参考维基百科【2】,宏的定义如下:
在计算机科学中, 宏 (macro,macroinstruction)是一种规则或模式,用于指定如何将某个输出序列(通常是字符序列)根据定义的过程来映射到替换输出序列(通常也是字符序列)。将宏实例化为特定序列的映射过程称为宏展开(macro expansion)。
宏被用来将一连串的计算机指令作为一条程序语句提供给程序员,使编程任务不那么琐碎(这也就是为什么它们被叫做“宏”,因为一 大 块代码可以使用一小 串 字符序列通过展开得到)
维基百科上的分类略有些繁杂,有键盘宏,脚本宏,参数宏,过程宏,词法宏等等。这里采用参考资料【3】的分类方法,根据是否使用模式匹配将宏分为过程宏和高级宏,根据宏的卫生性将宏分为卫生宏(hygienic macro)和非卫生宏。
过程宏,根据【3】的定义,类似于一个普通的函数,输入一个表达式并输出一个表达式,比如交换两个变量的值,在 C 中使用宏可以这样做:(这里当然可以用 do while(0) )
#define SWAP(x, y) \
{ \
int a = x; \
x = y; \
y = a; \
}
SWAP(a1 ,a2) =>
{int a = a1; a1 = a2; a2 = a;}在 scheme 中可以这样做:
(define-syntax SWAP
(syntax-rules()
[(_ x y)
(let ([a x])
(set! x y)
(set! y a))]))
(SWAP a1 a2) =>
(let ([a a1])
(set! a1 a2)
(set! a2 a))从上面这个例子是体现不出 scheme 宏的高级性的。高级宏的强大之处体现在模式匹配上。模式匹配从更高的层次描述输入与输出的关系,通过使用模式匹配,一个表达式可以变换成另一个表达式而不是直接输出。
假设我们现在需要一个与宏,它可以对一个或多个参数进行逻辑与操作,若参数个数为 0,则输出真。以我目前的 C 语言水平貌似做不到这一点。看看在 Scheme 中如何完成这个任务:
(define-syntax AND
(syntax-rules()
[(_) #t]
[(_ e1) e1]
[(_ e1 e2 e3 ...)
(if e1 (and e2 e3 ...) #f)]))通过模式匹配,这个宏可以轻松应对不同参数的情况。在这个宏中还用到了宏的递归展开,而这在 C 的宏中是难以想象的(或者说是我难以想象的)。
卫生和非卫生的本质问题是作用域问题 —— 摘自参考资料【3】
卫生宏的展开保证不会出现意外的标识符捕获。它的好处在于,一旦宏的定义完成,那么宏展开的结果就已经是可以确定的了,它的展开结果不会随调用地点的改变而改变,这与静态作用域的特点非常相似。
宏有宏定义阶段和宏展开阶段,卫生宏弄清了哪些符号对应于宏定义阶段,哪些符号对应于宏展开阶段。如果宏是卫生的,它就具有“引用透明性”,定义阶段确定的符号意义不会在展开阶段出现意外的绑定。非卫生宏只是进行表达式的直接替换,而卫生宏需要理解语义,理解每个符号所处的环境。
还是以上面的变量交换代码来作为例子,如果我使用变量 a, b 调用 C 的宏,展开结果如下:
SWAP(a, b) => {int a = a; a = b; b = a;}
很明显,上面的代码是有问题的, int a = a 不是一个良好的定义语句,原本应作为临时变量的 a 与作为宏参数的 a 重名了。
要想解决这个问题,可以把临时变量的名字修改成更加复杂和不常见的名字。但是这只能降低重名的风险,而不是彻底解决掉这个隐患。
那么,上面的 scheme 宏是否存在这个问题呢?在 chez-scheme 中使用 expand 过程来观察宏展开,你会得到类似如下的结果:
(expand '(SWAP a b))
=>
(let ([#{a a36te8sjq7qytr0trgpami01o44cyl9c-0} a])
(set! a b)
(set! b #{a a36te8sjq7qytr0trgpami01o44cyl9c-0}))出现在 let 中的变量并不是 a,而是另一个变量,它的名字与宏参数 a 不同,因此不存在名字碰撞的问题。
以下内容参考的标准是 The Scheme Programming Language 章节 Syntax Extension 中描述的 \(r^6rs\) ,虽然现在(2020 年) \(r^7rs\) small 早已发布(2013 年),但两者的差别并不是很大。本小节的部分内容也参考了 \(r^7rs\) 。
语法扩展被用来简化和常规化在变成中重复出现的模式。
语法扩展通常使用 (keyword subform ...) 的形式, keyword 是命名语法扩展的标识符。它也可以是不完全表的形式(improper lists),甚至是单个标识符。
将关键字与转换过程(或者叫转换器 (transformer))关联起来就可以创建新的语法扩展。定义语法扩展需要使用 define-syntax , let-syntax 或 letrec-syntax 。可以使用 syntax-rules 来创建转换器,它允许进行简单的基于模式的转换。
在开始求值时(在编译或解释之前),语法扩展会被语法展开器(expander)转换成基本形式。如果展开器遇到了语法扩展,它会调用与之关联的转换器来展开该语法扩展,并重复对转换器返回的对象进行展开。
与 C 不同的是,Scheme 的语法扩展的作用对象是表达式树,而不是单纯的字符替换,这一点可以由下图说明:(图片来源: Essentials of Programming Language )
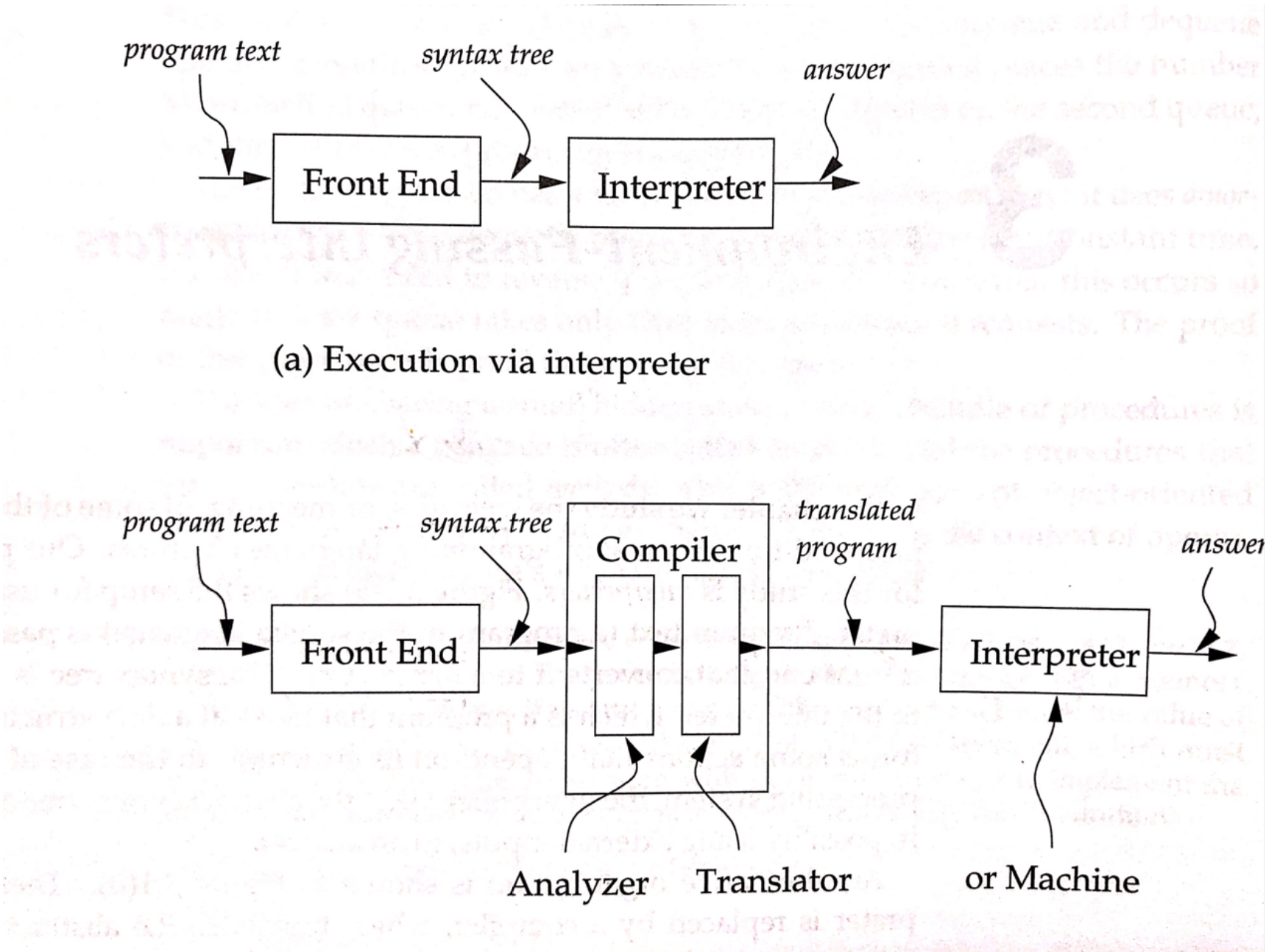
C 语言的宏替换作用对象是 program text,即程序文本。而 Scheme 宏作用对象是 syntax tree,即语法树。
要建立关键字与转换器之间的关联,可以使用 define-syntax=,=let-syntax 或 letrec-syntax=。=define-syntax 可用于 top-level,另外两个可用于局部。
define-syntax 的语法如下:
(define-syntax keyword expr)其中, expr 必须是一个转换器。
内部定义所建立的绑定,不论是关键字还是变量,它们在它们被定义的作用域中是处处可见的,这也包括它们自己,例如:
(let ()
(define even?
(lambda (x)
(or (= x 0) (odd? (- x 1)))))
(define-syntax odd?
(syntax-rules ()
[(_ x) (not (even? x))]))
(even? 10))两者的语法如下:
(let-syntax ([keyword expr] ...) form1 form2 ...)
(letrec-syntax ([keyword expr] ...) form1 form2 ...)每个 expr 必须是一个转换器。它们与 let 和 letrec 的行为是很相似,可以说是它们的关键字定义版本。
它们的区别可以通过以下例子来说明:
(let ([f (lambda (x) (+ x 1))])
(let-syntax ([f (syntax-rules ()
[(_ x) x])]
[g (syntax-rules ()
[(_ x) (f x)])])
(list (f 1) (g 1))))
(let ([f (lambda (x) (+ x 1))])
(letrec-syntax ([f (syntax-rules ()
[(_ x) x])]
[g (syntax-rules ()
[(_ x) (f x)])])
(list (f 1) (g 1))))它的语法如下:
(syntax-rules (literal ...) clause ...)literal 必须是除了下划线(_)和省略号之外(…)的标识符。
clause 必须是 (pattern template) 的形式。
pattern 必须指定一个输入可能使用的语法,与之对应的 template 指定输出形状。
Pattern 由表结构,向量结构,标识符和常量组成。Pattern 中的标识符可以是字面量(literal),模式变量(pattern variable),下划线,或省略号。除了 _, ... ,出现在 (literal ...) 中的标识符都是 literal,否则就是模式变量。literal 的作用是作为辅助关键字,比如 cond 和 case 中的 else。Pattern 中的表和向量制定了输出所要求的基本结构,下划线和模式变量用于指定任意的子结构,下划线是被定义的关键字的一个别名。literal 和常量指定必须准确匹配的部分。省略号用于指定它跟随的子模式的重复出现。
syntax-rules Pattern 的最外层必须是表结构,且该表结构的第一个元素会被忽略,因为它总被认为是语法形式的关键字名。
如果输入形式与一个给定的 clause 的 pattern 能够匹配,这个形式会被转换为对应的模板(template)。随着转换的开始,出现在 pattern 中的模式变量会与对应的输入子形式进行绑定。
模板可以是一个模式变量,一个不是模板变量的标识符,一个模式数据,一个子模版组成的表,一个子模版组成的不完全表,或是一个子模版组成的向量。
出现在模板中的模式变量会被替换成它们绑定的子形式。不是模式变量的数据和标识符会直接插入到输出中。跟着 … 的子模版会展开成 0 个或多个子模版(此时,子模版必须包含至少一个后面跟着省略号的模式变量,否则展开器无法确定对应的展开的次数,因为不能找到对应的模式变量)。
(... template) 形式的模板与 template 是等价的,除非模板中的省略号没有什么特殊含义。也就是说,模板中的省略号被当作普通标识符。特别地, (... ...) 会产生 ... ,这也就允许语法扩展来展开得到含有省略号的形式。
关于 syntax-rules 宏的一些例子这里就不列举了,参考资料【5】中的 \(r^7rs\) 的的第七节 Formal syntax and semantics 中有很多通俗易懂的例子。
展开器的处理顺序是从左到右的。如果展开器遇到了一个变量定义,它会记录下这个定义的标识符是一个变量,并在所有定义被处理之前抑制右边表达式的展开。如果它遇到了关键字绑定,它会对右边表达式进行展开并求值,并将转换器与关键字绑定。如果它遇到了一个表达式,它会展开所有被抑制的右边表达式,以及当前和剩余的表达式。
这里说的右边表达式是表达式的右边部分的表达式,例如 (define a 1) ,这个变量定义的右边表达式就是 1。例如 (+ 1 12 3) ,这个表达式的右边表达式就是 1,12,3。
需要与右边表达式(left-hand-expression)区分的是从左到右的执行顺序(from left to right),前者是指一个表达式中的靠右边的表达式,后者的意思是以从左到右的顺序 执行 表达式序列,比如:
(begin
(display a)
(dispaly b)
(dispaly c)
)
这里先不论 display 这个东西是不是宏(实际上在 scheme 中它是个标准过程),展开器的求值顺序就是从上到下进行顺序求值。
这段话描述了几种情况,分别是变量定义,关键字定义和表达式三者的展开。可以用几个例子来加深理解。
在 REPL 中,当我们输入一个表达式后,它会被立即求值,这样很难体现出展开器的行为。在下面的代码中,我会使用以 begin 开头的代码块。
第一点,如果展开器遇到了变量定义,它会在关键字定义完成前或是代码块结束前抑制变量右边表达式的求值,这一点可以通过以下代码体现出来:
(begin
(define a (wocao 1))
(define-syntax wocao
(syntax-rules ()
[(_ a) (+ a 1)]))
a)上面的表达式求值结果为 2,如果你将宏定义和变量定义的顺序颠倒过来,结果依然是 2。这也就体现出了“对于变量定义,在所有其他定义被处理之前,抑制变量定义右边表达式的展开和求值”。
第二点,如果遇到了关键字定义,它会对右边表达式进行展开和求值,并将值与关键字绑定。这一点保证了宏的定义是在过程的定义之前完成的。
第三点,遇到表达式后,展开器会展开所有被抑制的右边表达式,以及当前和剩余的表达式。在表达式求值开始前,所有的变量定义会完成。
最后一点,展开器的处理顺序是从左到右的,这也就是说表达式的求值会在定义之后。
(let ()
(define-syntax bind-to-zero
(syntax-rules ()
[(_ id) (define id 0)]))
(bind-to-zero x)
x)上面表达式求值结果就是 0,与外面是否定义了 bind-to-zero 无关,这一点是由求值顺序保证的。
对于 syntax-rules(), The Scheme Programming Language 上面是这样描述的:While it is much less expressive than syntax-case, it is sufficient for defining many common syntactic extension。也就是说,它的表达能力是远弱于 syntax-case 的。syntax-case 在 r6rs 是标准实现所要求的,但是在 r7rs small 中被废除了,因为实现复杂。
关于 syntax-case 的教程与一些简单的理解,我可能(时间所限,很可能不)会在之后花点时间来表达一下我浅薄的理解。这里有两篇文章,可以借鉴借鉴;
若发现了本文中的错误,欢迎指出。
【1】 为什么Lisp语言如此先进?(译文): https://www.ruanyifeng.com/blog/2010/10/why_lisp_is_superior.html
【2】 Macro (computer science) From Wikipedia, the free encyclopedia: https://en.wikipedia.org/wiki/Macro_(computer_science)
【3】 scheme 卫生宏实现介绍: http://www.zenlife.tk/scheme-hygiene-macro.md
【4】 The Scheme Programming Language , R.Kent Dybvig
【5】 r7rs org: https://small.r7rs.org