爬出圆池,攀上峰顶。
在这里。它并没有一览众山小的感觉,因为它不怕从高处坠落,它曾多次被风从比这高得多的地方吹下去,但毫发无损,没有了对高处的恐惧就体会不到高处之美。
在孤峰脚下,郡只被罗辑用花柄拂落的蜘蛛开始重建蛛网,它从峭壁上拉出一根晶莹的丝,把自己像钟摆似的甩到地面上。这样做了三次,网的骨架就完成了。网被破坏一万次它就重建一万次,对这过程它没有厌烦和绝望,也没有乐趣,一亿年来一直如此。
罗辑静立了一会儿,也走了。当地面的震动消失后,褐蚁从孤峰的另一边向下爬去,它要赶回蚁穴报告那只死甲虫的位置。天空中的星星密了起来,在孤峰的脚下,褐蚁又与蜘蛛交错而过,它们再次感觉到了对方的存在,但仍然没有交流。
褐蚁和蜘蛛不知道,在宇宙文明公理诞生的时候,除了那个屏息聆听的遥远的世界,仅就地球生命而言,它们是仅有的见证者。
使用不同的语言就会有不同的思维方式,低级语言真的是能够限制思想和表达的。我想我现在算是能够理解为什么在欧洲十六十七世纪的时候不承认负数的存在了,要想发明一个先前不存在的概念并不容易。如果使用 brainfuck 样的编程语言的话,你也不太想用负数。
以上,去学学编译器。