symbol 类型算是 Lisp 系语言的一大特征。Javascript 在 ES6 标准中引入了 symbol,既然都有 symbol 了那就是一种 Lisp(大雾)。现在几乎所有的浏览器都已经支持了 ES6 标准,而且 JS 的 symbol 和 Lisp symbol 也有相似之处,考虑到浏览器自带控制台,这里和我一起按下 F12 用 JS 来体验一下 symbol 吧。
symbol 是 JS 的基本类型之一,可以通过内置对象 Symbol 来进行创建,它会返回一个不重样的 symbol 值,也就是说任意一次对 Symbol 的调用都会返回一个与任意其他 symbol 不同的值。在浏览器控制台中输入 Symbol()===Symbol() 并运行,得到的永远是 false 。
当然,除了创建这种不重样的 symbol,我们也可以创建全局注册的 symbol,通过使用 Symbol.for() 来创建。对于某一字符串,该函数总是返回同一 symbol,比如 Symbol.for("abc")===Symbol.for("abc") 。使用 String.keyFor() 可以从全局 symbol 中获取字符串的值,比如 Symbol.keyFor(Symbol.for("yy")) 会得到字符串 "yy" 。通过 Symbol.for 和 Symbol.keyFor 我们可以在字符串和全局 symbol 之间找到对应关系。
对于普通 symbol 可直接使用 String 或 toString 方法获得 symbol 对应的字符串,不过它和创建过程中输入的字符串就没太大关系了,传递给 Symbol() 的字符串参数仅仅起注释作用而已。
a = Symbol()
b = String(a)
c = Symbol('hello')
d = c.toString()
console.log(b)
console.log(d)
=>
'Symbol()'
'Symbol(hello)'
由上面的代码你也应该看出了在 JS 中是没有 symbol 字面量的,而且 symbol 并非值类型而是引用类型。symbol 中除了有 Symbol 创建的普通 symbol 还有 Symbol.for 创建的全局 symbol。关于 JS symbol 类型这里有篇不错的介绍文章,本文就不进一步展开了。
在 Lisp 语言中我们会使用 intern 来创建或引用全局 symbol,使用 make-symbol 或 gensym 来创建普通 symbol。下面让我们正式开始本文的主要内容吧。
就像 JS 里的 symbol 是引用类型一样,elisp 中的 symbol 值其实就是指针(在 elisp 里除了 fixnum 是值其他类型都是指针…,是的, t 和 nil 也是 symbol),一般使用时只需要给名字前面加上 quote 即可,非常方便。类似于 'a , 'hello , 'yy 的表达式就是 elisp 中的 symbol 字面量,它们会各自指向对应的全局 symbol。
JS 中提供了 typeof 来获取对象的类型信息,对 symbol 它会返回字符串 'symbol' 。elisp 中的 type-of 会返回类型名的 symbol,比如 (type-of 'a) -> 'symbol 。在 elisp 中除了 type-of 外还可以使用 symbolp 来判断对象是否为 symbol:
(symbolp 't) => t
(symbolp 'nil) => t
(symbolp t) => t
(symbolp nil) => t
(type-of 'a) => symbol
(type-of t) => symbol
(type-of nil) => symbol既然都是对象了,那肯定不是一个简单值。在 elisp 中,symbol 由四部分组成:
- print value ,symbol 的名字
- value ,symbol 中保存的值,这一部分也叫 value cell
- function ,symbol 中保存的函数,这一部分也叫 function cell
- property list ,保存属性的表,也叫 plist
与 JS 中的那个残废不同,symbol 是 elisp 的核心组成部分。通过 symbol-name 用户可以获取 symbol 名字的字符串;symbol 可用作变量名和函数名,它们的值分别存储在 symbol 的 value cell 和 function cell 中。我们可以使用 symbol-value 和 symbol-function 来进行访问:
(defun a (x) (+ x 1))
(setq a 1)
(symbol-function 'a) => (lambda (x) (+ x 1))
(symbol-value 'a) => 1
(a a) => 2
(funcall (symbol-function 'a) (symbol-value 'a)) => 2
在所有 symbol 里 t 和 nil 比较特殊,它们的 value cell 分别是 t 和 nil ,而且不允许更改。换句话说它们的 value cell 是指向自身的常量:
(symbol-value t) => t
(symbol-value nil) => nil
(and (eq t 't) (eq 'nil nil)) => t
(let ((t nil))
(and nil t))
=>
;;Debugger entered--Lisp error: (setting-constant t)
;;(let ((t nil)) (and nil t))
(let ((nil t))
(and nil t))
=>
;;Debugger entered--Lisp error: (setting-constant nil)
;;(let ((nil t)) (and nil t))
与之类似的还有 keyword symbol,它们以 : 开头,和 t , nil 一样是自求值的,而且也不允许修改 value cell 。可以使用 keywordp 判断对象是否为关键字 symbol。一般来说 keyword 用于 cl-defun 等宏中定义关键字参数。
:a => :a
(symbol-value :a) => :a
(keywordp :a) => t
(keywordp 1) => nil
(let ((:a 1))
(+ :a 1))
=>
Debugger entered--Lisp error: (setting-constant :a)
(let ((:a 1)) (+ :a 1))
symbol 的最后一个组成部分是 plist ,它是与 symbol 关联的属性表,表的格式必须是是 (p1 v1 p2 v2 ...) ,elisp 提供了操控 plist 的一系列函数,我们将在后文进行介绍。
CL(common lisp)中的 symbol 与 elisp 相似,不过它要多一个 package 成员,在 ANSI Common Lisp 上有张图可以说明 CL 中 symbol 的结构:

本文主要分析的是 elisp 中的 symbol,对 CL 不会过多提及,但在必要的时候还是会做一些说明。
所谓 binding 就是变量与值之间的关联。这一节我尝试收集一下常见的创建 binding 的函数或宏或 special-form。
elisp 的 symbol 有 value cell 和 function cell ,所以 binding 的创建要对这两个成员分开讨论。我们先从 value cell 开始。
最直截了当的应该是 setq ,它将一个值赋给 symbol 的 value cell 。与之对应的还有一个函数 set ,它俩的用法如下:
(setq a 1) => 1
a => 1
(set 'a 2) => 2
a => 2
cl-lib 提供了一些更强的宏,比如 cl-psetq (也可以直接写 psetq ),它提供同时而非顺序进行的赋值操作:
(defun fib-psetq (n)
(let ((a 0)
(b 1))
(while (> n 0)
(cl-psetq a b
b (+ a b))
(cl-decf n))
a))
(fib-psetq 5) => 5除了这种修改 value cell 的函数,elisp 还提供了一些临时 binding 功能,这里简单列举一下:
let,let*和letrec,非常经典的三个宏(special form?)
(let ((a 1)
(b 2))
(+ a b))
=>
3
(let* ((a 1)
(b (1+ a)))
(+ a b))
=>
3
(letrec ((a (lambda (x) (1+ (funcall b x))))
(b (lambda (x) (+ x 1))))
(cons (funcall a 1)
(funcall b 1)))
=>
(3 . 2)dlet,创建动态 binding,不论当前的lexical-binding是t或nil都是动态的
(defun a (x) (+ x b))
(setq b 2)
(a 1) => 3
(dlet ((b 3))
(a 1))
=> 4cl-prog系列,包括cl-prog,cl-prog*和cl-progvcl-prog和cl-prog*类似于let和let*,但是支持使用 CL 中的block和tagbody,cl-prov与两者类似,但使用动态绑定tagbody的用法可以参考 http://clhs.lisp.se/Body/s_tagbod.htm
(cl-prog
((a 1)
(b 2))
loop1
(when (> b 0)
(cl-incf a)
(cl-decf b)
(go loop1))
(cl-return a))
=> 3
(cl-progv
'(a b c)
'(1 2 3)
(+ a b c))
=> 6
最后再说一下 defvar , defconst 和 makunbound 。一般来说 defvar 和 defconst 用来定义全局变量,它们的具体行为可以参考 elisp 文档。若在 lambda 表达式外,经过 defvar 定义的变量将永远是动态作用域。 makunbound 可以清除 symbol 的 value cell 使其成为空指针:
(setq a 1) => 1
a => 1
(makunbound 'a) => a
a
=>
;;Debugger entered--Lisp error: (void-variable a)
;;elisp--eval-last-sexp(nil)
和 set 类似,对于函数也有 fset ,不过没有 fsetq :
(fset 'a (lambda (x) (+ x 1)))
(a 1) => 2相比 value cell , function cell 就没有那么多的花样了。一般 symbol 的 function cell 用于全局函数的 binding,不过这也不是说没有创建临时 binding 的方法。
flet 类似于 let 可以创建函数 binding,不过该宏已经在 24.3 被废置了,建议使用 cl-lef 或 cl-flet 或 cl-flet* 。除了类似 let 的宏,还有类似 letrec 可以互引用的宏,即 cl-labels 。
(cl-flet ((a '1+)
(b (x) (+ x 2)))
(+ (a 1) (b 2)))
=> 6
(cl-flet* ((a '1+)
(b (x) (+ 1 (a x))))
(b 1))
=> 3
(cl-labels ((yoddp (x) (if (zerop x) nil (yevenp (1- x))))
(yevenp (x) (if (zerop x) t (yoddp (1- x)))))
(and (yoddp 15)
(yevenp 16)))
=> t
需要说明的是,它们并没有真正的“修改”变量的 function cell ,具体原因使用 macroexpand 展开表达式可知。真正对其进行了修改的是 letf ,它可以用来创建动态作用域的 binding。
这里提一下 named-let ,它和 Scheme 里的 named let 挺像,估计就是抄过来的罢(笑),不过没有尾递归优化还是不太敢用尾递归表示循环。
(2023-02-10,重新看了下 named-let 的实现,确实做了尾递归优化)
(named-let factor ((n 5) (res 1))
(if (> n 0)
(factor (1- n) (* res n))
res))
=> 120
最后就是一些标准函数/宏定义表达式了,比如 defun , defmacro 等等,这里简单介绍一下 defalias , defun 和 defmacro 会在内部调用它。
(defalias 'a (lambda (x) (+ x 1)))
(a 1) => 2
与 makunbound 相似, function cell 也有 fmakunbound 来将其赋空,不过 function cell 的空值是 nil 而非 void :
(defun a (x) (+ x 1))
(a 1) => 2
(fmakunbound 'a)
(a 1) =>
Debugger entered--Lisp error: (void-function a)
(symbol-function 'a) => nilplist 的用法可以参考使用它的代码(这话说了好像等于没说),在我的印象里 plist 可以用来保存一些与 symbol 相关的上下文信息。我也没有太多的使用经验,这里就介绍一些和它相关的函数吧。
首先是 symbol-plist ,可以用来获取 symbol 的 plist,它会直接返回 symbol 的 plist 成员而非副本:
(symbol-plist 'car) =>
(byte-compile byte-compile-one-arg byte-opcode byte-car gv-expander #[385 "\300\301\302^D^D$\207" [gv--defsetter car #[385 "\300\301^B^DC\"B\207" [setcar append] 6 "
(fn VAL &rest ARGS)"]] 7 "
(fn DO &rest ARGS)"] side-effect-free t pure t)
(eq (symbol-plist 'car) (symbol-plist 'car)) => t
可以看到 (symbol-plist 'car) 返回了一长串,其中的一些可能和字节编译有关。
setplist 可以将某一 plist 赋给 symbol 的 plist 成员:
(symbol-plist 'foo) => nil
(setplist 'foo '(a 1 b 2)) => (a 1 b 2)
(symbol-plist 'foo) => (a 1 b 2)
plist-get 和 plist-put ,前者在 plist 中查找属性并返回属性值,后者将新的属性名和属性添加到 plist 中。若待添加的属性在表中存在且新属性值与原值不同, plist-put 会修改表中内容;若新属性不存在于表中,它也会修改原表并返回。不管是否修改原表都建议覆盖原变量值:
(plist-get '(a 1 b 2 c nil) 'a) => 1
(plist-get '(a 1 b 2 c nil) 'c) => nil
(plist-get '(a 1 b 2 c nil) 'd) => nil
(setq a '(a 1 b 2 c nil))
(eq (plist-put a 'a 1) a) => t
(plist-put a 'd 1) => (a 1 b 2 c nil d 1)
a => (a 1 b 2 c nil d 1)
(setq a (plist-put a 'c 1)) => (a 1 b 2 c 1 d 1)
除了这两个函数外 elisp 还提供了 lax-plist-get 和 lax-plist-put ,它们使用 equal 而非 eq 来判断属性名是否相同。
除 plist-get 外还可使用 plist-member 获取 plist 中的属性值,当属性值为 nil 时它能识别而不是像 plist-get 那样无法判断属性名是否存在:
(setq a '(a 1 b 2 c nil))
(plist-member a 'c) => (c nil)
(plist-member a 'd) => nil
put 与 get 和 plist-put , plist-get 类似,不过它们直接接受 symbol 并对 symbol 的 plist 进行操作。还有两个叫做 function-get 和 function-put 的函数,如果在当前符号找不到属性,它们会使用真正函数的 plist,具体例子如下:
(setplist 'foo (list 'a 1 'b 2))
(symbol-plist 'foo) => (a 1 b 2)
(get 'foo 'a) => 1
(get 'foo 'b) => 2
(put 'foo 'c 3) => 3
(symbol-plist 'foo) => (a 1 b 2 c 3)
(put 'bar 'd 4)
(fset 'foo 'bar)
(function-get 'foo 'a) => 1
(function-get 'foo 'b) => 2
(function-get 'foo 'c) => 3
(function-get 'foo 'd) => 4
需要说明的是,当前 emacs(28.1)中的 function-put 实现就是简单的 put,所以上面我没有举例。
最后再介绍一下 cl-lib 中的几个 plist 函数,读者可以阅读 cl-lib 源代码学习使用方法:
(cl-get SYMBOL PROPNAME &optional DEFAULT),返回 SYMBOL 的 PROPNAME 属性值,若不存在则返回 DEFAULT(cl-getf PLIST PROPNAME &optional DEFAULT),在 PLIST 中搜索 PROPNAME,找到了就返回对应属性值,否则返回 DEFAULT(cl-remprop SYMBOL PROPNAME),除去 SYMBOL 的 plist 中的属性 PROPNAME 和它的值(cl-remf PLACE TAG),从 PLACE 所在的 plist 中除去属性 TAG(cl-remf (symbol-plist symbol) TAG)作用和(cl-remprop symbol TAG)相同
就像 C 语言一样,elisp 没有类似于 racket 或 python 的 module 功能,所有名字都是全局可见的。什么 import , from <sth> import <sth2> 和 import pkg as p 统统没有。这样一方面增加了名字冲突的可能性,需要给包中的函数和变量加上前缀名字,另一方面也让调试轻松了很多,可以直接通过全局名字找到包的内部变量,不存在私有变量或函数无法访问的问题。module 是好是坏仁者见仁智者见智吧,这里有个讨论:elisp没有模块化是不是个致命的缺陷。
在 elisp 中对包中名字的命名有个约定(convention),这里简单列几条:
- 选择一个短小的名字作为包中所有名字的前缀,并将它与名字剩余部分用
-隔开,这样可以避免名字冲突。对于包内部使用的名字,使用两个-分隔包名和具体名字 - 方便起见也可以把包名放在具体名后面,比如
list-yy,这里yy就是包名,还比如define-yy - 如果一个名字还不够,可以多加几个,比如
yy-eat-food-killbuffer - 谓词函数建议使用
p或-p结尾,比如zerop,yy-listp等 - 如果变量用来存储函数,可以加上
-function后缀
shorthands 是 emacs 28 中引入的新特性,使用它可以给文件中的名字自动加上想要的前缀,这样就不用我们自己写了。它的实现原理就是 hack read 函数,在读取时做一些特殊处理。
通过设置 read-symbol-shorthands 这个 file-local 变量,我们就能在读取 el 文件时使用 shorthands 完成前缀的替换,下面是个简单的例子:
(defun t-add (x y) (+ x y))
(defun t-sub (x y) (- x y))
;; Local Variables:
;; read-symbol-shorthands: (("t-" . "yyfun-"))
;; End:
将上面的代码放入某文件中,关闭文件重新打开并使用 eval-buffer 求值后,你就可以调用这两个函数了,不过它们的名字并不是 t-add 和 t-sub ,而是 yyfun-add 和 yyfun-sub , shorthands 对它们进行了替换。
这样带来的好处是显而易见的,写包的时候没有必要写又臭又长的前缀名了。但它同时也带来一个问题,既然源代码中不存在实际的名字,跳转到定义要怎么处理。就我个人体验来看这不是个问题,使用 M-. (xref-find-definitions)是能够找到定义的,而且定义的前缀名被高亮了(感觉有点刺眼…):
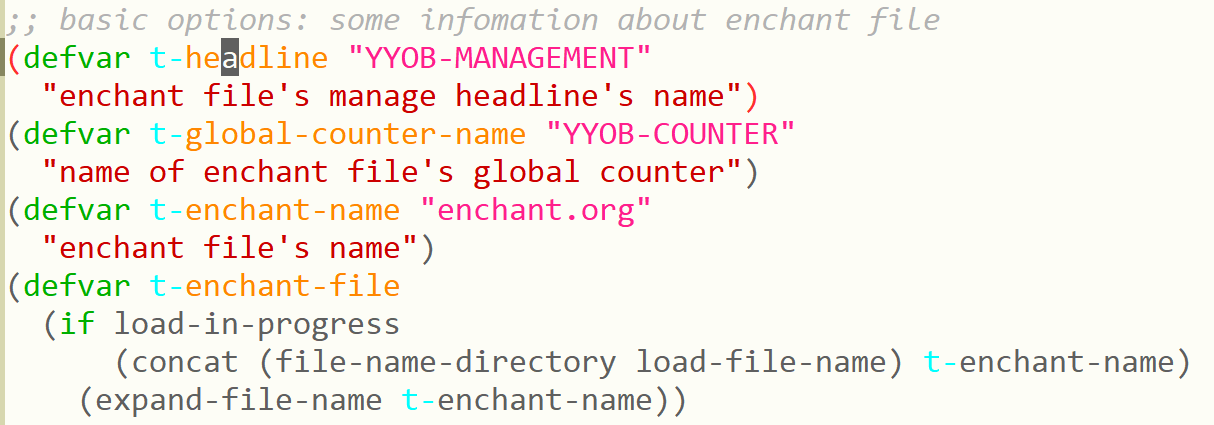
除了导出时可以使用 shorthands ,在调用其他包时我们也可以使用它,这时的作用就有点像 python 中的 import as 了:
(defun t-mul (x y)
(let ((x0 x))
(while (> y 0)
(setq x (i-add x x0))
(setq y (i-sub y 1)))
x))
(defun t-div (x y)
(if (> y x)
0
(i-add 1 (t-div (- x y) y))))
;; Local Variables:
;; read-symbol-shorthands: (("t-" . "yyexp-")
;; ("i-" . "yyfun-"))
;; End:
这样,我们就使用 yyfun-add 和 yyfun-sub 定义出了 yyexp-mul 和 yyexp-div 。
注意,当你将上面的两段代码放入不同文件并保存后,如果想要触发 shorthands 功能需要重新打开文件或使用命令 revert-buffer ,这样可以让 emacs 读入这个 file-local 变量。最后得到的效果如下:
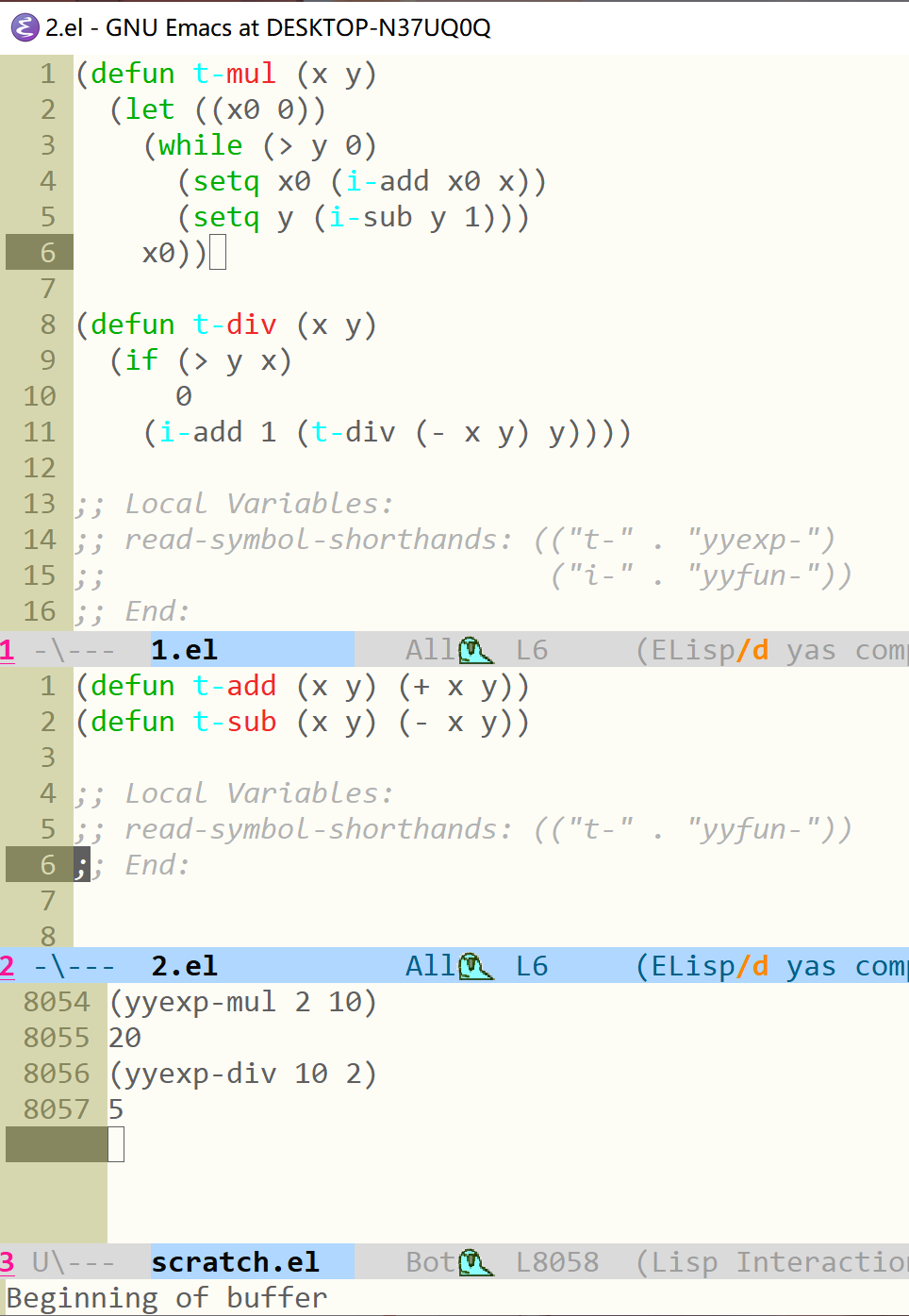
elisp 中的 shorthands 应该算不上一种完整的模块管理机制,毕竟本质上还是通过添加前缀来避免名字冲突,不过用起来感觉没啥问题。
在 elisp manual 中这是 Symbol 标题下的一个小节,不过我认为有必要把它单独拿出来给个一级标题,这是理解 symbol 最核心的知识。我们在文章开头已经提到,elisp 使用 intern 创建 或 引用 注册 symbol,使用 make-symbol 或 gensym 创建 非注册符号。下面我们举点简单例子来说明一下。
在开始之前我得确保你明白读取(raed)和求值(eval)的区别。在本文中,读取指的是读入字符串并转化为 list,求值指的是对 list 求值而不是对 sexp 字符串求值。不过我这里对求值的定义太窄了,求值也可以指从字符串到结果的过程。为了方便下面我会仔细区分 读取 和 求值 。
我们都知道 elisp 代码是由 sexp 构成的,sexp 包括表和原子(当然也有既是原子也是表的 nil),sexp 中出现的非值原子就是变量或者函数的名字,在读取后会成为 symbol 对象的 指针 。这里有一个显而易见的事实:正常情况下同名非值原子需要指向同一 symbol 对象,否则会出现一些奇怪的结果。我们先使用 quasiquote 写一段这样的代码,然后观察求值结果:
(setq a `(let ((,(make-symbol "yy1") 1)
(,(make-symbol "yy2") 2))
(+ ,(make-symbol "yy1") ,(make-symbol "yy2"))))
(print a) => (let ((yy1 1) (yy2 2)) (+ yy1 yy2))
(let ((yy1 1) (yy2 2)) (+ yy1 yy2)) => 3
(eval a) =>
;;Debugger entered--Lisp error: (void-variable yy1)
;;(+ yy1 yy2)
;;(let ((yy1 1) (yy2 2)) (+ yy1 yy2))
;;eval((let ((yy1 1) (yy2 2)) (+ yy1 yy2)))
在上面的代码中,由于 make-symbol 每次调用都创建了新的 symbol, let 绑定的 yy1 和 yy2 与 (+ yy1 yy2) 中的符号并不一致,故无法正确求值。不过你可能会觉得奇怪,对上面的 打印结果 求值是没有问题的,但是 直接 对变量中的 list 求值却出现了问题,这是因为 elisp 默认的 print 方法是只输出最简形式,在对输出结果进行读取求值时其中的符号在读入时默认为全局符号。通过修改 print-gensym 的值,我们可以得到正确的结果:
(setq print-gensym t)
(setq a `(let ((,(make-symbol "yy1") 1)
(,(make-symbol "yy2") 2))
(+ ,(make-symbol "yy1") ,(make-symbol "yy2"))))
(print a) => (let ((#:yy1 1) (#:yy2 2)) (+ #:yy1 #:yy2))
#: 记号表明 elisp 在读入时会将符号标记为 uninterned,也就是非全局 symbol,这样生成的 symbol 是无法直接引用的,所以代码无法正常求值。使用全局符号的话,上面的代码就可以正常求值了:
(setq print-gensym t)
(setq a `(let ((,(intern "yy1") 1)
(,(intern "yy2") 2))
(+ ,(intern "yy1") ,(intern "yy2"))))
(print a) => (let ((yy1 1) (yy2 2)) (+ yy1 yy2))
(eval a) => 3这并不是说我们必须使用全局符号才能让代码正常求值,我们只需要让 list 中的符号指向同一 symbol 对象即可:
(setq print-gensym t)
(setq print-circle nil)
(setq a (let ((a (make-symbol "yy1"))
(b (make-symbol "yy2")))
`(let ((,a 1)
(,b 2))
(+ ,a ,b))))
(print a) => (let ((#:yy1 1) (#:yy2 2)) (+ #:yy1 #:yy2))
(eval a) => 3
(let ((#:yy1 1) (#:yy2 2)) (+ #:yy1 #:yy2)) =>
;;Debugger entered--Lisp error: (void-variable yy1)
;;(+ yy1 yy2)
;;(let ((yy1 1) (yy2 2)) (+ yy1 yy2))
上面的 (eval a) 得到了正确的结果,但是对它的打印代码求值却出现了错误,这是因为读取时 #: 总是创建新的符号, (eq '#:x '#:x) 得到的总是 nil。为了得到正确的结果我们还需要将 print-circle 设为 t :
(setq print-gensym t)
(setq print-circle t)
(setq a (let ((a (make-symbol "yy1"))
(b (make-symbol "yy2")))
`(let ((,a 1)
(,b 2))
(+ ,a ,b))))
(print a) => (let ((#1=#:yy1 1) (#2=#:yy2 2)) (+ #1# #2#))
(eval a) => 3
(let ((#1=#:yy1 1) (#2=#:yy2 2)) (+ #1# #2#)) => 3
上面出现的 #N 和 #: 一样是一种特殊的 read syntax,用来表示给对象一个名字以便在随后的表达式中使用名字引用来使得它们指向同一对象。使用例如下:
(setq a '(#1=(a) b #1#))
(eq (car a) (caddr a)) => t
(setq a '#1=(a . #1#))
(eq a (cdddr a)) => t
至此,相信你应该明白了 make-symbol 和 intern 的基本作用。前者会创建一个非注册 symbol,就像 JS 里的 Symbol 一样,它俩的字符串参数也许仅仅起到注释作用。 intern 和 Symbol.for 都会创建全局注册 symbol,同名 symbol 会指向同一对象。
还有个函数忘了说, gensym 也会创建 uninterned symbol,它会在内部调用 make-symbol ,然后返回一个名字序号不断增长的 symbol,就像这样:
(setq print-gensym t)
(gensym) => #:g102
(setq print-gensym nil)
(gensym) => g103
elisp manual 中建议在宏中使用它而不是 make-symbol 来生成 uninterned symbol。
下面我们来介绍一些实现细节。主要是在代码字符串的读取处理和全局 symbol 的存储与查找这两方面展开。
上一小节我强调过 read 和 eval 的区别,这一节我们来对 reader 的行为做一点简单的说明,讲讲它是如何处理 symbol 的。
当 reader 遇到一个 name 字符串时,它会在一个全局表(obarray,具体见下一节)中查找这个名字,如果找到了,那么 reader 会使用这个 symbol 值。如果全局表不包含该名字的 symbol, reader 会创建一个新的 symbol 并添加到 obarray 中。这个查找 obarray 或添加 symbol 到 obarray 的过程叫做 interning ,这样的 symbol 被叫做 interned symbol 。 interning 确保了 reader 对同样的字符串总能得到同样的 symbol。
并不是所有的 symbol 都是 interned symbol ,没有 intern 的 symbol 被叫做 uninterned symbol ,它们主要用在宏上。
(eq (read "a") (read "a")) => t
(symbolp (read "a")) => t
当然, reader 在使用 shorthands 时会做一些特殊处理,把特定前缀的字符串替换为目标字符串后再进行 interning 操作。
另一个值得一说的是 quote ,我们要区分一下读取时和求值时行为。在读取时,若 reader 遇到了 ' 符号,它会由 'exp 得到 (quote exp) 。 ' 也是一种 read syntax,使用它我们可以少写许多的 quote 和括号。
(consp (read "(quote a)")) => t
(consp (read "'a")) => t
(equal (read "(quote a)") (read "'a")) => t
(eq (cadr (read "(quote a)")) (cadr (read "'a"))) => t在求值时,对于一般的 symbol,eval 会根据它的位置来判断取函数还是取值,如果 symbol 出现在表头,就使用 funtion cell ,若出现在表中则使用 value cell ,例子如下:
(defun a (x) (+ x 1))
(setq a 1)
(defun b (x) (+ x 2))
(setq b 2)
(a a) => 2
(a b) => 3
(b a) => 3
(b b) => 4
那么,如果我们既不想要 value cell 也不想要 function cell 要怎么办呢?这时候就可以使用 (quote obj) ,它等于什么也不做,直接返回 obj 的值。对于 symbol 就是指向 symbol 的指针,对 list 就是 list 头的指针。等等。
(setq a 1)
(eq 'a 'a) => t
(eq 'a a) => nil
对 symbol,list 数据我们必须使用 quote 来标明它们是数据而不是代码,但是其他的数据是自求值的(self-evaluating),它们可以与代码区分,不用 quote :
(eval (read "'a")) => a
(eval (read "'(1 2 3)")) => (1 2 3)
(eval (read "[1 2 3]")) => [1 2 3]
(eval (read "\"123\"")) => "123"
(eval (read "123")) => 123
(eval (read "12.3")) => 12.3
(eval (read "?我")) => 25105 ;; Unicode Value
下面是 quote 的 *Help* buffer 内容。我会在本文的最后一章中对 read 和 quote 的源代码做一些简要分析,以对应下面的文档引用。
quote is a special form in ‘src/eval.c’.
(quote ARG)
Return the argument, without evaluating it. ‘(quote x)’ yields ‘x’.
Warning: ‘quote’ does not construct its return value, but just returns the value that was pre-constructed by the Lisp reader
(see info node ‘(elisp)Printed Representation’).
有了上面内容的铺垫,我们可以较为轻松地完成剩下的部分,即 obarray 的介绍与使用。在 elisp manual 中是这样介绍 obarray 的:
In Emacs Lisp, an obarray is actually a vector. Each element of the vector is a bucket; its value is either an interned symbol whose name hashes to that bucket, or 0 if the bucket is empty. Each interned symbol has an internal link (invisible to the user) to the next symbol in the bucket. Because these links are invisible, there is no way to find all the symbols in an obarray except using mapatoms (below). The order of symbols in a bucket is not significant.
In an empty obarray, every element is 0, so you can create an obarray with (make-vector length 0). This is the only valid way to create an obarray. Prime numbers as lengths tend to result in good hashing; lengths one less than a power of two are also good.
Do not try to put symbols in an obarray yourself. This does not work—only intern can enter a symbol in an obarray properly.
在 elisp 中,obarray 实际上是个向量。其中的每个元素是个桶(哈希桶),桶中的值是 symbol 名字 hash 到该桶的 interned symbol ,如果桶是空的则为 0。每个 interned symbol 有一个指向桶中下一 symbol 的链接(用户不可见),因为这个链接是不可见的,除了使用 mapatoms,用户无法在 obarray 中找到所有的 symbol。桶中 symbol 的顺序并不重要。
在空的 obarray 中所有元素都是 0,你可以通过
(make-vector length 0)来创建一个 obarray。这也是创建 obarray 的唯一合法方法。使用素数长度有助于更好的哈希。二次幂正负一通常也是不错的选择。不要尝试手动添加 symbol 到 obarray 中,这样做是无用的 —— 只有
intern能将 symbol 以合理的方式添加到 obarray 中。
从上面的引文中我们不难得知,elisp 中保存全局 symbol 的方法是拉链式哈希。symbol 的定位发生在由代码到 sexp 的读取阶段,所以也不用太担心执行效率。
obarray 是一个比较大的向量,通过 length 可以查看它的大小,下面是我的 emacs 上得到的结果:
(length obarray) => 15121你可以将 obarray 中的值打印到一个 buffer 中进行观察,不难发现里面有许多个 0。
通过以下代码可以观察其中项为 0 的个数,同样这也是我的 emacs 上的结果:
(cl-loop for i across obarray
sum (if (and (numberp i)
(zerop i))
1 0))
=> 446
使用 mapatoms 我们可以找出 obarray 中的所有 symbol,这也包括那些无法直接从 obarray 中找到的 symbol:
(cl-loop for i across obarray
sum (if (symbolp i) 1 0))
=> 14675
(let ((n 0))
(mapatoms (lambda (x) (cl-incf n)))
n)
=> 55767可见,实际 symbol 数量远大于 obarray 的表面 symbol 数量。
除了 intern mapatoms 函数外,elisp 还提供了一些和 obarray 相关的函数,这里简单介绍一下:
intern-soft,与intern不同,它在 obarray 中存在 symbol 时直接返回 symbol,不存在时直接返回 nil 而非添加新的 symbol。可以使用这个函数来测试 obarray 中是否存在某个 symbol。unintern,从 obarray 中移除 symbol,如果 symbol 不在 obarray 中就什么也不做。如果它删除了某个 symbol,函数会返回 t,否则返回 nil
最后说一点,虽然 symbol-name 返回的是指向 symbol 的 name 成员的指针,但是不建议对它进行修改,文档中是这样说的:虽然修改 symbol-name 是可行的,但是并不会更新 obarray 中的 symbol(也许指根据名字重新计算哈希),所以不要这样做。
(symbol-name 'a) => "a"
(eq (symbol-name 'a) (symbol-name 'a)) => t
;; for interned symbol
(setq a 'hello)
(setq b (symbol-name a))
(symbol-name 'hello) => "hello"
(eq b (symbol-name 'hello)) => t
(aset b 0 ?e)
b => "eello"
(eq b (symbol-name 'hello)) => nil
(eq a 'hello) => nil
a => eello
(symbol-name 'hello) => "hello"
可见,保存在 a 中的 symbol hello 在修改过 symbol name 后和 'hello 不再是同一 symbol 了,后者是新生成的。
至此我们完成了 elisp manual 上 Symbol 一章的介绍,本文的下一节会对 elisp 中 symbol 的 C 实现做一点简单的介绍和分析来作为上文的补充。
现在我们对 emacs 28.1 中与 symbol 相关的代码进行一些简单的介绍和分析,源代码可从这里获取。
这一章主要分为以下内容:
- symbol 结构体分析
- symbol 的创建与管理
- obarray 实现介绍
- read 与 quote 的实现分析
首先我们还是看看 elisp 中各基础类型的 tag bit 值,以下代码来自 lisp.h/line:472:
enum Lisp_Type
{
/* Symbol. XSYMBOL (object) points to a struct Lisp_Symbol. */
Lisp_Symbol = 0,
/* Type 1 is currently unused. */
Lisp_Type_Unused0 = 1,
/* Fixnum. XFIXNUM (obj) is the integer value. */
Lisp_Int0 = 2,
Lisp_Int1 = USE_LSB_TAG ? 6 : 3,
/* String. XSTRING (object) points to a struct Lisp_String.
The length of the string, and its contents, are stored therein. */
Lisp_String = 4,
/* Vector of Lisp objects, or something resembling it.
XVECTOR (object) points to a struct Lisp_Vector, which contains
the size and contents. The size field also contains the type
information, if it's not a real vector object. */
Lisp_Vectorlike = 5,
/* Cons. XCONS (object) points to a struct Lisp_Cons. */
Lisp_Cons = USE_LSB_TAG ? 3 : 6,
/* Must be last entry in Lisp_Type enumeration. */
Lisp_Float = 7
};
elisp 中的对象值是 61 位的地址值加上 3 位的类型值,这也就是为什么它的 fixnum 范围为 #x-2000000000000000 到 #x1fffffffffffffff 的原因,同时这也是浮点数是引用类型的原因,毕竟 61 位放不下 double。
(eq 3.14 3.14) => nil下面是 Lisp_Symbol 的定义,它位于 lisp.h/line:799:
struct Lisp_Symbol
{
union
{
struct
{
bool_bf gcmarkbit : 1;
/* Indicates where the value can be found:
0 : it's a plain var, the value is in the `value' field.
1 : it's a varalias, the value is really in the `alias' symbol.
2 : it's a localized var, the value is in the `blv' object.
3 : it's a forwarding variable, the value is in `forward'. */
ENUM_BF (symbol_redirect) redirect : 3;
/* 0 : normal case, just set the value
1 : constant, cannot set, e.g. nil, t, :keywords.
2 : trap the write, call watcher functions. */
ENUM_BF (symbol_trapped_write) trapped_write : 2;
/* Interned state of the symbol. This is an enumerator from
enum symbol_interned. */
unsigned interned : 2;
/* True means that this variable has been explicitly declared
special (with `defvar' etc), and shouldn't be lexically bound. */
bool_bf declared_special : 1;
/* True if pointed to from purespace and hence can't be GC'd. */
bool_bf pinned : 1;
/* The symbol's name, as a Lisp string. */
Lisp_Object name;
/* Value of the symbol or Qunbound if unbound. Which alternative of the
union is used depends on the `redirect' field above. */
union {
Lisp_Object value;
struct Lisp_Symbol *alias;
struct Lisp_Buffer_Local_Value *blv;
lispfwd fwd;
} val;
/* Function value of the symbol or Qnil if not fboundp. */
Lisp_Object function;
/* The symbol's property list. */
Lisp_Object plist;
/* Next symbol in obarray bucket, if the symbol is interned. */
struct Lisp_Symbol *next;
} s;
GCALIGNED_UNION_MEMBER
} u;
};
verify (GCALIGNED (struct Lisp_Symbol));
Lisp_Symbol 的定义还涉及到其他的一些结构,这里我们就不详细展开了,只是简单介绍一下。在上面的代码中可以看到我们熟悉的 symbol name name , function cell function 和 plist plist ,最下面还有个 next 指针,它应该与 obarray 的拉链哈希有关,对 elisp 用户它是不可见的。
相比 function 和 plist , val 的定义要复杂许多,因为它要适应多种情况。联合体 val 中有四个成员,分别是 value , alias , blv 和 fwd ,具体使用哪个取决于上面的 redirect 字段。 value 就是通常的变量值, alias 是指向别名 symbol 的指针, blv 是 buffer-local 值,最后的 fwd 是 FORWARD 的缩写。根据 504 行处的注释来看 forward 对象指向的是 C 中定义的对象,在 2670 行有一些 Fwd 结构可以参考。
举点简单例子来说的话,我们使用 setq 等函数时设置的就是 value ,使用 defvaralias 定义别名时使用 alias ,使用 buffer-local 变量时使用的是 blv ,使用预定义的变量就是 fwd ,比如 obarray 。
还剩下的一些字段和其他的功能有关, trapped_write 用来记录是否使用变量追踪和是否为常量,用户可以使用 add-variable-watcher , remove-variable-watcher 来控制是否跟踪变量变化。 declared_special 用来判断变量是否总是动态作用域的, interned 用来判断 symbol 是否在 obarray 中,它可以是 SYMBOL_UNINTERNED , SYMBOL_INTERNED 和 SYMBOL_INTERNED_IN_INITIAL_OBARRAY 。若为最后一个则说明它被添加到了全局 obarray 中。
还剩下几个成员我没有说到,不过这些应该足够了。
创建 symbol 自然是使用 make-symbol 了,它的代码位于 alloc.c/line:3613。symbol 的内存管理使用了堆,在为新的 symbol 分配内存前首先观察堆中是否有空余空间,若有则使用,没有则分配新的空间并使用。画个图来说的话大致是这样:

在创建新 symbol 时,emacs 首先检查是否有被释放的空间,若有则直接使用,否则在堆中为 symbol 分配一块空闲空间,若当前的堆满了,则创建一个新的堆并分配内存给 symbol,同时使新堆的 next 指针指向旧堆。
在 make-symbol 中使用了 init_symbol 来对 symbol 进行初始化:
//alloc.c 3596
void
init_symbol (Lisp_Object val, Lisp_Object name)
{
struct Lisp_Symbol *p = XSYMBOL (val);
set_symbol_name (val, name);
set_symbol_plist (val, Qnil);
p->u.s.redirect = SYMBOL_PLAINVAL;
SET_SYMBOL_VAL (p, Qunbound);
set_symbol_function (val, Qnil);
set_symbol_next (val, NULL);
p->u.s.gcmarkbit = false;
p->u.s.interned = SYMBOL_UNINTERNED;
p->u.s.trapped_write = SYMBOL_UNTRAPPED_WRITE;
p->u.s.declared_special = false;
p->u.s.pinned = false;
}
在 C 代码中想要对 symbol 成员进行访问直接使用结构提供的各成员即可,不过 elisp 也提供了像是 symbol-name , symbol-function 和 symbol-value 的函数,它们的定义分别位于:
symbol-name,data.c/line:745symbol-value,data.c/line:1444symbol-function,data.c/line:729symbol-plist,data.c/737
其他诸如 boundp , fboundp , makunbound , fmakunbound 等的定义均位于 data.c 中,应该很容易搜索到,这里就不张贴代码了。
这里说的 obarray 就是默认的全局 obarray。它的定义位于 lread.c 的 5140 行。emacs 在启动时会在 emacs.c 中执行 init_obarray_once 函数来进行初始化。在它的上面几行可以找到 OBARRAY_SIZE 常数,它的值是 15121,与上文中我从 elisp 中得到的值一致。
这一节剩下的内容主要就是 obarray 管理的实现。 intern 内部会调用一个叫做 intern_driver 的函数,而 intern_driver 会调用 intern_sym ,它的定义位于 lread.c 的 4356 行。代码如下:
/* Intern symbol SYM in OBARRAY using bucket INDEX. */
// lraed.c 4356
static Lisp_Object
intern_sym (Lisp_Object sym, Lisp_Object obarray, Lisp_Object index)
{
Lisp_Object *ptr;
XSYMBOL (sym)->u.s.interned = (EQ (obarray, initial_obarray)
? SYMBOL_INTERNED_IN_INITIAL_OBARRAY
: SYMBOL_INTERNED);
if (SREF (SYMBOL_NAME (sym), 0) == ':' && EQ (obarray, initial_obarray))
{
make_symbol_constant (sym);
XSYMBOL (sym)->u.s.redirect = SYMBOL_PLAINVAL;
/* Mark keywords as special. This makes (let ((:key 'foo)) ...)
in lexically bound elisp signal an error, as documented. */
XSYMBOL (sym)->u.s.declared_special = true;
SET_SYMBOL_VAL (XSYMBOL (sym), sym);
}
ptr = aref_addr (obarray, XFIXNUM (index));
set_symbol_next (sym, SYMBOLP (*ptr) ? XSYMBOL (*ptr) : NULL);
*ptr = sym;
return sym;
}
可见其中对 keyword 做了特殊处理,且在添加 symbol 时会是新增 symbol 的 next 指针指向 bucket 中的 symbol。如果 symbol 被添加到全局 obarray 中,symbol 的 interned 成员值会是 SYMBOL_INTERNED_IN_INITIAL_OBARRAY 。
在 intern 的实现中会调用 oblookup_considering_shorthand 来查找 obarray 中是否已存在某个 symbol,而它又会调用 oblookup 函数,它们两靠的很近,大概在 lread.c 的 4650 行。由于我不是太关心 shorthands 相关功能,这里我只给出 oblookup 的具体内容:
/* Return the symbol in OBARRAY whose names matches the string
of SIZE characters (SIZE_BYTE bytes) at PTR.
If there is no such symbol, return the integer bucket number of
where the symbol would be if it were present.
Also store the bucket number in oblookup_last_bucket_number. */
//lraed.c 4610
Lisp_Object
oblookup (Lisp_Object obarray, register const char *ptr, ptrdiff_t size, ptrdiff_t size_byte)
{
size_t hash;
size_t obsize;
register Lisp_Object tail;
Lisp_Object bucket, tem;
obarray = check_obarray (obarray);
/* This is sometimes needed in the middle of GC. */
obsize = gc_asize (obarray);
hash = hash_string (ptr, size_byte) % obsize;
bucket = AREF (obarray, hash);
oblookup_last_bucket_number = hash;
if (EQ (bucket, make_fixnum (0)))
;
else if (!SYMBOLP (bucket))
error ("Bad data in guts of obarray"); /* Like CADR error message. */
else
for (tail = bucket; ; XSETSYMBOL (tail, XSYMBOL (tail)->u.s.next))
{
if (SBYTES (SYMBOL_NAME (tail)) == size_byte
&& SCHARS (SYMBOL_NAME (tail)) == size
&& !memcmp (SDATA (SYMBOL_NAME (tail)), ptr, size_byte))
return tail;
else if (XSYMBOL (tail)->u.s.next == 0)
break;
}
XSETINT (tem, hash);
return tem;
}
可见其先使用 hash_string 计算 symbol 名的哈希值后再索引得到对应的桶,随后在 symbol 链表中进行查找。
obarray 中使用的哈希函数实现如下:
//lisp.h 2437
INLINE EMACS_UINT
sxhash_combine (EMACS_UINT x, EMACS_UINT y)
{
return (x << 4) + (x >> (EMACS_INT_WIDTH - 4)) + y;
}
//fns.c 4722
EMACS_UINT
hash_string (char const *ptr, ptrdiff_t len)
{
char const *p = ptr;
char const *end = ptr + len;
EMACS_UINT hash = len;
/* At most 8 steps. We could reuse SXHASH_MAX_LEN, of course,
* but dividing by 8 is cheaper. */
ptrdiff_t step = sizeof hash + ((end - p) >> 3);
while (p + sizeof hash <= end)
{
EMACS_UINT c;
/* We presume that the compiler will replace this `memcpy` with
a single load/move instruction when applicable. */
memcpy (&c, p, sizeof hash);
p += step;
hash = sxhash_combine (hash, c);
}
/* A few last bytes may remain (smaller than an EMACS_UINT). */
/* FIXME: We could do this without a loop, but it'd require
endian-dependent code :-( */
while (p < end)
{
unsigned char c = *p++;
hash = sxhash_combine (hash, c);
}
return hash;
}这应该是个比较简单的哈希函数。在 emacs 的哈希表中也有使用。
剩下的一些函数比如 intern-soft , unintern 和 mapatoms 都可以在 lread.c 中找到,这里就不进一步说明了
。
具体的 read 操作由位于 lraed.c 2978 的 raed1 函数完成,它是一个非常大的函数,大约有一千行。在函数 body 内搜索 intern 可以对它的行为进行具体的观察,这里就不做说明了。
另外介绍一下 quote ,严格来说它和本文没有太大关系,这里我只是很好奇它的实现:
// eval.c 529
DEFUN ("quote", Fquote, Squote, 1, UNEVALLED, 0,
doc: /* Return the argument, without evaluating it. `(quote x)' yields `x'.
Warning: `quote' does not construct its return value, but just returns
the value that was pre-constructed by the Lisp reader (see info node
`(elisp)Printed Representation').
This means that \\='(a . b) is not identical to (cons \\='a \\='b): the former
does not cons. Quoting should be reserved for constants that will
never be modified by side-effects, unless you like self-modifying code.
See the common pitfall in info node `(elisp)Rearrangement' for an example
of unexpected results when a quoted object is modified.
usage: (quote ARG) */)
(Lisp_Object args)
{
if (!NILP (XCDR (args)))
xsignal2 (Qwrong_number_of_arguments, Qquote, Flength (args));
return XCAR (args);
}果真就是什么也不做直接返回…
写完后我看了一眼文件最初的创建时间,好家伙 ,写完都差不多是一年后了。不过拖这么久也不是没有好处,一来 22 年 4 月出的 emacs 28 添加了不少新功能,二来这一年我也学习了不少 elisp 知识,如果过早开始的话其中的一些细节就了解的不是很清楚了。
日常使用中我们是不需要了解 obarray 这种实现细节的,不过了解一下也没什么坏处。在学习 Scheme 时我甚至完全没有感觉 symbol 是一种指针类型,由于没有对 value 和 function 进行区分,Scheme 中的 symbol 比较简单,rnrs 中对于 symbol 也是一笔带过(r5rs 中甚至不到一页)。
写这文章的时候我正在听 https://www.bilibili.com/video/BV1SK4y1o7WV。 话说今天伊丽莎白女王挂了,不管是喜是悲,怎么说也给我的文章增添了一点纪念意义(笑)。

R.I.P.
就这样。